Decoding Cursor's Developer Report: The Truth Behind a 46x Productivity Gap in AI-Powered Coding
Cursor's report reveals a 46x productivity gap between top 1% and median developers in the AI coding era.
Cursor's first developer habits report, based on data from millions of developers, reveals that AI has doubled average coding productivity in just one year. However, the gains are extremely unevenly distributed — Gini coefficients above 0.7 show the top 1% produce 46x more AI-generated code than the median developer. The report also highlights a shift toward context-heavy AI usage (13:1 input-to-output token ratio), a 36% auto-merge rate, and the rise of model routing strategies for cost optimization.
Introduction
On May 29, Cursor released its first-ever developer habits report. Drawing on real usage data from millions of developers worldwide on its platform, the report provides an in-depth analysis of the current state of AI-assisted coding across five core dimensions: development efficiency, developer disparity, context evolution, automation transformation, and model costs. The report reveals a harsh reality that is rapidly taking shape: in the AI era, the gap between developers is widening at an unprecedented pace.


Development Efficiency: A Historic Doubling of Per-Capita Productivity
Explosive Growth in Coding Volume and PR Size
Cursor's data shows that in just over a year, the average weekly coding output per developer has more than doubled — and the growth rate is still accelerating. In the pre-AI era, meaningful productivity gains typically required years of experience accumulation. Yet AI has doubled the industry's average productivity in barely a year, something unprecedented in the history of software development.
Even more noteworthy is the change in code additions per Pull Request (PR). PRs are the core mechanism for code collaboration in modern software development — after completing a feature, a developer creates a PR requesting team members to review the code before merging it into the main branch. PR size typically reflects the complexity of a development task. The conventional wisdom holds that PRs exceeding 400 lines significantly degrade review quality, making thousand-line PRs a "code smell" that should be split up.
However, the AI era is redefining this standard. The report shows that the 75th percentile of code additions per PR has surged 2.5x year-over-year — tasks that previously required three or four separate PRs can now be completed in one. The share of "super PRs" exceeding 1,000 lines has climbed from 7–8% to 13.8%, meaning roughly one in every seven PRs is now a thousand-line behemoth.
Steady Improvement in Code Quality
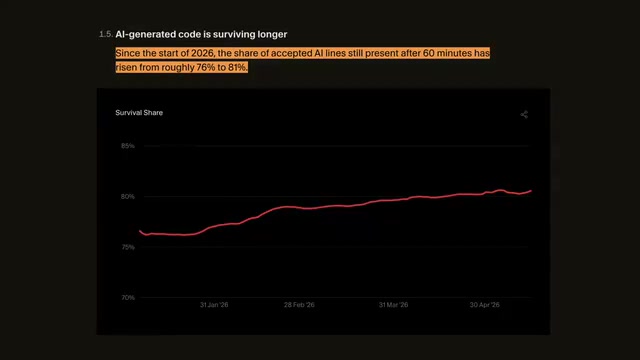
Cursor uses a "60-minute retention rate" to measure the quality of AI-generated code — the percentage of AI-generated code that developers keep after 60 minutes. The data shows this metric has risen from 76% to 81%, indicating that AI-generated code is becoming increasingly reliable. An 81% retention rate doesn't mean the code is flawless — developers still fine-tune and optimize — but AI is already saving developers significant time.
Additionally, the average number of tool calls per AI session has risen 30% over the past two months. "Tool calls" here refer to the various capabilities a Coding Agent autonomously invokes while executing tasks — including reading files, searching codebases, running terminal commands, executing tests, and more. Unlike traditional code completion tools that only provide line-level or function-level autocompletion, Coding Agents can autonomously plan task steps, forming a complete "perceive-plan-execute-feedback" loop to independently handle the entire workflow from requirement understanding to code implementation to test verification. The increase in tool calls indicates that development with Coding Agents is shifting from an experiment by early adopters to a widespread industry practice.
