Core Principles of Coding Agents: How Perception and Context Engineering Determine AI Coding Effectiveness
Perception and context engineering—not the model itself—determine coding Agent effectiveness.
This article explains why AI coding tools using the same model produce vastly different results. The key lies in two capabilities: perception (the Agent's ability to understand your project before writing code) and context engineering (precisely selecting what information enters the model's limited context window). Through practical examples and technical frameworks like ReAct, it shows how good Agents explore incrementally rather than stuffing everything in at once.
Why the Same Model Produces Vastly Different Results
When it comes to AI writing code, some tools fix bugs quickly and accurately, while others start writing nonsense that fills your screen with errors the moment you put it into a project. Many people assume this gap comes from model strength, but what truly creates the difference isn't the model itself—it's two things that happen before it starts writing: perception and context engineering.
Put simply, it's whether the coding Agent actually understands your project before it starts working.
The evolution of AI coding tools is fundamentally the evolution of the "interface" between the tool and real engineering environments. The first segment of that interface is how the Agent sees the environment and decides which information to load into its working memory. Many tools use the same underlying model yet produce vastly different results—the deep reason lies in perception and context engineering.


Perception: Opening Eyes Before Writing Code
The Agent's First Step Isn't Writing Code
Many people assume a coding Agent's first step after receiving a task is to write code. It's not. Its real first step is figuring out where it currently is.
For a coding Agent, the environment is your current code project, and it needs to orient itself first. Like confirming coordinates before going into battle—a model without real environment information is essentially a gunner shooting with eyes closed. It might be a great shot, but it has no idea where to aim.
This corresponds to the classic Perceive-Plan-Act cycle in Agent system design. In both academic and industrial Agent architectures, the perception module is always the first link in the entire decision chain. Without perception, subsequent planning is castles in the air—the model cannot reason based on real state and can only rely on statistical patterns from training data to "guess," and guessing results in specific engineering projects will almost inevitably deviate from reality. This is why even with identical underlying LLM capabilities, different Agent frameworks can show orders-of-magnitude differences in performance.
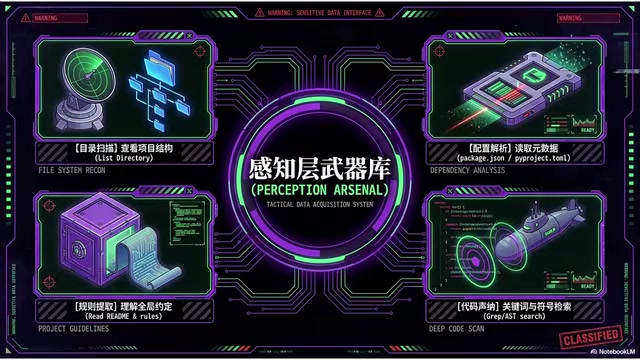
What Perception Needs to See
The Agent needs to answer several fundamental questions one by one:
- Project structure: What folders are in the root directory, where's the entry point
- Tech stack: Is the frontend React or Vue, is the backend Express or FastAPI
- How to run: What are the test commands and build commands
- Dependency management: Is the package manager npm, pnpm, uv, or cargo
- Rule files: Are there project-level rule files like
CLAUDE.md,agents.md, or.cursorrules
Only after confirming each of these does it truly stand inside your project.
The Cost of Skipping Perception: Hallucinations and Broken Code
Here's an example: you ask the Agent to add a login feature to your project. If it doesn't look at the environment—doesn't know whether you're using React or Vue, doesn't know which layer handles authentication logic, doesn't know how the database is accessed—the code it writes might be syntactically flawless, but the moment you put it in the project, you get 404 endpoints, dependency conflicts, and reference errors.
This is classic AI hallucination—it's not stupid, it just fired without looking.
From a technical perspective, LLM hallucination is essentially the result of a model completing outputs based on high-frequency patterns in training corpora when it lacks grounding information (anchor information aligned with the real world). The model has seen thousands of login feature implementations and will output the statistically most "reasonable" version—but "statistically reasonable" and "actually works in your project" are two different things. The role of perception is precisely to provide grounding: pulling the model's output from "generally reasonable" back to "correct within this project." Generation without grounding is essentially high-confidence error.
Tool Calls That Enable Perception
At the tool-call level, perception relies on these key weapons:
- Directory listing tools: See the entire project structure
- Config file reading: Read
package.jsonorpyproject.tomlto know dependencies and script commands - Rule file reading: Understand team conventions
- Code search tools: Locate relevant files by keyword, reference existing similar components and interfaces
These actions correspond to a core concept in general Agent technology—Perception—which is the prerequisite for whether a task can even begin.
