CrewAI Multi-Agent Collaboration in Practice: A Complete Guide from Setup to API Service
Complete guide to building multi-Agent collaboration systems with CrewAI and FastAPI, with model comparison.
This article provides a comprehensive walkthrough of building a multi-Agent collaboration system using CrewAI and FastAPI. It covers CrewAI's four core concepts (Agent, Task, Process, Crew/Pipeline), demonstrates a research report generation system, and compares GPT-4o Mini, Qwen Max, and Llama 3.1 performance in multi-Agent scenarios, offering practical model selection and deployment recommendations.
What Is CrewAI? Why Do We Need Multi-Agent Collaboration?
In AI application development, a single Agent often struggles to handle complex tasks. CrewAI is an open-source framework specifically designed for multi-Agent collaboration, enabling multiple Agents with different roles and goals to work together—decomposing complex tasks, distributing them, and ultimately achieving the overall objective.
The concept of Multi-Agent Systems (MAS) originally emerged from the field of distributed artificial intelligence. Its core idea is to solve complex problems that a single entity cannot handle through the collaboration of multiple autonomous entities. In the era of large language models, while a single Agent possesses powerful text generation and reasoning capabilities, it often encounters issues like context window overflow, role confusion, and degraded output quality when facing tasks that require multi-step, multi-perspective, and multi-domain knowledge collaboration. Multi-Agent collaboration frameworks address this by decomposing complex tasks into subtasks handled by Agents with different specializations. This not only improves output quality but also achieves separation of concerns, allowing each Agent to focus on its area of expertise. Beyond CrewAI, similar frameworks include AutoGen (Microsoft) and LangGraph (LangChain ecosystem), each with different emphases but sharing the same core philosophy.
This article walks you through a complete hands-on example of building a multi-Agent collaboration application using CrewAI + FastAPI and exposing it as an API service. We'll also test the real-world performance of three large models—GPT-4o Mini, Qwen Max, and local Llama 3.1—in multi-Agent scenarios.
The Four Core Concepts of CrewAI
Agent: Specialized Team Members
An Agent is an autonomous, controllable unit in CrewAI, analogous to a team member with specific skills. Each Agent has three key attributes:
- Role: The Agent's functional position within the team
- Goal: The specific objective the Agent needs to achieve
- Backstory: Contextual information that helps the Agent better understand its positioning
Under the hood, these three attributes are combined into a System Prompt sent to the large model, guiding it to process tasks from a specific identity and perspective. The backstory design is particularly critical—a well-crafted Backstory can significantly improve an Agent's output quality because it provides rich role context for the model, similar to the "role-playing" technique in prompt engineering.
Task: Specific Assignments for Agents
A Task defines all the details needed for execution, including task description, assigned Agent, expected output format, available tools list, and more. A key feature is that Tasks support context passing—the output of one Task can serve as input for the next Task, forming a task chain.
This task chain mechanism essentially implements an "information pipeline": each Task's output is serialized as text and injected into the next Task's prompt context. This means downstream Agents can not only see the results of preceding tasks but also perform further analysis and processing based on those results, achieving true collaboration rather than simple task concatenation.
Process: The Project Manager for Task Coordination
Process is responsible for coordinating Agent task execution and currently supports two mechanisms:
- Sequential Process: Executes tasks one by one in a predetermined order, with each task's output serving as context for the next
- Hierarchical Process: Designates a manager Agent that dynamically assigns tasks based on each Agent's capabilities and reviews outputs
Sequential processes are suitable for scenarios with clear task dependencies—they're simple to implement and produce predictable results. Hierarchical processes more closely resemble how real teams work—the manager Agent evaluates task requirements, assigns subtasks to the most suitable Agents, reviews output quality, and requests revisions when necessary. Hierarchical processes place extremely high demands on the manager Agent's reasoning capabilities, typically requiring GPT-4 level models.
Crew and Pipeline: Organization and Workflow
A Crew represents a collection of Agents collaborating to complete tasks, defining the task execution strategy and overall workflow. A Pipeline allows multiple Crews to execute sequentially or in parallel, building more complex multi-stage workflows.
The introduction of Pipelines enables CrewAI to handle enterprise-level complex business processes. For example, a content production Pipeline might include: the first Crew handling market research and topic selection, the second Crew handling content creation and editing, and the third Crew handling SEO optimization and publishing. Each Crew has its own internal Agent collaboration logic, while Crews are connected through the Pipeline, forming an end-to-end automated workflow.
