DeepSeek V4-Pro Permanent Price Cut: Lower Developer Costs as LLM Price War Heats Up
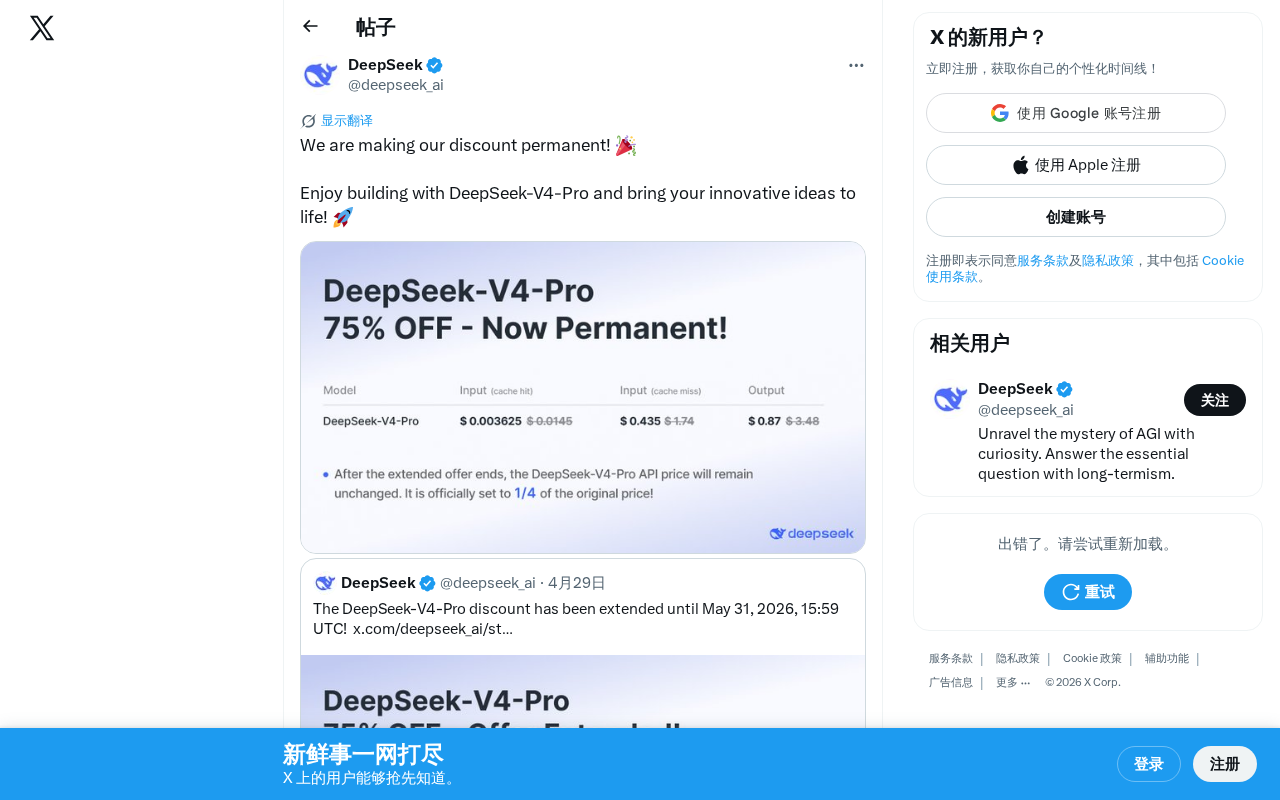
DeepSeek makes V4-Pro model discount pricing permanent
DeepSeek has announced that the limited-time discount pricing for its V4-Pro model is now permanent, continuously lowering costs for developers. The company's pricing confidence stems from the inference efficiency advantages of its MoE architecture, which maintains high performance while controlling compute overhead. This move marks another escalation in the LLM industry price war, aiming to attract more developers through economies of scale and solidify DeepSeek's high cost-performance market positioning.
DeepSeek Makes Discount Pricing Permanent
DeepSeek recently announced a major update on social media: the discounted pricing previously offered for the DeepSeek-V4-Pro model will now be permanent, no longer a limited-time promotion. This means developers can continue building applications with this high-performance LLM at a consistently lower cost.
