Deep Dive into Devin's Background Agent Architecture: Behind the 80% AI-Committed Code

A deep dive into Devin's background agent architecture revealing the engineering challenges behind AI-driven coding at scale.
This article analyzes Cognition's Devin background agent architecture based on insights from its CPO Walden Yan and OpenInspect's Cole Murray. It covers key decisions including brain-sandbox separation, environment configuration challenges, MCP integration realities, memory system design, multi-agent collaboration patterns, AI code hygiene issues, and practical deployment scenarios from SRE automation to non-engineer programming.
When 80% of code commits in Devin's repository come from AI while the engineering team has only grown by 10%, we're witnessing a turning point in software engineering. The Latent Space podcast recently invited Cognition co-founder and CPO Walden Yan and OpenInspect creator Cole Murray to discuss the architecture design of background agents, real-world deployment challenges, and the future direction of this field.
From Hand-Held Programming to Background Autonomy: The Capability Leap of AI Coding Agents
Walden reflected on the key turning point. Around December 2024, with the release of next-generation models, AI coding agents leaped from "needing hand-holding guidance" to "being essentially self-driven." This means that given a sufficiently good specification, an agent can generate a complete Pull Request directly from requirements with almost no human intervention.
This paradigm shift is particularly evident within Cognition: the number of PRs merged by Devin grew 7x in two to three months, while the engineering team only grew by about 10%. Even more striking, Devin's share of code commits in its own repository surged from 16% in January to 80% by March.
Walden also mentioned a landmark event — when Sonnet 3.7 was released, the team used it to rewrite large portions of Devin's code in a single evening, essentially "stripping away parts that were no longer needed due to improved model intelligence." This exponential growth in model capabilities transformed background agents from proof-of-concept to practically usable productivity tools.
Core Architecture Decision: Separating the Brain from the Sandbox
The primary architecture decision facing background agent systems is: should the agent run inside the sandbox (in the box) or outside it (out of the box)?

In the Box has the advantage of simplicity — all state lives within the sandbox, making it easier to manage. But the downside is security risk: all secrets must be placed inside the sandbox, and AI's unpredictability could lead to secret leakage.
Out of the Box places the agent's "brain" on a separate control plane, with the sandbox serving only as the "hands" that execute operations. This architecture is more complex but offers better security and can reuse existing development environment infrastructure.
Cognition chose the "brain-machine separation" architecture from the very beginning. Walden gave a practical example: when different users interact with the agent through the same GitHub App, permission isolation becomes very difficult without brain-machine separation. With the separated architecture, only minimal-privilege secrets are placed on the machine, and the brain is completely inaccessible from the machine side.
Cole also agreed this is the superior long-term architecture. OpenInspect currently runs inside the sandbox but is gradually migrating outward.
Environment Setup: The Most Underestimated Challenge for Background Agents
Both guests independently pointed out that repository environment setup is the most persistent challenge for background agents. Many teams' development environment setup process is "go ask Bob for the keys" — which obviously doesn't work for AI agents.
Walden shared an interesting infrastructure story: early on, many teams found that grep was extremely slow on the agent's virtual machines, so they tried to build custom grep indexes. But Cognition's infrastructure team discovered the root cause was actually quite simple — these VMs were using network file systems underneath, so every grep operation was actually making network calls. The solution wasn't rebuilding indexes but switching file systems.
These kinds of details also include: Cognition developed a proprietary incremental file system format that makes VM save and restore times proportional to the file system diff rather than the entire disk size. This dramatically reduced Devin's startup time from "10-minute cold starts."
MCP Integration: Ideals vs. Reality

Although the MCP (Model Context Protocol) ecosystem has seen explosive growth, truly doing integration well is far more complex than just "connecting an MCP." Walden used Slack integration as an example: a simple MCP can only let the agent send messages, but Devin needs to interact naturally in Slack like a colleague — supporting webhook callbacks, controlling message frequency, and avoiding channel flooding.
Walden stated that he would prefer a bidirectional protocol more expressive than MCP, rather than just a set of tool calls. When the MCP specification becomes overly complex, it loses its original intent of "simple one-click connection" and ultimately reverts to the old path of building first-party integrations.
Cole added a practical principle: if a particular integration is used in nearly every session, it's worth owning it yourself and doing deep optimization rather than relying on a generic MCP.
Memory Systems: A Problem AI Agents Haven't Fully Solved