Hands-On: Building a Research Report Generation System with CrewAI
Architecture Design
This example defines two Agents and two Tasks, forming a concise sequential execution flow:
Agent 1 - Researcher: Responsible for searching cutting-edge information on a specified topic, with the goal of finding the latest and most relevant developments.
Agent 2 - Report Analyst: Responsible for transforming the data collected by the Researcher into a structured, detailed report.
Task 1 - Research Task: Conduct in-depth research on the topic, outputting a list of 10 key points, assigned to the Researcher.
Task 2 - Report Task: Write a complete report based on research results, expanding each topic into an independent section, assigned to the Report Analyst.
Environment Setup and Model Configuration
The development environment requires Anaconda (for Python virtual environments) and PyCharm. The project supports three model integration methods:
- GPT Models: Using OpenAI API through a proxy
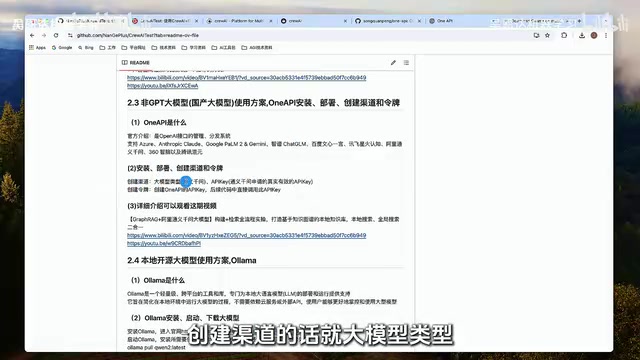
- Non-GPT Models: Managed uniformly through OneAPI, supporting domestic models like Qwen, iFlytek Spark, Zhipu AI, etc.
- Local Models: Deployed through Ollama, supporting open-source models like Llama, Qwen, etc.
OneAPI is an open-source large model API interface management and distribution system. Its core value lies in converting different vendors' model APIs into a unified OpenAI-compatible interface format. In actual development, different model vendors (such as Alibaba Cloud, Baidu, iFlytek, etc.) have varying API formats and authentication methods—direct integration would fill the codebase with adaptation logic. OneAPI abstracts underlying model providers through the concept of "channels" and unifies the calling interface through "tokens." Developers only need to program against one API specification to seamlessly switch between underlying models. Additionally, OneAPI provides enterprise-grade features like quota management, access control, and usage statistics, making it one of the de facto standard solutions for multi-model management.
Ollama is a lightweight local model runtime tool that supports one-click deployment and execution of various open-source large models on personal computers. It encapsulates complex steps like model downloading, quantization, and inference engines, providing a Docker-like experience—you can pull and run models with simple commands. Ollama provides an OpenAI-compatible REST API interface by default, enabling seamless integration with frameworks like CrewAI. The advantages of local deployment include data privacy protection and zero API call costs, but limited by consumer-grade hardware (especially VRAM), it can typically only run quantized models with 7B-13B parameters.
Core Code Structure
The project's core code is divided into three parts:
main.py - Service Entry Point: Uses FastAPI to start an HTTP service and defines a POST endpoint to receive user requests. On startup, it initializes the corresponding model environment variables based on configuration.
FastAPI is a modern Python 3.7+ web framework known for its high performance, automatic API documentation generation, and native async programming support. Built on Starlette (for the web layer) and Pydantic (for data validation), its performance is comparable to Node.js and Go frameworks. FastAPI's type-hint-driven design makes API interface definitions clear, error messages friendly, and automatically generates interactive documentation (Swagger UI) compliant with the OpenAPI specification. In AI application scenarios, FastAPI's async support makes it particularly suitable for handling time-consuming requests like model inference, avoiding blocking other concurrent requests.
# Model configuration example (supports three switching options)
model_type = "openai" # Options: oneapi, ollama, openai
crew.py - Crew Definition: Encapsulates the creation logic for Agents, Tasks, and Crews. Agent role attributes and Task descriptions are defined through YAML configuration files, then combined and executed within the Crew.
agents.yaml / tasks.yaml - Configuration Files: Agent and Task parameters are externalized to YAML files, achieving separation of configuration and code for easier adjustment and maintenance.