Context Engineering: Precise Selection Under a Limited Token Budget
Why You Can't Just Stuff the Entire Project In
At this point someone will inevitably say: if perception is so complicated, why not just feed the entire project's code to the model so it sees everything?
The answer is you can't, and it will cause serious problems. Full input leads to "buffer overflow"—dumping everything in looks comprehensive but actually means biting off more than you can chew.
Three hard constraints, each more critical than the last:
- Limited context window: Even if a model claims millions of tokens, a real medium-to-large project easily has hundreds of thousands or millions of lines of code—it simply won't fit
Even the most cutting-edge models of 2024-2025 (like Gemini's million-token window or Claude's 200K window) struggle with a medium-sized enterprise project. A typical mid-size backend project might have 50,000-100,000 lines of code, easily exceeding a million tokens with dependencies and config files. More critically, the attention computation complexity of Transformer architecture scales quadratically with sequence length (standard self-attention is O(n²)). While various sparse attention and linear attention approaches are mitigating this, the computational cost and latency of ultra-long contexts remain hard constraints in practice.
-
Cost and speed: The longer the context, the more expensive and slower each call becomes
-
Lost in the Middle (the most fatal): The more information there is, the more the model's attention gets diluted—key points get buried in irrelevant code, and it loses its bearings
This phenomenon is known in academia as the "Lost in the Middle" effect, systematically revealed by Stanford and other institutions in 2023 research. Experiments show that when critical information is placed in the middle of a long context, the model's retrieval and utilization ability drops significantly—models tend to better utilize information at the beginning and end while allocating noticeably less attention to the middle. This means even if you've stuffed the correct answer into the context, if it's surrounded by large amounts of irrelevant code, the model will likely "turn a blind eye." This isn't a model bug—it's a structural limitation of current attention mechanisms.
The Core Definition of Context Engineering
Context engineering can be explained in one sentence: Before each model call, deciding exactly what content to assemble into the prompt.
Its essence is a selection problem with a budget—maximizing the density of task-relevant information under a limited total token count. Remember: what you decide enters the model essentially determines its output.
This concept has been repeatedly emphasized by engineering teams at companies like Anthropic, marking an important shift in industry thinking: upgrading from "prompt engineering" (how to phrase questions) to "context engineering" (how to systematically manage the model's input information flow). The former focuses on wording techniques for single interactions; the latter focuses on the architectural design of the entire information pipeline—including when to acquire information, which information to acquire, how to compress and organize it, and when to discard outdated information.
Five Dimensions of Context Allocation
The budget is only so many tokens, and it needs to be allocated across five areas:
| Dimension | Strategy |
|---|---|
| File selection | Task-relevant files go in, irrelevant ones stay out |
| Snippet selection | For large files, extract only relevant functions and classes |
| Conversation history | Decide how many rounds to keep, whether to summarize |
| Rule files | Selectively include project conventions |
| Tool call results | Recently searched filenames, error messages, etc. |
Practical Comparison: Behavioral Differences Between Good and Bad Agents
Same Problem, Two Approaches
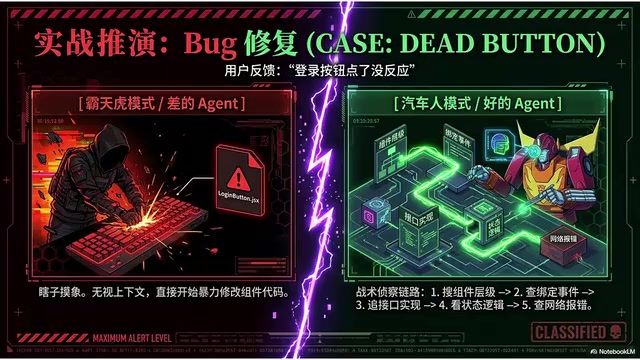
A user drops one sentence: "The login button doesn't respond when clicked."
Bad Agent (brute force mode): Without looking at anything, it directly interprets "button not responding" as a button component issue and starts hammering away at LoginButton.
Good Agent (detective mode):
- First searches where
LoginButtonappears across files, maps out the component hierarchy - Checks what event the button is bound to and where the handler function lives
- Traces which API the function calls and where that API is implemented
- Checks for loading states and error handling
- Looks at the console for errors—is the network request returning 404 or 500
- Glances at tests if the project has them
Incremental Exploration, Not One-Shot Stuffing
A good coding Agent doesn't stuff all information into the context at once. It centers on the task and explores outward in expanding circles, phase by phase, acquiring incrementally and keeping only the most critical pieces in working memory.
This is what context engineering actually does—dynamically constructing a field of view relevant to the current task, ensuring the model sees exactly what it needs at each step without being distracted by irrelevant information. Like radar continuously scanning and focusing.