Memory is a problem both guests acknowledged as "not yet fully solved." Devin's memory system has gone through multiple iterations:
- Auto-generation first: 95% of memories come from automatic extraction, not user-written content. When users correct Devin, the system asks "want to remember this?"
- Generation quality control: One-time preferences (like "use a Draft PR this time") shouldn't be generalized into permanent rules
- Retrieval precision: How to retrieve the right content at the right time from thousands of memories without context explosion
- Memory editing: Supporting updates and corrections to existing memories
Walden revealed an interesting exploration direction: since current models are extremely good at using file systems, should the memory system be rebuilt as a file-system-like structure that lets the agent navigate on its own?
Multi-Agent Collaboration: From Hype Back to Pragmatism

Walden had previously expressed the famous view of "don't build multi-agent," but he admitted this stance may need revision. A year ago, multi-agent was completely infeasible, but now models have demonstrated genuine communication maturity — Devin sometimes pushes back on users' incorrect instructions. This ability to "no longer be a yes-man" makes multi-agent collaboration possible.
However, the most effective pattern in practice remains the manager-sub-agent model: one primary agent assigns tasks, and sub-agents work independently in their own isolated environments, minimizing conflicts. Cognition even gave Devin an MCP to create and manage other Devin instances, but "swarm intelligence"-style free interaction still creates chaos.
An interesting experiment: the team tried building a real product purely through AI coding with absolutely no code review. They found that after about two weeks, the codebase degraded to an unmaintainable state — buttons reimplemented in 10 places, inconsistent colors, technical debt growing exponentially.
Code Hygiene Issues with AI Coding and Mitigation Strategies
Both guests shared multiple common anti-patterns in AI coding:
- GPT models tend to maintain backward compatibility at all costs, producing bizarre import/export chains
- Python code frequently contains
hasattrandgetattr, which is essentially the model's "reward hacking" behavior — avoiding code errors - Untyped tuples proliferate, with
Dict[str, Any]used everywhere - Over-commenting: Some models write paragraph-level comments on every function. While the content quality is decent (including decision reasoning and alternative analysis), the information density is excessive
Mitigation strategies include: adding these anti-patterns to lint rules (e.g., banning getattr), using tools like Semgrep for automatic detection, and scheduling regular code cleanup by humans or AI.
