Fable 5 Lands on Augment Code: A Premium Coding Model Priced at 2x Claude Opus 4.7
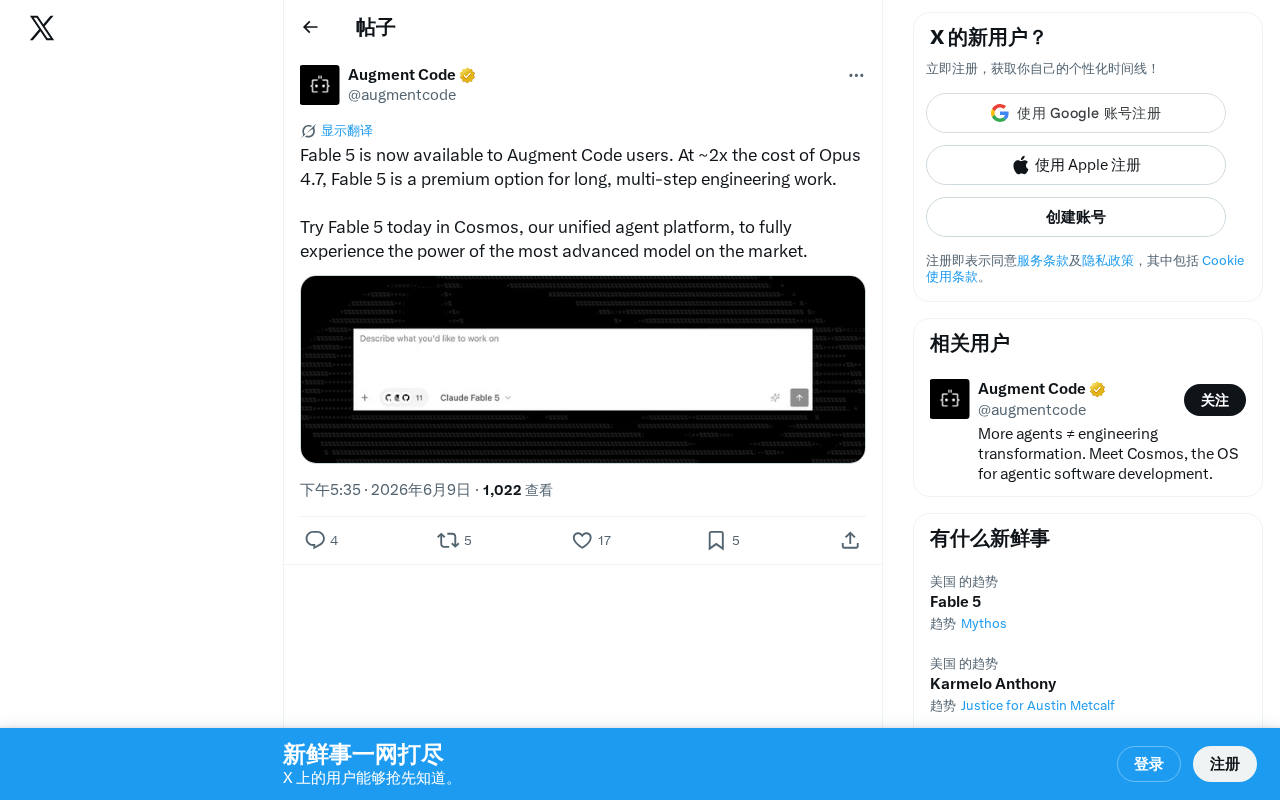
Fable 5 debuts on Augment Code at 2x Opus 4.7 pricing, targeting complex multi-step engineering tasks.
Augment Code has launched Fable 5 on its Cosmos unified agent platform, pricing it at approximately twice Claude Opus 4.7. The model targets long-chain, multi-step engineering tasks like large-scale refactoring and end-to-end project building. This signals a shift toward tiered pricing in AI coding tools and expanding competition beyond benchmarks into vertical specialization.
