Deep Dive into OpenAI Codex /goal: A New Paradigm Where AI Agents Work Continuously Until the Goal Is Achieved
OpenAI Codex /goal lets AI Agents autonomously loop until goals are achieved, shifting programmers from executors to goal definers.
OpenAI's new Codex CLI /goal command enables AI Agents to work continuously toward a defined goal across multiple rounds without losing context. This article explores its origins in the community's Ralph Loop pattern, its three-layer protection mechanism against idle spinning and self-deception, the 1570-line Rust implementation with SQLite persistence and smart token budgeting, and the deeper paradigm shift from telling machines how to do things to simply telling them what you want.
Deep Dive into OpenAI Codex /goal: A New Paradigm Where AI Agents Work Continuously Until the Goal Is Achieved
When AI starts managing its own progress, humanity's biggest crisis isn't unemployment—it's discovering that we don't actually know what we want. OpenAI recently added a /goal command to Codex CLI. It looks like a small feature, but the direction it represents—letting an AI Agent set a goal and keep running until it's achieved, no matter what—may be more significant than most major version updates.
This article will thoroughly dissect Codex /goal from feature overview, technical implementation, and source code architecture to the deeper paradigm shift it represents.

The Process No Longer Matters—Only the Goal Does
The core logic of /goal is simple: you set a goal for Codex, and it works continuously toward that goal—writing code, running tests, checking results. If one round doesn't get it done, it automatically starts the next, maintaining context across multiple rounds.
"The process doesn't matter, only the goal does"—this sounds like management platitude, but in the context of AI Agents, it's a brutal statement of fact. Programmers' value used to lie precisely in the "process": knowing how to decompose problems, how to debug, how to find a way through the maze. Now OpenAI is telling you that all of these are intermediate states that can be ground down by loops.
The essence of /goal isn't a new command—it's a manifesto: humanity's role is devolving from "executor" to "wisher." The problem is, wishing is also a skill, and most people can't even articulate their wishes clearly.
Ralph Loop: A "Dumb but Effective" Brute-Force Cycle
Before Codex officially launched /goal, the community was already experimenting with something similar called the Ralph Loop.
The name comes from Ralph Wiggum, the intellectually challenged character from The Simpsons, coined by developer Jeffrey Huntley. Using a lovably dim character to name a brute-force loop pattern reveals the community's attitude toward this approach: it's dumb, but it works.
The Ralph Loop works in a crude fashion:
- Set a goal
- Let the Agent run one round
- After the round ends, the Agent starts fresh with a completely new context window
- Memory is maintained through Git records and progress files
- If it fails, start over until the goal is achieved
It's essentially "shift change with written handoff notes"—each round ends by writing a handoff document, and the next round's Agent reads it and starts from scratch. Ironically, the knowledge management and handoff processes that human organizations spent decades optimizing were replicated by the AI community in a weekend hack.
Even more ironic: this "brute force method" works because the cost of LLM inference has dropped low enough to tolerate massive redundant computation. The premise of brute-force elegance is cheap compute, and that premise is becoming reality at an accelerating pace.
Codex /goal vs Ralph Loop: Marathon Runner vs Relay Race
Codex /goal and Ralph Loop share the same objective but take completely different implementation approaches.
Ralph Loop is like a relay race—each leg gets a new runner, and the previous runner's memory is passed via handoff documents. It's naturally fault-tolerant; any single round crashing doesn't affect the next.
Codex /goal is like a marathon—the same runner goes from start to finish, can pause when tired but never switches out. The goal stays active across rounds within the same session, with no need to spin up a new context.
But beneath this lies a deeper engineering trade-off: context continuity vs robustness. Marathon mode is more efficient, but once hallucinations or logical drift occur mid-run, errors accumulate and amplify within the same context. It's like the difference between single-threaded and multi-process programs: the former is efficient but crashes completely, while the latter is heavier but offers better isolation.
OpenAI chose efficiency first, which signals confidence in their model's context stability—or rather, they're making a bet.
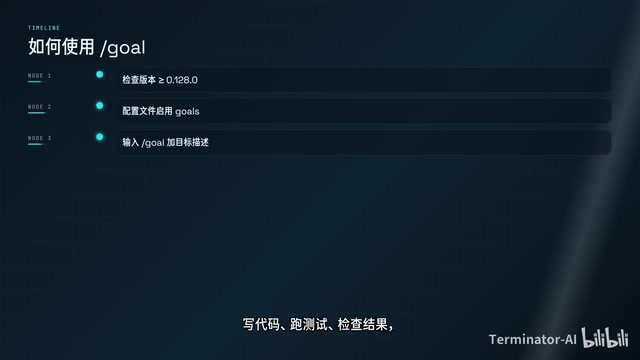
How to Use It: Command Details and Practical Tips
Basic Usage
First, you need Codex CLI version 0.128.0 or above, with the goals feature enabled in your configuration file.