Developer Disparity: The Brutal Divide Revealed by the Gini Coefficient
Inequality Far Beyond the Warning Threshold
This is the most thought-provoking dimension of the report. Cursor uses the Gini coefficient from economics to measure inequality among developers. Originally proposed by Italian statistician Corrado Gini in 1912 to measure income distribution inequality, the Gini coefficient ranges from 0 to 1, where values closer to 1 indicate greater inequality, and 0.4 is generally considered the warning threshold. For reference, Nordic countries typically have Gini coefficients between 0.25–0.30, the United States sits around 0.39, and values above 0.4 are considered potentially destabilizing.
Applying the Gini coefficient to developer productivity analysis is an innovative quantitative approach. The report shows that the Gini coefficients for AI code volume, AI usage costs, and token consumption reached 0.77, 0.75, and 0.72 respectively — each far exceeding the 0.4 warning threshold. In economic terms, this is equivalent to the world's most unequal nations, suggesting that disparities in AI tool proficiency are creating an extreme "digital productivity divide."
This means a tiny elite of top developers is capturing the vast majority of AI-enabled productivity gains.
The 46x Productivity Chasm
The stratified data is even more striking: the top 1% of developers (99th percentile) produce 46 times the daily AI-generated code of the median developer, and merge 15 times more PRs per week than the average developer. In practical terms, a single top AI developer writes as much code in one day as an average developer produces in a month and a half, and completes as many tasks in one week as an average developer does in three and a half months.
Even the top 10% of high-performing developers produce only 10x the median — still a massive gap from the top 1%. In the pre-AI era, the efficiency gap between excellent and average developers might have been only a few-fold, and it took years to develop. In the AI era, "whether you can use AI, and whether you can use it well" is becoming the single most critical factor determining productivity, and the gap is forming far faster than ever before.
Context Evolution: From Local Understanding to Global Cognition
The Explosive Growth of Input Tokens
One of the most significant changes in AI coding is the explosive growth in context input token volume. Tokens are the basic units that large language models use to process text — one English word typically corresponds to 1–2 tokens, and one Chinese character roughly 1.5–2 tokens. The context window is the maximum number of tokens a model can process in a single pass, determining how much information the AI can "see." Early models like GPT-3.5 supported only 4K tokens (roughly 3,000 words), while mainstream models in 2024–2025 support 128K or even 200K tokens, providing the technical foundation for AI to understand large-scale code projects.
The report shows that the ratio of model input to output tokens has soared from 4.52:1 to 13:1. This means that for every piece of code the model generates, it processes 13 times more contextual information than it outputs. This change reflects a fundamental shift: AI coding is evolving from "blind men and the elephant"-style local code generation to systematic development based on holistic understanding.
This addresses the biggest pain point of early AI coding — the lack of global context comprehension. AI can now understand an entire project's code structure, dependency relationships, design patterns, and coding conventions, dramatically reducing instances where generated code conflicts with the project's overall architecture.
A Fundamental Shift in Cost Structure
From a cost perspective, input tokens now account for over 90% of total non-cached tokens, and the cost share of input context has risen from 47.5% to nearly 70%. This means the cost of AI coding is primarily spent on "helping AI understand the project" rather than "having AI generate code." Future competition among AI coding tools will largely be a competition over context management capabilities.
Meanwhile, cached read tokens account for over 90% of overall token activity. Caching refers to the model reusing previously processed context information across multiple conversation turns or API calls, rather than reprocessing all input from scratch each time. This mechanism was first commercialized at scale by Anthropic in Claude (Prompt Caching), with cached token processing costs typically reduced by 75–90% and response latency significantly shortened. A 90% cached read ratio means that when a Coding Agent executes multi-step tasks, the vast majority of context comprehension work only needs to be done once — subsequent steps reuse existing understanding. This is a key technical foundation enabling Agents to efficiently execute complex tasks, improving both response speed and reducing invocation costs.
Automation Transformation: From Assistive Tool to Full-Process Takeover
Auto-Merge Rate Surges to 36%
AI is no longer just a coding assistant — it is permeating the entire software development lifecycle. The report shows that the volume of AI code changes auto-merged without human review has surged 5x, with the auto-merge rate climbing from 7% to over 36%. This means that for every three changes committed to a codebase, one is entirely AI-generated and automatically merged.