Fable 5 Officially Launches on the Augment Code Platform
Augment Code recently announced that its platform has officially integrated the Fable 5 model, offering developers a premium AI coding option designed for complex engineering tasks. According to official information, Fable 5's usage cost is approximately twice that of Claude Opus 4.7, positioning it as one of the most advanced code generation models currently on the market.
Users can experience the full capabilities of Fable 5 through Augment Code's Cosmos unified agent platform. This release marks a new phase in the AI coding tools market — premium models are now commanding significant price premiums in exchange for stronger engineering capabilities.
Fable 5's Core Positioning: Long-Chain Multi-Step Engineering Tasks
Based on the official description, Fable 5's core selling point lies in its ability to handle long-chain, multi-step engineering work. This means it's not designed for simple code completion or single-function generation, but rather targets the following scenarios:
- Large-scale code refactoring: Systematic changes spanning multiple files and modules
- Complex feature development: Engineering tasks requiring contextual understanding, step-by-step planning, and incremental implementation
- End-to-end project building: Complete development workflows from requirements analysis to code implementation
These tasks place extremely high demands on a model's contextual understanding, long-range reasoning, and code consistency maintenance capabilities — areas where current mainstream coding models (such as Claude Opus, GPT-4, etc.) still have notable shortcomings.
Why Multi-Step Engineering Tasks Are So Difficult
Long-chain multi-step engineering tasks represent one of the most challenging capability dimensions in current AI coding. Traditional code completion models (like early Copilot) primarily rely on local context for predictions, with effective context windows typically covering only a few hundred lines of the current file. Multi-step engineering tasks require three core capabilities from a model: first, global context awareness — understanding the entire codebase's architecture, dependencies, and design patterns; second, task decomposition and planning — breaking down complex requirements into ordered implementation steps; third, cross-step consistency maintenance — ensuring that code generated across steps remains consistent in interface definitions, naming conventions, and logical semantics. The difficulty lies in the fact that each step's decisions affect the feasibility of subsequent steps, requiring the model to continuously maintain a "mental model" throughout generation to track overall progress and constraints. If Fable 5's claimed breakthrough in this dimension proves true, it would represent a qualitative leap in AI coding capabilities.
Pricing Strategy: What 2x Opus 4.7 Really Means
Pricing at approximately 2x Opus 4.7 is a noteworthy signal. The Claude Opus series is already Anthropic's flagship model tier, with pricing at the higher end of the industry. Fable 5's decision to charge a further premium on top of this conveys several key messages:
Opus Series Market Position and Pricing Reference
Claude Opus is Anthropic's flagship large language model series, sitting at the highest tier in their product line (Haiku < Sonnet < Opus). Taking Claude Opus 4 as an example, its API pricing is $15/million tokens for input and $75/million tokens for output — several times that of the Sonnet series. The Opus series is designed to deliver the best performance on the most complex reasoning, analysis, and creative tasks, particularly excelling in scenarios requiring deep thinking and multi-turn reasoning. The version number "Opus 4.7" suggests this may be an iterative update to the Opus 4 series. Fable 5 being priced at approximately twice this means that in the current market, a single complex task call with Fable 5 could cost several dollars — steep for individual developers, but for enterprise software engineering teams, if it can compress hours of refactoring work into minutes, the ROI remains extremely attractive.
First, real demand exists in the premium market. For professional development teams, the efficiency gains from marginal improvements in model capability often far exceed the increase in model invocation costs. If Fable 5 can genuinely outperform Opus 4.7 significantly on complex engineering tasks, then 2x the price is entirely acceptable for enterprise users.
Second, AI coding tools are moving toward tiered pricing. Similar to the pricing logic of different instance types in cloud computing, AI coding models are beginning to tier based on task complexity and model capability. Lightweight models for simple tasks, premium models for complex tasks — this on-demand selection pattern will become the norm.
Third, the dimensions of model competition are expanding. It's no longer just about benchmark scores, but about establishing differentiated advantages in specific vertical scenarios (such as multi-step engineering tasks).
