Datasette 1.0a33 Released: Comprehensive JSON Extras API Expansion and AI-Assisted Development in Practice
Datasette 1.0a33 expands JSON Extras API across all endpoints; built with dual-AI collaboration.
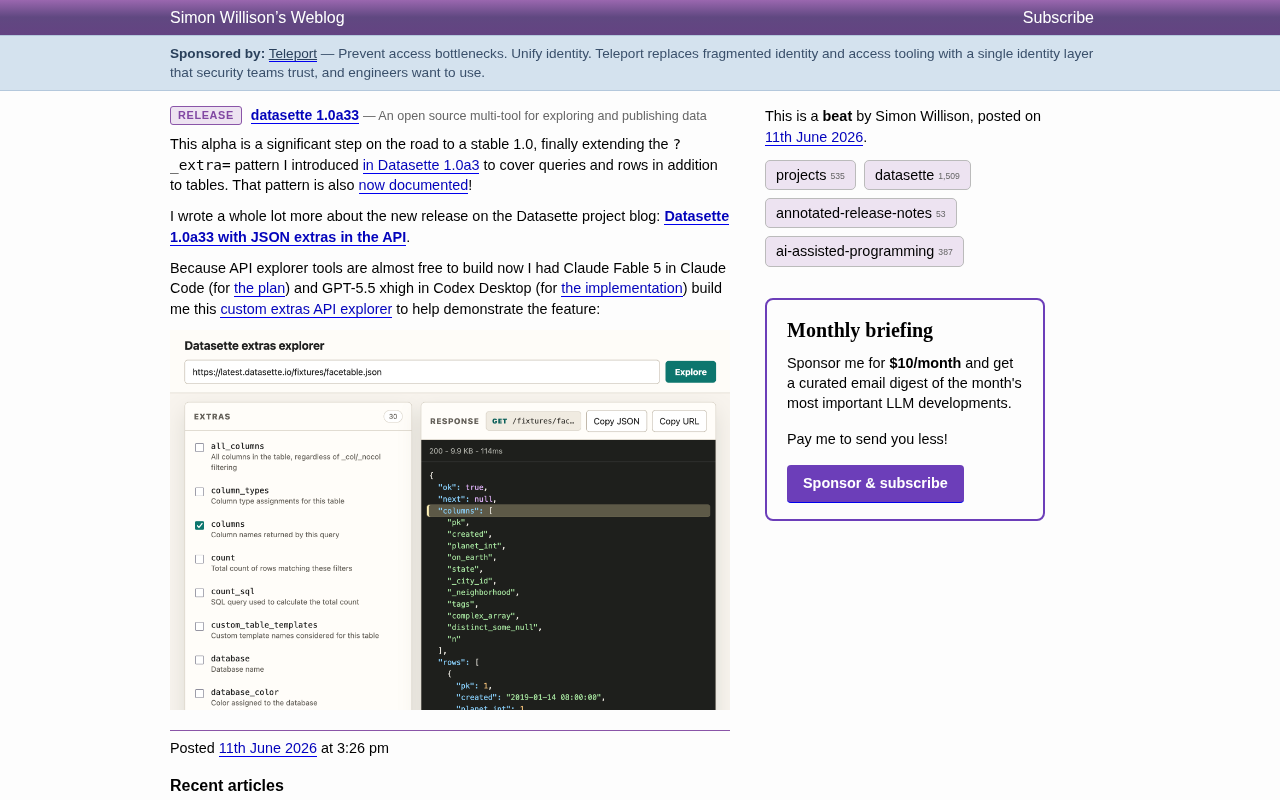
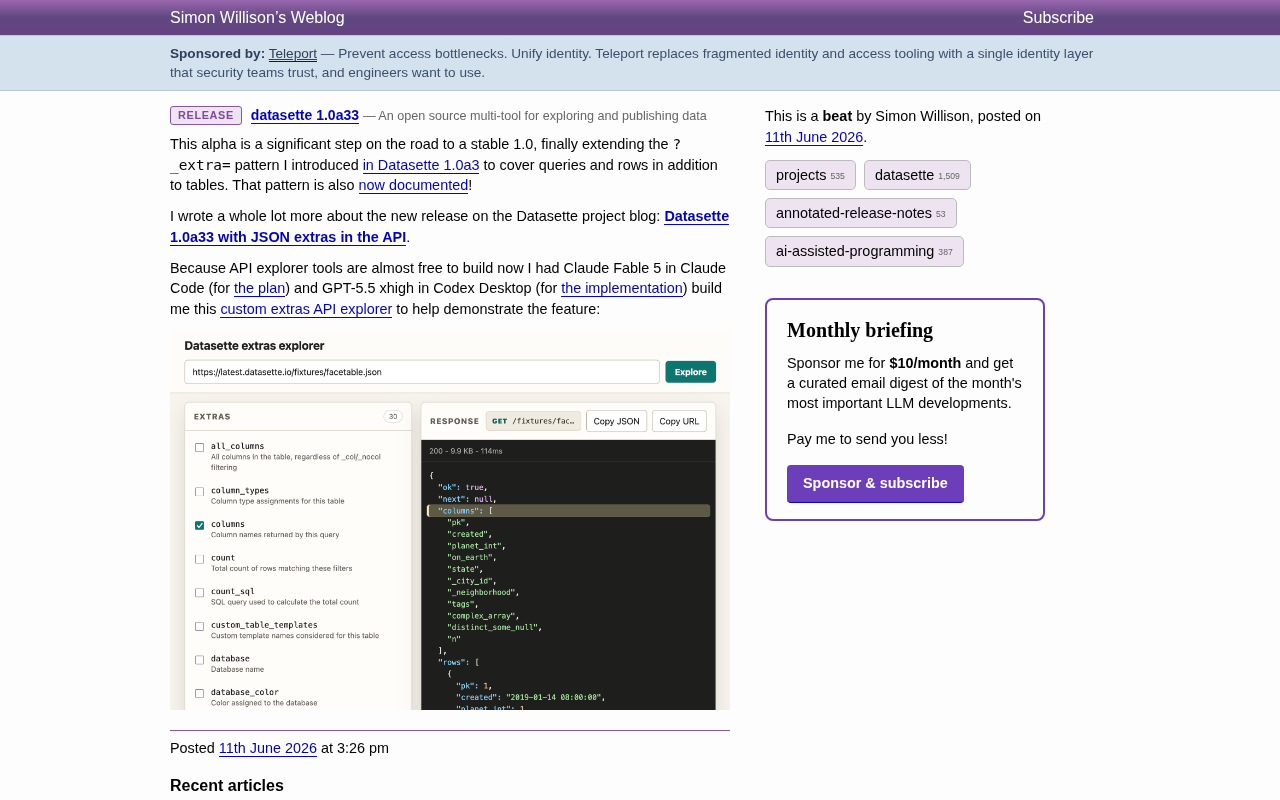
Datasette 1.0a33 extends the ?_extra= pattern from tables to queries and rows, enabling on-demand metadata in all API endpoints. Creator Simon Willison used Claude Fable 5 for planning and GPT-5.5 for implementation to build an interactive Extras API Explorer, showcasing a dual-AI development workflow that dramatically reduces tooling costs.
Overview
The Datasette project has reached its 1.0a33 alpha release, marking an important step toward a stable 1.0 version. The core highlight of this update is the expansion of the ?_extra= pattern from tables to queries and rows, significantly enhancing API flexibility. Even more noteworthy, project creator Simon Willison used Claude Fable 5 and GPT-5.5 to build an interactive API exploration tool demonstrating the new features, showcasing the real-world productivity of AI-assisted programming.
Technical Background: Datasette and SQLite
Datasette is a data exploration and publishing tool built on top of SQLite. SQLite is the most widely deployed database engine in the world — by some estimates, there are over one trillion active SQLite instances globally. It stores an entire database in a single file, requires no separate server process, and is widely embedded in phones, browsers, and operating systems. Datasette's core insight is combining SQLite's lightweight nature with web technology: anyone with a .db file can instantly get a fully functional JSON API and visual interface. This design is particularly well-suited for data journalists quickly publishing public datasets, researchers sharing experimental data, and developers doing rapid prototyping. It's this "zero-config, instantly usable" philosophy that has earned Datasette widespread attention in the open data community since its initial release in 2018.
Comprehensive Expansion of the ?_extra= Pattern
Unified Coverage from Tables to Queries and Rows
The ?_extra= pattern was first introduced in Datasette 1.0a3 back in 2023, initially supporting only table-level extra data requests. After nearly three years of iteration, this pattern has finally achieved full coverage in 1.0a33 — developers can now use extras parameters in query and row API endpoints to retrieve additional metadata.
This means that when requesting Datasette's JSON API, you can use ?_extra=columns to get column names, ?_extra=count to get the total number of matching rows, ?_extra=count_sql to get the SQL query used to calculate the total, and more. This design makes API responses highly customizable — clients only receive the data they actually need, reducing unnecessary bandwidth consumption.