Currently, auto-merging is primarily limited to simpler routine changes — such as dependency version upgrades, formatting adjustments, simple bug fixes, and test case additions. Complex core business logic still requires human review. But a 36% auto-merge rate already reflects rapidly growing developer trust in AI coding capabilities — this figure was below 10% just six months ago.
The Explosion of Enterprise-Customized AI Development Tools
The report also notes explosive growth in enterprise-customized SDK usage. Companies can customize Coding Agents, train private models, integrate internal codebases and documentation, and establish coding standards and security policies tailored to their needs. This customization capability means AI coding tools are no longer "one-size-fits-all" generic products — they can deeply adapt to an enterprise's specific tech stack, architectural style, and compliance requirements. This signals that AI coding tools will increasingly move toward platformization and customization, with different industries and companies having their own dedicated AI development assistants.
Model Costs: Mix-and-Match Becomes the Mainstream Strategy
9x Price Spread and 7x Efficiency Gap
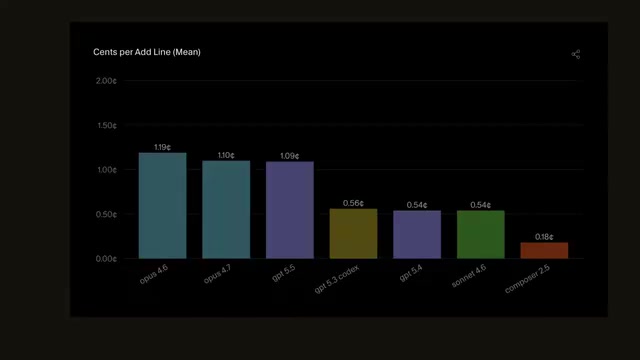
The report provides a cost-benefit analysis of seven major model families. AI model pricing is typically based on input/output token volume, with significant price differences across models due to varying parameter scales, training costs, and inference complexity. For per-Agent-request costs, the most expensive — Claude Opus 4.7 — costs $1.57 per request, while the cheapest — Cursor Composer 2.5 — costs just $0.18 per request, a 9x price spread.
The Claude Opus series is Anthropic's flagship reasoning model, excelling at complex logic and long-chain reasoning. GPT 5.5 is OpenAI's latest-generation model with outstanding overall capabilities. Cursor Composer 2.5 is Cursor's in-house lightweight specialized model, deeply optimized for code generation scenarios, achieving highly efficient code output at extremely low cost.
Looking at "cost per accepted line of code," the gap between models narrows to 7x. This metric is more practically meaningful than raw API call costs because it accounts for code quality and developer acceptance rates. Premium models may cost more per call, but they produce more effective code with higher acceptance rates. High-end models like Claude Opus 4.7 and GPT 5.5 significantly outperform lightweight models on complex tasks and deep reasoning, while Cursor's Composer 2.5 delivers exceptional cost-effectiveness at minimal expense.
As a result, cost control is no longer about simply choosing the cheapest model — it's about matching models to task complexity. Use lightweight models for simple code formatting and comment generation; use premium models for complex architectural design and algorithm implementation. This "model routing" strategy is becoming the mainstream approach for AI development teams.
The Developer Competency Model Is Being Restructured
This report tells us that while AI hasn't replaced developers yet, the rules of the development industry are already being rewritten. The core competitive advantages in future software development are shifting toward three areas:
- The ability to harness AI: Expressing requirements in clear, precise language (i.e., Prompt Engineering), guiding AI through complex tasks, and quickly identifying and correcting AI mistakes. This requires developers not only to understand code but also to collaborate effectively with AI, translating vague business requirements into precise instructions that AI can understand.
- Global context management ability: Understanding architectural design from a project-level perspective, knowing what to delegate to AI and what to personally oversee. In an era where the input token ratio has surged to 13:1, whether you can provide AI with the right contextual information directly determines the quality of AI output.