Then simply type:
/goal your goal description
Codex will work continuously toward that goal: writing code, running tests, checking results, and automatically starting the next round if the goal isn't achieved.
Helper Commands
| Command | Function |
|---|---|
/goal pause | Pause the current goal |
/goal resume | Resume a paused goal |
/goal clear | Clear the goal |
Ctrl+C | Goal auto-pauses on interrupt; automatically resumes when session is restored |
What About Long Goals?
If the goal description is too long, write it in a Markdown file and use:
/goal follow instructions.md
This has an additional benefit—avoiding detail loss during context compression. This workaround actually exposes a fundamental weakness of current LLMs: no matter how large the context window, compression algorithms are still lossy. Users have to use the file system to compensate for the model's memory deficiencies. This scenario of "humans patching AI" is darkly humorous in itself.
/side Command: Temporary Branches That Don't Interrupt the Main Thread
The /side command is the most underrated design in this system. It lets you temporarily open a branch session to ask questions without interrupting the main goal. Press ESC to return to the main thread, and the branch session is discarded.
It essentially acknowledges a fact: even in goal-oriented workflows, humans still need the right to "interject." This isn't a technical issue—it's a psychological one. Humans can't fully let go.
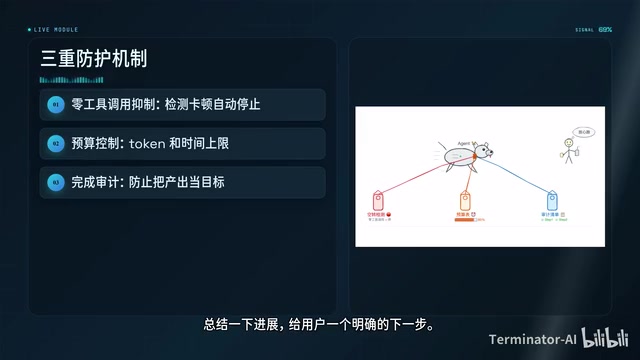
Three-Layer Protection Mechanism: Preventing Agent Idle Spinning and Self-Deception
The biggest fear with autonomous Agent loops is idle spinning or the Agent deceptively declaring "done." Codex designed three layers of protection for this:
Layer 1: Zero Tool Call Detection
If the Agent doesn't invoke any tools during a continuation round—no code written, no commands run, no files read—the system determines it's stuck and automatically stops the loop. Simple, crude, but effective.
Layer 2: Budget Control
Each goal can have a token budget and time limit. When the budget is exceeded, the system injects a prompt requiring the model to summarize current progress and suggest next steps, rather than continuing to blindly burn tokens.
Layer 3: Completion Audit Protocol
This is the most sophisticated layer. At the start of each continuation round, the system injects a hidden instruction requiring the model to:
- Decompose the goal into deliverables
- Establish a checklist
- Map requirements to actual evidence (files, outputs, test results)
- Not consider the goal complete merely because tests pass
This targets the most insidious failure mode in Agent loops—"proxy evidence acceptance." In plain terms, the model deceives itself: tests pass so the feature must be complete, files are generated so the goal must be achieved. This mirrors the human programmer's "works on my machine" mentality.
The difference is that humans have colleagues doing code review to course-correct, while Agents only have cold checklists. The deeper question is: who validates whether the checklist itself is complete? This is an infinite regression of trust. The current solution essentially "constrains probability with rules," but rules can never outrun probability's creativity.
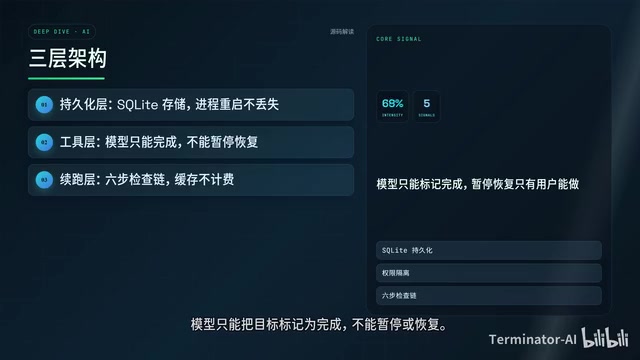
Source Code Breakdown: Three-Layer Architecture in 1570 Lines of Rust
The core logic of /goal lives in goal_state.rs, approximately 1570 lines of Rust code. The codebase isn't large, but design decisions are deliberate throughout.
