Fable 5 Released: An AI Coding Tool Built for Complex Software Engineering
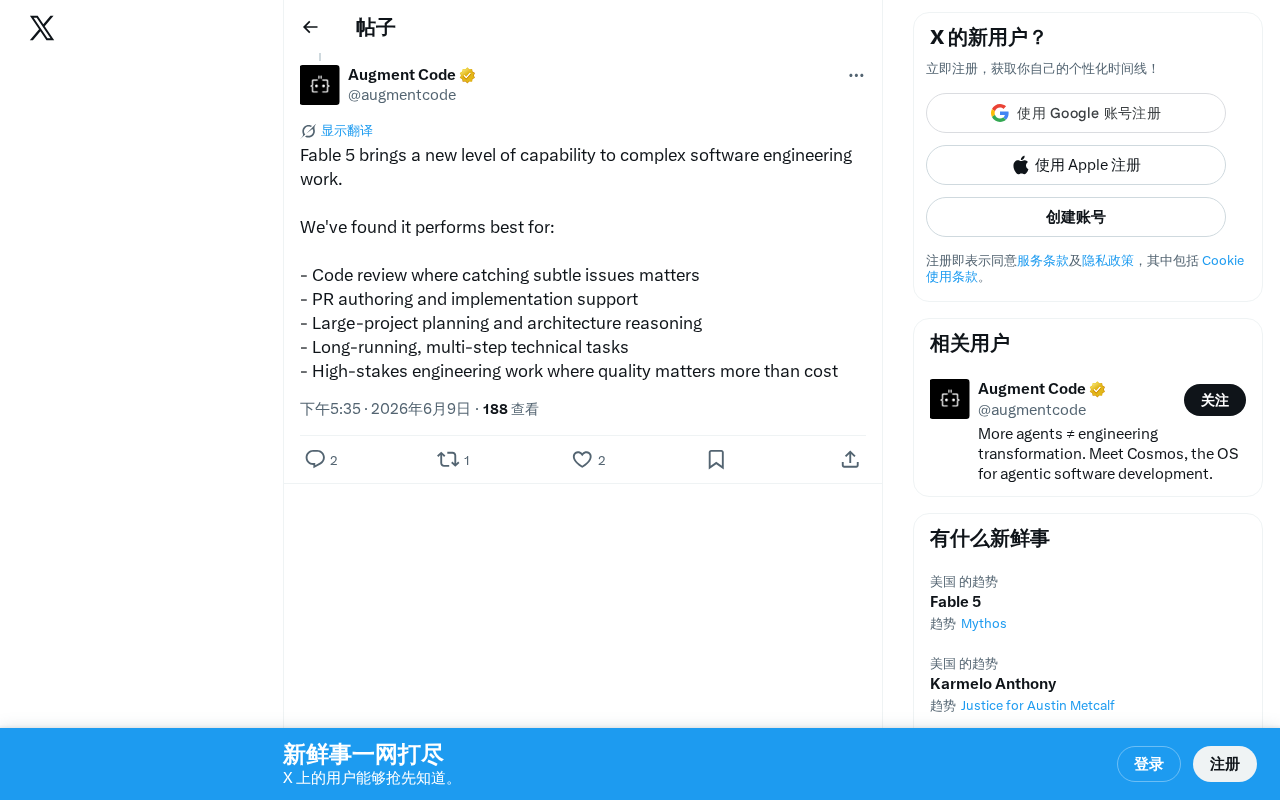
Fable 5 launches as an AI coding tool purpose-built for complex software engineering tasks.
Fable 5 has officially launched, positioning itself for high-complexity software engineering scenarios. It features five core capabilities: subtle code review, PR writing and implementation support, large-scale project planning and architectural reasoning, long-cycle multi-step task orchestration, and high-stakes engineering support. Unlike Cursor and Copilot which focus on general coding assistance, Fable 5 targets enterprise-grade engineering where quality outweighs cost.
Fable 5 Officially Debuts: Targeting High-Difficulty Software Engineering Scenarios
The AI coding tool arena has a new contender. Recently, the Fable team officially announced Fable 5 on social media, claiming it brings "an entirely new level of capability" to complex software engineering work. Unlike the many AI coding assistants on the market that pursue general-purpose functionality, Fable 5 explicitly positions itself for high-quality, high-complexity engineering tasks rather than simple code completion.
Five Core Capabilities: From Code Review to Architectural Reasoning
According to official information, Fable 5 excels in the following five scenarios:
1. Code Review: Catching Subtle Issues
Fable 5 emphasizes its code review capabilities, particularly its ability to catch subtle issues that are easily overlooked by human eyes. It goes beyond syntax checking or style convention validation to understand deep potential defects in code logic—such as missed boundary conditions, concurrency race conditions, and hidden performance bottlenecks. This type of capability is critical for quality control in large team collaborations.
Code review, as one of the core practices in software engineering, traces its history back to IBM's Fagan inspection method in the 1970s. Modern code review is typically conducted through Pull Request mechanisms on version control platforms. Research shows that manual review can detect an average of 60-70% of defects, but review quality is highly dependent on the reviewer's experience and attention. Race conditions and boundary condition omissions are particularly difficult to catch through manual review because they require systematic reasoning about program execution timing and state space. Traditional static analysis tools (such as SonarQube and CodeQL) can detect some pattern-based issues but have limited capability for semantic-level logic defect detection. Fable 5 attempts to achieve a breakthrough in this capability dimension by bringing deep semantic understanding into automated review workflows.