- Automation pipeline implementation ability: Converting repetitive work into automated processes through AI and automation tools — including CI/CD pipeline integration, automated testing, code review automation, and more — ensuring AI contributes not just to the coding phase but throughout the entire software delivery lifecycle.
Developers who can't use AI are like developers who can't use computers — they'll find it increasingly difficult to survive in this industry. Meanwhile, those who truly master AI are pulling ahead of everyone else at a 46x efficiency differential.
Key Takeaways
Related articles
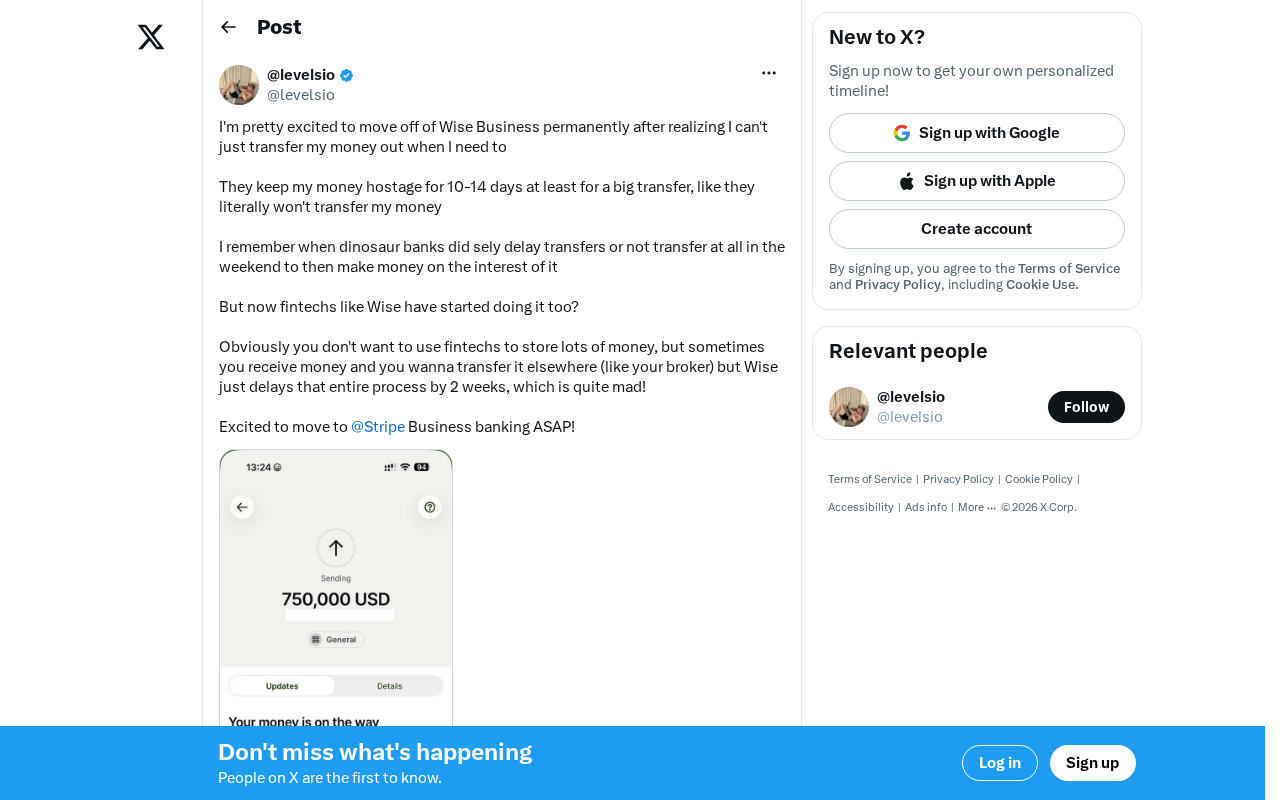
Wise Large Transfer Delayed Two Weeks: How Should Cross-Border Entrepreneurs Respond?