Persistence Layer
Goal state is stored in a SQLite database—process restarts and thread recovery won't cause data loss. Goals have four states:
- In progress
- Paused
- Budget exhausted
- Completed
Tool Layer
Three tools are exposed to the model: read current goal, create goal, and update goal state.
There's a critical permission design here: the model can only mark a goal as "completed"—it cannot pause or resume. Only users can pause and resume. This is a deliberate cybernetic choice—giving the Agent autonomy to complete tasks while reserving humanity's ultimate power to "call stop." It prevents the model from slacking off and from overstepping its authority.
Continuation Layer
After each round ends, a six-step check chain executes:
- Is the goal feature enabled?
- Is there an active goal?
- Are other rounds currently running?
- Is there a pending message queue?
- Is continuation suppressed?
- Is it in Plan mode?
Only after all checks pass does the system inject the goal description, budget usage, and completion audit protocol to start the next round.
The Elegant Token Budget Design
Budget calculation only counts non-cached input tokens plus output tokens—cache hits don't count toward the budget. This means the budget tracks "new work done," and re-reading existing context is free.
This design essentially uses economics to guide model behavior—incentivizing the model to reuse existing context rather than regenerating redundantly. More elegant than any prompt engineering.
Current Limitations: Not Ready for Full Hands-Off Yet
/goal is still an experimental feature with several notable pitfalls:
1. CLI only: The Codex desktop app doesn't support it yet.
2. Infinite loop bug when API quota is exhausted: When API quota runs out, /goal falls into an awkward loop—continuously sending requests, continuously receiving quota-exhausted errors, then retrying. The community jokingly calls it the "Ralph Loop of Errors." When an Agent lacks self-awareness, "effort" becomes idle spinning.
3. Mutual exclusion with Plan mode: The goal system is automatically ignored in Plan mode; the two modes can't be used simultaneously.
4. Premature closure problem: The model sometimes declares the goal complete just because it produced some artifact, when only surface-level work was actually done. This isn't a technical bug—it's a side effect of RLHF training. The model is trained to please users, and "task complete" is the ultimate form of pleasing. Fixing this might require changes at the training paradigm level.
As a side note, the developer of this feature is Eric Traut—the creator of Pyright, the Python type checker. From helping humans write better code (type checking) to having AI write code for humans (Agent loops), his career trajectory is itself a metaphor for our era.
From How to What: A Paradigm Shift in Human-AI Collaboration
/goal isn't much code and isn't conceptually complex, but it changes the collaboration interface between humans and AI—from "you say one thing, I do one step" to "you set the goal, I handle everything," from conversation to delegation.
Viewing this through Karpathy's Software 3.0 concept, the evolution across three generations of software is really about how human participation changes:
| Phase | What humans do | Core action |
|---|---|---|
| Software 1.0 | Tell the machine how to do it | How |
| Software 2.0 | Show the machine how to do it | Show |
| Software 3.0 | Tell the machine what you want | What |
Traditional software automates what you can specify; AI automates what you can verify.
It's like the difference between navigation apps and hand-drawn maps. In the hand-drawn map era, you had to plan routes yourself and remember every intersection; in the navigation era, you just enter the destination. /goal is the "enter your destination" moment for programming.
But the navigation analogy has a fatal blind spot—a navigation destination is unambiguous (an address), while software development "goals" are often vague, contradictory, and constantly changing. The real challenge was never "getting the Agent to reach the finish line" but "defining where the finish line is."
User experience, code elegance, long-term architectural maintainability—these "soft goals" are the soul of software engineering. /goal can pass tests, but can it pass code aesthetics? The answer to this question determines whether the programming profession dies or evolves.
Final Thoughts
As a developer who has essentially stopped writing code by hand in practice, I increasingly feel my energy goes toward two things: defining goals and verifying whether goals are truly achieved.
When Agents can manage their own progress and achieve goals, the only thing humans need to do well is—figure out what they actually want.
The ultimate irony of AI Agents is this: the more autonomously they can achieve goals, the more they expose that humanity's scarcest capability isn't execution but definition—knowing what you truly want has always been the hardest engineering problem.
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesDemystifying Transformer: A Word-Continuation Function, Deconstructed
Understand Transformer through the lens of word continuation. Breaking down language generation into Embedding, Transformer Block, and Probability output modules for intuitive understanding.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.