The On-Demand API Design Philosophy
The ?_extra= pattern is essentially an on-demand API design strategy, sharing similarities with GraphQL's field selection concept but implemented in a much more lightweight fashion. In traditional REST APIs, the data structure returned by an endpoint is typically fixed — clients either accept all fields or the server needs to create multiple endpoints for different scenarios (the so-called "endpoint explosion" problem). The ?_extra= pattern allows clients to declare which additional metadata they need via query parameters, and the server only computes and returns the requested portions.
This design is especially important for performance — for example, a count operation on a large dataset may require a full table scan, taking anywhere from milliseconds to several seconds. If included by default in every response, it would severely degrade API performance. With the extras mechanism, the computation is only performed when the client explicitly requests it. This "lean by default, rich on demand" strategy is known as Sparse Fieldsets in API design, and a similar pattern exists in the JSON:API specification.
Official Documentation Finally Complete
It's worth noting that this feature pattern, which has existed for years, now finally has comprehensive official documentation. For an open-source project, documentation completeness often signals feature maturity and stability, further confirming that Datasette is seriously progressing toward a stable 1.0 release.
The AI-Assisted Extras Explorer Tool
A Dual-AI Collaborative Development Workflow
One of the most notable details in this release is that Simon Willison used AI tools to build an interactive Datasette Extras API Explorer. His workflow is quite instructive:
- Planning phase: Used Claude Fable 5 within Claude Code to generate the project plan
- Implementation phase: Used GPT-5.5 xhigh within Codex Desktop to complete the code implementation
This "one AI for planning, another AI for implementation" dual-model collaboration pattern represents a cutting-edge practice in current AI-assisted programming. Claude Fable 5 is a model released by Anthropic in 2025, integrated into the Claude Code command-line tool, and known for its strong reasoning, planning, and code architecture capabilities. GPT-5.5 is OpenAI's latest-generation model, with its xhigh compute configuration representing the highest reasoning intensity, excelling at translating detailed plans into high-quality code implementations. Codex Desktop is OpenAI's local programming agent tool, capable of executing code generation and modifications directly within a developer's project environment.
Simon's choice of this dual-model workflow reflects an important trend in AI programming: different models have different strengths across different task dimensions, and experienced developers are beginning to combine multiple AI models like assembling a team, letting each model play to its strengths. Simon himself remarked in his blog post that "the API explorer tool was now essentially free to build" — a statement that speaks to the enormous productivity gains AI programming tools deliver.
Core Features of the Explorer Tool
As visible in the screenshot, the tool provides an intuitive interface:
- The left panel lists all available extras (30 in total), presented as checkboxes
- The right panel displays the API response in real time, including status code, response size, and latency
- One-click copying of JSON and URLs for quick developer debugging
The tool itself serves as the best documentation for Datasette's extras feature — through interactive exploration, developers can intuitively understand what each extra parameter does. This "interactive documentation" concept is increasingly popular in the developer tools space. Stripe's API documentation and Swagger UI are pioneers of a similar approach, and AI involvement has dramatically reduced the cost of building such tools.
Datasette 1.0 Roadmap and Design Philosophy
Since its initial release in 2018, Datasette has gone through 33 alpha version iterations. This lengthy pre-release cycle is not uncommon in the open-source community — it follows the pre-release identifier conventions of Semantic Versioning. In this system, an alpha version means the API interface may change at any time and is not recommended for production use; a beta version indicates that features are essentially frozen with only bug fixes; and an official 1.0 release represents a stability commitment for the public API — subsequent non-major version updates will maintain backward compatibility. The fact that Datasette has gone through 33 alpha iterations before approaching 1.0 reflects the author's extreme caution regarding API stability — once 1.0 is released, any breaking changes would have to wait until 2.0.
As a tool that instantly transforms SQLite databases into JSON APIs and interactive interfaces, Datasette has broad applications in data journalism, open data, and rapid prototyping. Data journalism is a journalistic practice driven by structured data analysis, where reporters need to quickly explore, query, and publish large public datasets. The traditional approach requires setting up database servers and writing backend code, while Datasette shortens this process to minutes. For example, multiple U.S. news organizations use Datasette to publish government budget data, election donation records, and environmental monitoring data, allowing readers to perform self-service queries directly through a web interface. In the open data movement, Datasette is also used by government agencies and nonprofits to quickly set up data portals, lowering the technical barrier to data openness.
The evolution of the ?_extra= pattern reveals Simon Willison's thoughtful approach to API design: maintaining backward compatibility while providing sufficient flexibility. This incremental design philosophy allows Datasette to continuously evolve without breaking existing user workflows.