This working pattern technically corresponds to the ReAct (Reasoning + Acting) framework and its variants. Proposed by Google and Princeton in 2022, ReAct's core idea is to have LLMs alternate between "thinking" and "acting": the model first reasons about what information it currently needs, then calls tools to obtain it, then continues reasoning about the next step based on new information. This is fundamentally different from the traditional "one-shot input, one-shot output" mode. In coding Agent scenarios, this means the Agent forms a dynamic exploration chain—each tool call's results influence the next decision direction, and context is continuously reorganized and updated throughout the process. This multi-step interaction pattern enables Agents to handle complex tasks far exceeding single context window capacity.
Two Forms of Perception and Context Engineering in Products
These two capabilities manifest in products in two forms:
Explicit perception (terminal Agents like Claude Code, Codex CLI): You can directly see which tool calls it made, what it searched, which files it read, and which snippets it retained—the entire process is transparent.
Implicit perception (IDE Agents like Cursor): They inherently know which file you currently have open, which section you've selected, where your cursor is, and what you just changed—these are all signals the IDE provides for free.
The technical architecture differences behind these two forms are worth understanding deeply. Terminal Agents (like Claude Code) run in a relatively "information-poor" environment—they must actively acquire every piece of information through tool calls, making their perception process explicit and auditable. IDE Agents run in an "information-rich" environment—the IDE itself is a powerful code understanding engine maintaining AST (Abstract Syntax Tree), symbol indices, type information, Git history, and other structured data. IDE Agents can directly leverage this pre-computed structured information as context without re-parsing from raw text. This is why Cursor can "know the context when you select a piece of code"—it's not magic; the IDE's Language Server Protocol (LSP) and syntax analyzers have already done extensive perception work. Each form has its strengths: explicit perception is more transparent and controllable, suited for complex cross-file refactoring; implicit perception is more fluid and natural, suited for everyday local edits.
The gap between different tools often lies right here: same model, but how thorough the perception is and how accurate the context selection is makes a huge difference.
Five Practical Principles for Improving Coding Agent Effectiveness
Finally, here are five principles you can apply immediately:
- Relevance over comprehensiveness: Better to have less but precise information than to pile up so much that key points get diluted
- Structured information is worth more than raw text: A Git diff, a symbol definition, or a call graph is far more efficient than a block of unfiltered source code
- Rule files are the best vehicle for long-term context: Write once, reuse every time—far more reliable than repeating input every conversation
- Context can be compressed but must not lose critical state: Early details can be replaced with summaries, but current TODOs, key decisions, and unresolved errors must stay
- Context engineering is continuous: Every tool run, every piece of feedback received, the context is being reorganized
Point 3 deserves extra elaboration: rule files (like CLAUDE.md, .cursorrules) are essentially persistent system prompts. They solve a fundamental problem—LLMs have no cross-session memory. Every time a new conversation starts, the model knows nothing about your project. Rule files are equivalent to crystallizing the project's "meta-knowledge" (coding standards, architectural decisions, technology choice rationale, common pitfalls), allowing the Agent to quickly load this long-term valid context at every startup rather than exploring from scratch each time. This is currently the lowest-cost, highest-return context engineering practice.
Summary
Perception is the Agent's ability to actively observe the environment, determining whether a task can begin; context engineering is the ability to selectively load perceived information into the model, determining whether a task can be done well.
The model determines the ceiling; context engineering determines the floor. A truly good coding Agent has typically nailed context engineering rather than blindly scaling parameters.
From a broader perspective, this conclusion reflects a universal pattern in the AI application layer: in an era where foundation model capabilities are converging toward homogeneity, systems engineering (not the model itself) is becoming the core battleground for product differentiation. Context engineering, tool design, feedback loops, error recovery mechanisms—these engineering capabilities "beyond the model" determine how much practical value the same model can deliver across different products. This is also why we're seeing more and more AI companies shifting their focus from "training bigger models" to "building better systems."
Related articles
AI Aggregator Platforms Tested: A Complete Guide to Using GPT 5.5 and Other Top Models for Free
A hands-on guide to using GPT 5.5, Gemini 3.1 Pro, and Grok 4.2 for free via AI aggregator platforms, covering cross-model context memory, account pool mechanisms, and key security risks.
Vibe Coding in Practice: A Junior Student Uses Cursor to Build a Multi-Agent System with 51 AI Officials Based on the Three Departments and Six Ministries Framework
A junior student uses Cursor and Vibe Coding to build a multi-agent system with 51 AI officials modeled on China's Three Departments and Six Ministries, featuring task distribution, approval workflows, and Token cost visualization.
How to Connect Codex to DeepSeek Models: Free Switching via CC Switch
Learn how to connect OpenAI Codex to DeepSeek models via CC Switch, enabling free switching between DeepSeek and GPT with complete setup and routing guide.