Cosmos Platform: The Unified Agent Product Ambition
Augment Code has integrated Fable 5 into its Cosmos platform, defining it as a "unified agent platform." This architectural design hints at Augment Code's broader product vision:
Rather than simply providing a model API, the goal is to build a platform capable of orchestrating multiple AI agents working collaboratively. Under this architecture, Fable 5 likely serves as the core reasoning engine, working alongside other specialized agents (such as code review, test generation, documentation writing, etc.) to collectively complete complex software engineering tasks.
Technical Architecture of Multi-Agent Collaboration
The core idea behind a unified agent platform stems from Multi-Agent System (MAS) theory: distributing complex tasks to multiple AI agents with different specializations, achieving collaborative work through coordination mechanisms. In software engineering scenarios, this means an "architect agent" handles task planning and decomposition, a "coding agent" handles code generation, a "review agent" handles code quality checks, and a "testing agent" handles generating and executing test cases. The advantage of this architecture is that each agent can be optimized for its specific responsibility, while a unified orchestration layer ensures overall collaboration efficiency. In comparison, single-model approaches require one model to excel at all roles simultaneously, often resulting in weaknesses in certain areas. The Cosmos platform's design clearly adopts this philosophy, with Fable 5 serving as the most powerful reasoning engine, taking on the most critical responsibilities of code generation and architectural decision-making.
This aligns closely with the current industry trend of "AI coding evolving from point tools to system platforms." Products like Cursor, Windsurf, and Devin are all evolving in similar directions.
The Three-Stage Evolution of AI Coding Tools
The evolution of AI coding tools has gone through three distinct stages: the first stage was code completion tools (2021-2022), represented by GitHub Copilot, primarily offering line-level or function-level code suggestions; the second stage was conversational coding assistants (2023-2024), represented by ChatGPT, Claude, etc., supporting code generation and modification through natural language dialogue; the third stage is autonomous coding agents (2024-present), represented by Devin, Cursor Agent, Windsurf, etc., capable of autonomously executing multi-step development tasks including reading codebases, writing code, running tests, and fixing bugs. Cursor achieves a smooth human-AI collaboration experience through deep IDE integration, Devin attempts to build a fully autonomous AI software engineer, and Windsurf (formerly Codeium) emphasizes deep understanding of entire codebases. Augment Code's Cosmos platform clearly belongs to the third stage, and by introducing premium models like Fable 5, it's attempting to establish competitive moats in autonomous engineering capabilities.
Industry Impact and Outlook
The release of Fable 5 offers several insights for the AI coding field:
- The competitive landscape among model providers is shifting — beyond OpenAI and Anthropic, new model providers are entering the market through deep optimization in vertical domains.
- The "most expensive equals best" logic still holds in professional scenarios — enterprise users care more about ROI than absolute cost.
- Evaluation criteria for AI coding tools need updating — code generation accuracy alone is no longer sufficient to measure model value; completion quality and consistency on multi-step tasks will become more important metrics.
For developers, whether Fable 5 is worth its premium ultimately depends on real-world performance. Teams with complex engineering needs are advised to conduct hands-on testing on the Cosmos platform and compare against existing Opus 4.7 workflows.
Key Takeaways
Related articles

A Gen-Z Woman Making $1.5M/Month: Deconstructing the Growth Methodology Behind AI Apps
Gen-Z indie dev Nicole built 4 hit AI apps earning $1.5M/mo. Deep dive into her industrialized UGC engine, traffic testing system, and minimalist tech stack.
Replit's AI Loops Workflow Explained: Multi-Agent Collaboration Replaces Prompt Engineering
Deep dive into Replit's AI Loops workflow: how orchestrators, parallel agents, and Computer Use Verifiers build automated closed-loop systems through multi-agent collaboration.
Claude Code + Skills: A Practical Guide to AI-Powered Test Case Generation
Learn how to use Claude Code + Skills to auto-generate enterprise-grade test cases. Covers AI Agent vs LLM differences, the four core capabilities, and the complete workflow from requirements to test cases.