Essential Skills for LLM Engineers: A Complete Guide to Application Development and Fine-Tuning
LLM engineers need to master both application development and fine-tuning/training.
The LLM engineer skill set consists of two main tracks: business-facing application development (RAG, Agent, Workflow) and model-facing fine-tuning/training (SFT, RLHF, distillation, quantization). Developers from different backgrounds can choose different entry points — backend developers should start with application development, AI algorithm engineers with fine-tuning, and career changers with application development first. Ultimately, both competencies are essential.
Introduction
With the rise of domestic large language models like DeepSeek R1, more and more developers are eager to master LLM-related skills. However, faced with a vast and complex technology stack, many don't know where to start. Based on insights shared by a senior engineer with over a decade of experience in the algorithm field, this article systematically outlines the core skill set that LLM engineers need to master, helping developers from different backgrounds find the learning path that suits them best.
Two Core Competencies of an LLM Engineer
To become a qualified LLM engineer, you need to develop two key competencies simultaneously: application development and fine-tuning/training. Together, these form the complete skill map for an LLM engineer.
LLM-Based Application Development
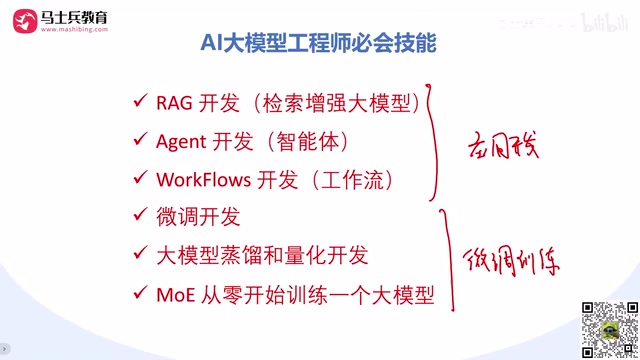
Application development is the front line of bringing LLMs into production. It primarily involves the following technical areas:
- RAG (Retrieval-Augmented Generation) Development: Combining external knowledge bases with LLMs to improve the accuracy and timeliness of responses
- Agent Development: Building AI agents with autonomous decision-making and tool-calling capabilities
- Workflow Development: Designing complex multi-step AI processing pipelines
In terms of specific technology stacks, frameworks like MCP (Model Context Protocol), LangGraph, and LangChain are the current mainstream choices. Additionally, low-code tools such as Dify and Coze also fall under the application development category and are well-suited for rapid prototyping and validation.
For engineers with backend development experience, application development is relatively easy to pick up, since it essentially builds on existing programming skills by learning how to interact with and orchestrate LLM APIs.
LLM Fine-Tuning and Training
Fine-tuning and training represent the core competitive advantage of an LLM engineer, involving significantly greater technical depth:

- Pre-training: Understanding how LLMs learn general knowledge from massive internet data
- Supervised Fine-Tuning (SFT): Optimizing the model for specific tasks using labeled data
- Reinforcement Learning from Human Feedback (RLHF): Further aligning model outputs through human preference data
- Model Distillation: Compressing the capabilities of a large model into a smaller one to reduce inference costs
- Quantization: Reducing model size to lower deployment costs
- MOE Architecture Training: Building Mixture of Experts models from scratch

For developers with an AI algorithm engineering background, the fine-tuning and training portion is easier to get started with, since they already have a theoretical foundation in machine learning and deep learning.
The Core Logic of Fine-Tuning
Why Is Fine-Tuning Necessary?
Open-source LLMs (such as DeepSeek R1) are pre-trained on massive internet data and possess strong general capabilities. However, enterprises often have their own proprietary data and specific business scenarios. While this data is far smaller in volume than pre-training data, it is extremely valuable.
The essence of fine-tuning is: making minor adjustments to the pre-trained model's parameters using enterprise-specific data to activate the model's capabilities in a particular domain.
Mainstream LLM Architectures: Dense vs. MOE
Current mainstream LLM architectures fall into two categories:
- Dense Architecture: All parameters participate in computation during every inference pass — simple in structure but computationally expensive
- MOE (Mixture of Experts) Architecture: Only a subset of expert networks are activated, improving computational efficiency while maintaining model capacity
Models like Qwen and DeepSeek both offer MOE-based versions. Taking DeepSeek R1 as an example, it provides both a full version and distilled versions. The distilled versions transfer the reasoning capabilities of the large model to smaller models, making local deployment and usage more practical.
Recommended Learning Paths for Developers with Different Backgrounds
| Background | Recommended Starting Direction | Reason |
|---|---|---|
| Java/Backend Development | Application Development (RAG, Agent) | Strong programming foundation; API integration and system architecture design are existing strengths |
| AI Algorithm Engineer | Fine-Tuning & Training (SFT, RLHF) | Already has ML/DL theoretical foundation and understands model training workflows |
| Career Changer (No Prior Experience) | Application Development first, then Fine-Tuning | Application development has a lower barrier to entry and allows for quick, tangible results |
It's important to emphasize that for LLM engineer positions, both competencies need to be mastered. This is especially true for interviews at major tech companies, which often assess the ability to train models from scratch — because this demonstrates a deep understanding of underlying principles and training processes.
Conclusion
The skill set for LLM engineers isn't as complex as it might seem on the surface. At its core, there are two tracks: the business-facing application development track (RAG, Agent, Workflow) and the model-facing fine-tuning and training track (SFT, RLHF, distillation, quantization). Choosing an entry point that matches your background and progressively expanding your skill tree is the most efficient learning strategy. With the open-sourcing of domestic models like DeepSeek, the barriers to local deployment and fine-tuning are continuously decreasing — now is the perfect time to get started.
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.