What the Permanent Price Cut Means for Developers
Lowering the Barrier to AI Application Development
As competition in LLM API pricing intensifies, DeepSeek's decision to make its discounts permanent sends a clear signal: attracting more developers into its ecosystem through pricing advantages. For startups and independent developers, API call costs are often a critical factor in whether a project can sustain operations.
It's worth understanding that LLM APIs typically charge by token, split into input tokens and output tokens. A token is the basic unit of text processing for models — roughly 750 English words correspond to 1,000 tokens, with slight variations for Chinese due to character density differences. The core of the price war is the cost per million tokens. A permanent price reduction means developers can confidently include DeepSeek-V4-Pro in their long-term planning during technical evaluation and budgeting, without worrying about costs spiking after a promotion expires — a certainty that's especially critical for high-volume production applications.
V4-Pro's Core Competitive Advantages
As DeepSeek's latest flagship model, DeepSeek-V4-Pro excels in reasoning, code generation, and multi-turn conversations. To understand the confidence behind its pricing, you need to know DeepSeek's technical approach: the DeepSeek model series employs a Mixture of Experts (MoE) architecture, which activates only a subset of parameter networks during inference rather than the full parameter set. This dramatically reduces computational overhead per inference while maintaining the model's overall capacity. Combined with reinforcement learning training methods, DeepSeek achieves performance comparable to GPT-4o and Claude 3.5 Sonnet on multiple international benchmarks, but at significantly lower training and inference costs — this is precisely the technical foundation enabling its sustained low-price strategy.
DeepSeek had already established a reputation for "high cost-performance" with its V3 and R1 series models, and the permanent V4-Pro price cut further solidifies this positioning. In competition with international players like OpenAI, Anthropic, and Google, as well as numerous domestic LLM providers, pricing strategy is undoubtedly one of DeepSeek's strongest cards.
The LLM Price War Continues to Intensify
The price war in the LLM industry has become the norm. From OpenAI launching the more cost-effective GPT-4o mini to domestic providers slashing prices or even offering free tiers, the entire industry is competing for developers by lowering barriers to entry. DeepSeek's conversion of a temporary discount into permanent pricing can be seen as yet another landmark move in this price war.
From a business logic perspective, this strategy is driven by economies of scale. In the cost structure of LLM inference services, GPU compute rental and data center operations are the primary expenses, representing relatively high fixed costs. As call volume increases, the marginal cost per inference continues to decline as infrastructure utilization improves. By attracting more call volume through lower prices, companies can not only spread infrastructure costs but also accumulate more real user data for model iteration and optimization, creating a positive feedback loop between technology and business while building a larger developer community and application ecosystem. For a company like DeepSeek — with strong technical capabilities but still growing brand awareness — this is a pragmatic growth path.
Summary: How Developers Can Seize This Opportunity
Although the official announcement was brief and didn't disclose specific price figures or discount percentages, "permanent price cut" itself is a signal worth noting. It indicates DeepSeek's strong confidence in its cost control capabilities — confidence rooted in the inference efficiency advantages of the MoE architecture, and reflecting the company's long-term thinking on commercialization strategy.
For developers currently choosing an LLM API, DeepSeek-V4-Pro's permanently discounted pricing undoubtedly increases its appeal. Developers with relevant needs are encouraged to follow DeepSeek's official platform for specific pricing details and usage information, and to convert this cost advantage into product competitiveness as early as possible.
Key Takeaways
- DeepSeek announced that V4-Pro model discount pricing is now permanent, no longer a limited-time offer
- The permanent price cut lowers developers' long-term costs, helping attract more developers into the DeepSeek ecosystem
- DeepSeek's low-price confidence stems from the inference efficiency advantages of its MoE architecture, enabling high performance while controlling compute costs
- This move is another landmark action in the escalating LLM industry price war, driven by economies-of-scale business logic
- DeepSeek is using pricing strategy to solidify its "high cost-performance" market positioning, competing with domestic and international rivals for developers
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.