FastAPI Wrapping and API Call Flow
The core flow of the FastAPI wrapper is as follows:
- Receive a POST request and extract the user's topic parameter
- Call the Crew's
kickoffmethod to start multi-Agent collaboration - Wait for execution to complete and obtain the final report result
- Package the result as JSON and return it to the requester
Throughout this process, the Researcher Agent first completes information retrieval, and its output automatically becomes the context input for the Report Analyst Agent, ultimately generating a complete research report. It's worth noting that the kickoff method is a synchronous blocking call. In production environments, it's recommended to combine it with async task queues (like Celery) or FastAPI's background task mechanism to avoid timeouts from long-running HTTP connections.
GPT-4o Mini, Qwen Max, and Llama 3.1: Real-World Comparison
Under the same "AI LLMs" topic, the three models showed notable performance differences:
| Model | Speed | Output Quality | Instruction Following |
|---|---|---|---|
| GPT-4o Mini | Fastest | Excellent | Strictly output 10 items as required |
| Qwen Max | Slower | Good | Output 15 items (exceeded requirements) |
| Llama 3.1 (7B local) | Slowest | Poor | Only output 3 items, unsatisfactory results |
GPT-4o Mini performed best in both speed and quality; Qwen Max was generally usable but slightly slower in response time; the local 7B model, due to parameter limitations, clearly struggled in complex multi-Agent collaboration scenarios.
A large language model's parameter count directly affects its reasoning ability, instruction-following capability, and knowledge base. While 7B (7 billion parameter) models perform adequately in simple conversations and single-step tasks, they face severe challenges in multi-Agent collaboration scenarios: each Agent needs to accurately understand its role positioning, strictly follow output format requirements, and perform multi-step reasoning within limited context. These capabilities typically only stabilize in models with 70B+ parameters. Additionally, "emergent abilities" in multi-Agent scenarios—such as autonomous planning, self-correction, and strict format compliance—often exhibit clear parameter count threshold effects, with model performance dropping sharply below the threshold.
The phenomenon of Qwen Max exceeding output requirements reflects a common issue: different models have varying sensitivity to quantity constraints in instructions. GPT-series models, having undergone extensive RLHF (Reinforcement Learning from Human Feedback) training, perform more precisely in instruction following, while some domestic models still have room for optimization in this dimension.
Key Lessons and Recommendations for CrewAI Development
Model selection is crucial: Multi-Agent collaboration places high demands on a model's instruction-following and reasoning capabilities. Small-parameter local models may not be up to the task—it's recommended to use at least 70B+ local models or cloud API services.
Separation of configuration and code is a best practice: Placing Agent and Task definitions in YAML configuration files is CrewAI's recommended approach, facilitating rapid iteration and adjustment while also enabling non-developers to participate in configuration. This pattern borrows from the "Infrastructure as Code" concept in software engineering, making Agent behavior definitions declarative, version-controllable, and auditable.
API-ification is a critical step for production deployment: By wrapping with FastAPI, CrewAI's multi-Agent capabilities can be easily integrated into any existing system—this is an important step from demo to production environment. API-ification also brings standardization benefits—frontend applications, mobile apps, and other microservices can all invoke multi-Agent capabilities through a unified HTTP interface, achieving AI capability servitization.
Use OneAPI for unified multi-model management: For scenarios requiring testing of multiple large models, OneAPI provides a unified interface management solution, avoiding frequent code modifications for model configuration and significantly improving development efficiency. In production environments, OneAPI can also implement model-level load balancing and failover—automatically switching to backup models when a model service becomes unavailable, ensuring high service availability.
Key Takeaways
Related articles

Five Common Claude Code Mistakes — How Many Are You Making?
Five common Claude Code mistakes developers make: copy-pasting code, skipping CLAUDE.md, inefficient prompting, ignoring docs, and poor context management — with fixes.

Andrew Ng's New Course Explained: A Practical Guide to Using OpenAI's O1 Reasoning Model
Deep dive into Andrew Ng and OpenAI's Reasoning with O1 course covering test-time scaling, new prompting paradigms, multi-model orchestration, and practical applications for developers.

Learning AI After College Entrance Exams: A Complete Path from Zero to Freelancing
How to efficiently learn AI skills during summer break after exams? A complete path from mastering prompts and hands-on projects to freelancing on platforms.