Walden proposed an important architectural principle: strictly control boundaries between modules. As an architect, your job is to define hard contracts between modules. Within modules, AI can operate freely, but cross-module changes must go through human approval.
Deployment Scenarios: From SRE Automation to Universal Programming
Cole summarized the three most common customer use cases:
- SRE auto-triage: The agent acts as the first responder to alerts, automatically gathering context, analyzing logs, and even directly generating fix PRs
- Non-engineer programming: PMs no longer create Issues but describe requirements directly in Slack, and the agent automatically generates PRs
- Customer support enhancement: When support teams encounter issues, the agent automatically analyzes the codebase to provide full context, skipping the back-and-forth of "can you provide more information"
Regarding costs, Cole revealed that the current common budget range is $1,000 to $5,000 per engineer per month, but this number may continue to climb as more powerful frontier models emerge. Walden expressed strong interest in "Smart Routing" — mixing frontier and sub-frontier models — believing it will be a key direction for cost reduction and efficiency improvement.
Conclusion
Background agents are evolving from early adopters' toys into enterprise-grade infrastructure. But as this conversation reveals, the real challenges aren't about getting AI to write code — they're about environment setup, security isolation, memory management, integration depth, code quality control, and a whole series of engineering problems. For teams looking to build or adopt background agents, understanding these "below the iceberg" aspects may be more important than choosing which model to use.
Related articles
Klue Hacked: Data Breach Exposes Huntress, HackerOne, and Other Major Security Companies
Market research firm Klue was hacked, exposing data from Huntress, HackerOne, Jamf, Recorded Future, and Tanium. Analysis of supply chain attack risks and third-party risk management strategies.
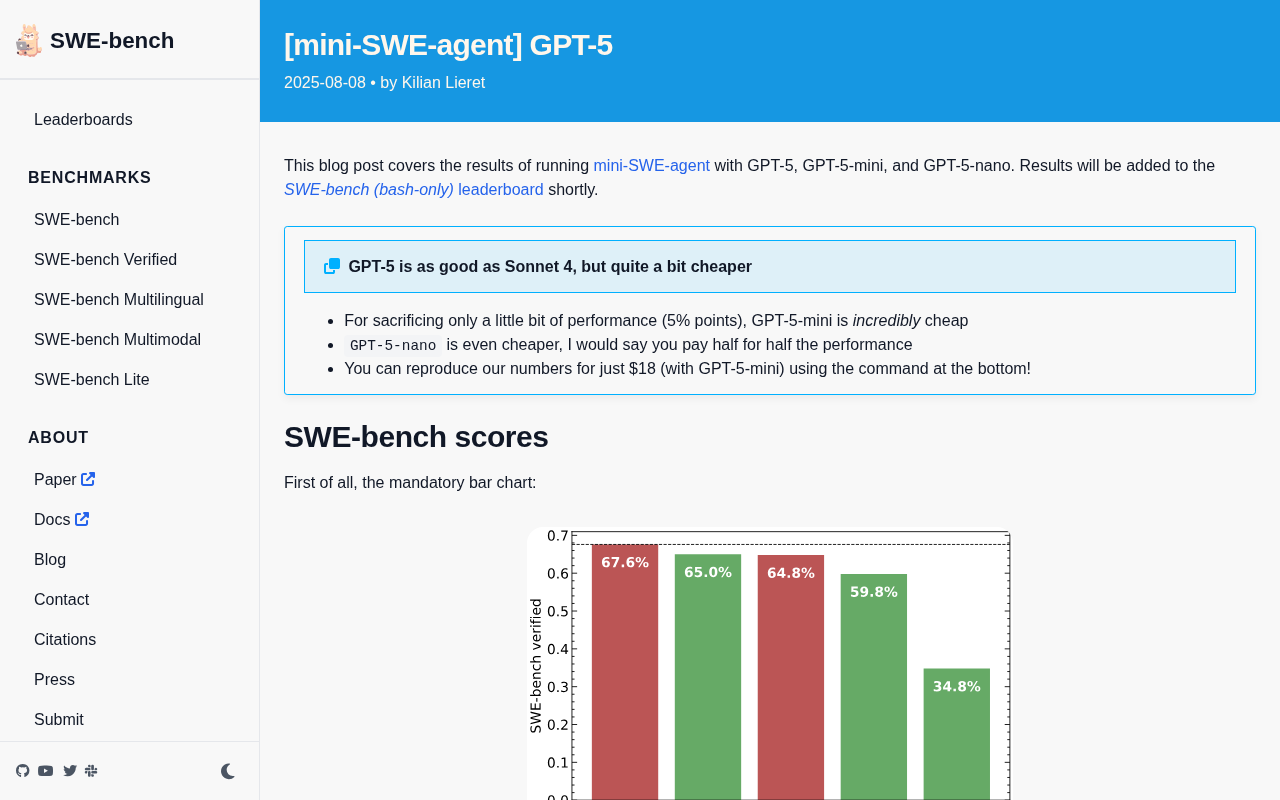
GPT-5 SWE-bench Evaluation: GPT-5-mini Crushes the Competition on Cost-Effectiveness vs Claude Sonnet 4
mini-SWE-agent's GPT-5 series evaluation on SWE-bench shows GPT-5 matches Claude Sonnet 4, while GPT-5-mini loses only ~5 points at less than 1/5 the cost.
DAQIRI Platform Explained: Deep Integration of High-Speed Data Acquisition and Real-Time AI Inference
Deep dive into how the DAQIRI platform embeds NVIDIA GPU-accelerated computing into high-speed data acquisition pipelines, enabling real-time AI inference for industrial inspection, scientific experiments, and autonomous driving.