Summary
While 1.0a33 is an alpha release, it marks the maturation of Datasette's API design. The comprehensive coverage of the ?_extra= pattern lays a solid foundation for the eventual stable 1.0 release. Meanwhile, the practice of using AI to build the Explorer tool demonstrates an efficient paradigm for developer tool creation — when AI can rapidly generate auxiliary tools, software documentation and discoverability both see qualitative improvements.
Key Takeaways
Related articles

A Gen-Z Woman Making $1.5M/Month: Deconstructing the Growth Methodology Behind AI Apps
Gen-Z indie dev Nicole built 4 hit AI apps earning $1.5M/mo. Deep dive into her industrialized UGC engine, traffic testing system, and minimalist tech stack.
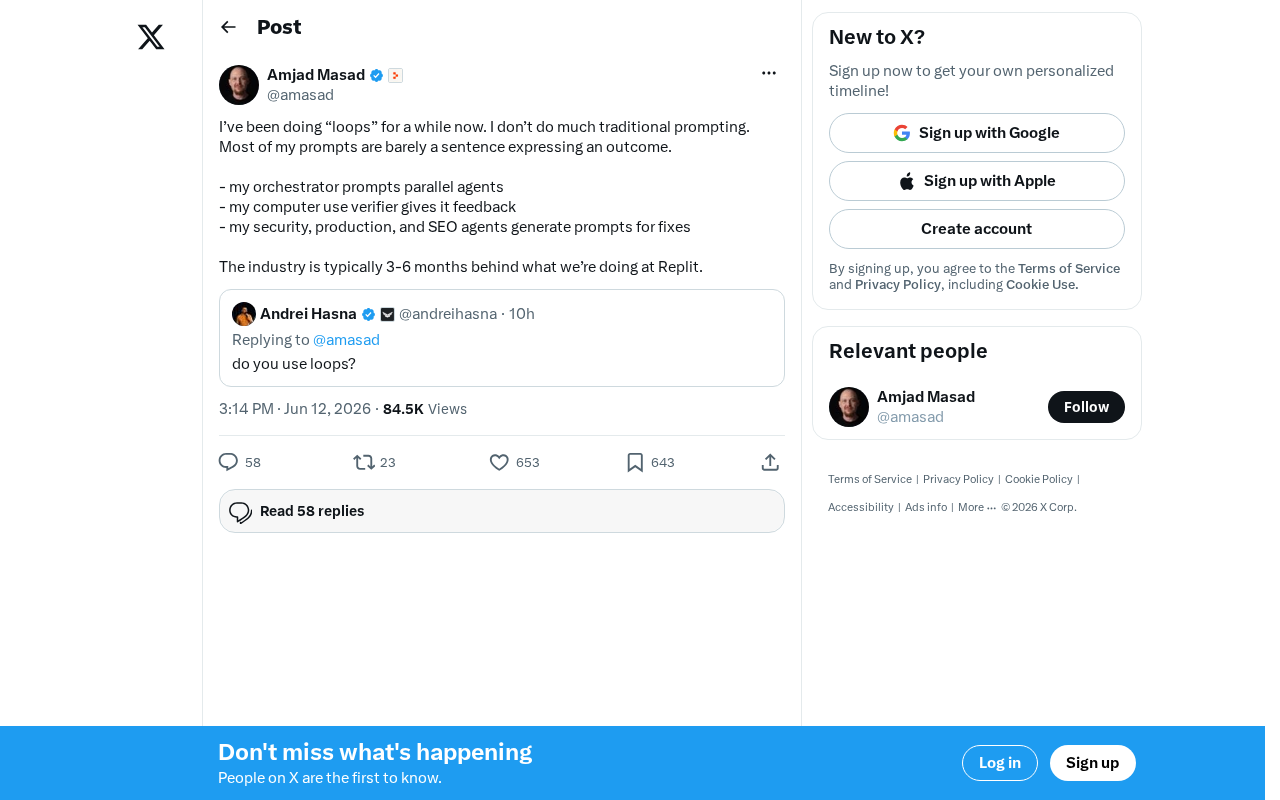
Replit's AI Loops Workflow Explained: Multi-Agent Collaboration Replaces Prompt Engineering
Deep dive into Replit's AI Loops workflow: how orchestrators, parallel agents, and Computer Use Verifiers build automated closed-loop systems through multi-agent collaboration.
Claude Code + Skills: A Practical Guide to AI-Powered Test Case Generation
Learn how to use Claude Code + Skills to auto-generate enterprise-grade test cases. Covers AI Agent vs LLM differences, the four core capabilities, and the complete workflow from requirements to test cases.