Wise Business users face 10-14 day delays on large transfers, sparking debate on whether fintech is repeating traditional banking mistakes. Analysis and practical tips for cross-border entrepreneurs.
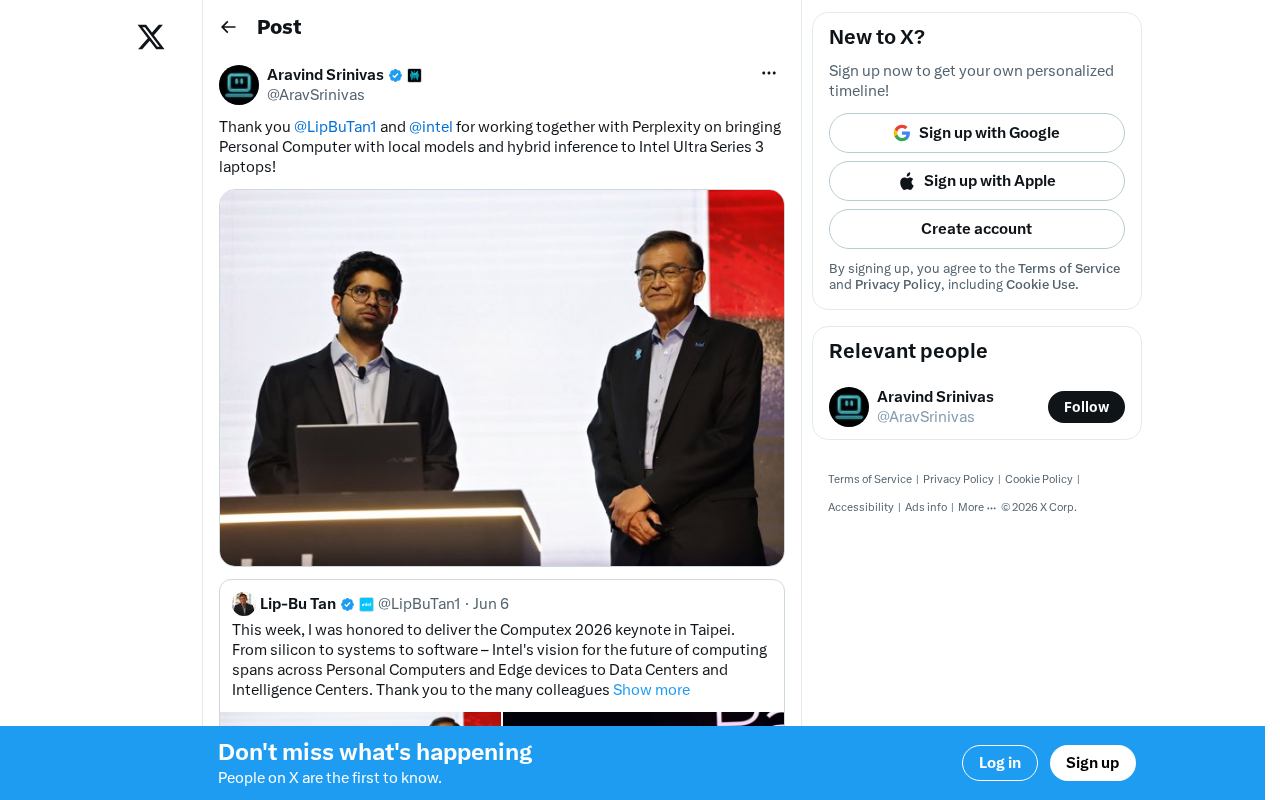
Perplexity Partners with Intel: Local AI Models and Hybrid Inference Come to Laptops
Perplexity partners with Intel to bring local AI models and hybrid inference to Core Ultra Series 3 laptops. We break down the architecture, NPU capabilities, and the cloud-to-edge AI trend.
AI Large Model Learning Roadmap Breakdown: Three Stages from Application Development to Model Fine-Tuning
Deep breakdown of a popular AI large model learning roadmap covering LangChain, RAG, Agent, and LoRA fine-tuning across three stages, with analysis of its strengths and limitations for career changers.