2. PR Writing and Implementation Support
Pull Request (PR) writing and implementation support is another key focus for Fable 5. In actual development workflows, PRs require not only code changes but also clear descriptions, reasonable decomposition, and complete test coverage. Fable 5 can assist developers throughout the entire process from PR description writing to concrete code implementation, directly improving team collaboration efficiency.
The PR mechanism was first popularized by GitHub in 2008 and has since become the core workflow for modern software development collaboration. Google's engineering practice research shows that PR size is negatively correlated with review efficiency—review quality drops significantly for PRs exceeding 400 lines of changes. Therefore, reasonable PR decomposition (breaking large changes into logically independent small PRs) is itself an important engineering skill. Current AI tool attempts in PR assistance include GitHub Copilot's automatic PR Summary generation and change impact analysis, but end-to-end support from PR planning and decomposition strategy to complete implementation is still in its early stages. Fable 5's deeper investment in this direction means it's trying to cover more complete segments of developers' daily workflows.
3. Large-Scale Project Planning and Architectural Reasoning
Large-scale project planning and architectural reasoning is one of Fable 5's most noteworthy capabilities. Most current AI coding tools excel at function-level or file-level tasks but often fall short when it comes to reasoning at the macro level—involving entire project architecture design, module decomposition, and technology selection. Fable 5 claims to be capable of working at this level, and if true, this would represent a significant breakthrough in the capability boundaries of AI coding tools.
Software architectural reasoning is difficult because it requires comprehensive consideration of functional requirements, non-functional requirements (performance, scalability, maintainability), team capabilities, technical debt, and other multidimensional factors, while making judgments among multiple trade-offs. The core challenge facing current large language models is context window limitations—a mid-sized project may contain hundreds of thousands of lines of code and hundreds of files, far exceeding the token capacity of a single inference pass. Additionally, architectural decisions often have no single correct answer and require deep reasoning capabilities beyond pattern matching. Current industry exploration directions include code graph construction, hierarchical summarization, and Retrieval-Augmented Generation (RAG) techniques, and Fable 5 likely innovates in these areas.
4. Long-Cycle Multi-Step Technical Tasks
Many tasks in software engineering cannot be completed in a single step but require continuous reasoning and execution across multiple steps. For example, a large-scale code refactoring might involve dependency analysis, interface modification, test updates, and other stages. Fable 5 has been specifically optimized for these long-cycle, multi-step tasks, with stronger context retention and task decomposition capabilities.
These tasks pose two core technical challenges for AI systems: first, Context Retention—maintaining accurate memory of prior information across multiple interaction rounds or long-sequence reasoning; second, Task Decomposition—breaking complex goals into executable sub-task sequences. In large-scale refactoring scenarios, the system needs to first build a Dependency Graph, identify change propagation paths, then execute modifications step by step in topological order while ensuring that the intermediate state at each step still maintains system compilation and test passing. This type of capability is closely related to the currently popular Agent architecture—completing complex tasks through cycles of Planning, Execution, and Reflection. OpenAI's o1/o3 series reasoning models, Anthropic's Claude, and coding Agents like Devin are all actively exploring this direction.
5. High-Stakes Engineering Scenarios
The final point is particularly noteworthy: Fable 5 explicitly states it's suitable for high-stakes engineering scenarios where "quality matters more than cost." This positioning suggests it may employ larger-scale models or more complex reasoning pipelines, potentially costing more in inference than competitors, but delivering higher output quality and reliability in return.
In domains such as financial trading systems, medical device software, and aerospace control systems, a tiny code defect could lead to losses of millions of dollars or even endanger lives. These scenarios demand code quality far exceeding that of ordinary application development, traditionally relying on rigorous formal verification, multiple rounds of manual review, and extensive testing for assurance. Fable 5's targeting of this market means it needs to achieve extremely high standards in output accuracy and reliability, while potentially needing to provide explainability—letting developers understand the AI's reasoning process and decision basis.
Market Positioning Analysis: Differentiated Competition with Cursor and Copilot
From Fable 5's feature descriptions, its market strategy is very clear—rather than competing with Cursor, GitHub Copilot, and similar tools in the red ocean of daily coding assistance, it targets enterprise-grade, high-complexity software engineering scenarios.
The current AI coding tool market has formed a multi-tiered competitive landscape. The first tier consists of general-purpose coding assistants represented by GitHub Copilot (based on OpenAI Codex/GPT-4) and Cursor (an intelligent IDE integrating multiple models), primarily serving daily code completion and generation scenarios with user bases reaching millions. The second tier includes autonomous coding Agents represented by Devin and SWE-Agent, which attempt to independently complete full development tasks. The third tier consists of vertical tools targeting specific scenarios, such as Snyk (security scanning) and Qodo (test generation). In terms of benchmarks, SWE-bench has become one of the industry standards for evaluating AI coding capabilities, containing software engineering problems from real GitHub repositories, with current best models achieving solution rates of approximately 50%. Fable 5's positioning appears to sit between autonomous Agents and vertical tools, focusing on deep capabilities for high-complexity engineering scenarios.
This positioning has its merits. As AI coding tools become widespread, simple code completion and generation have become increasingly commoditized, and true differentiated value lies in the ability to handle more complex, more critical engineering tasks. Architecture-level reasoning, cross-file code review, and multi-step task orchestration—these are precisely the current shortcomings of AI coding tools.
However, publicly available information about Fable 5 remains limited. The team has not yet disclosed specific technical architecture, underlying model choices, pricing strategy, or actual benchmark data. For the statement that "quality matters more than cost," the developer community also needs more real-world cases to verify its actual performance.
Outlook: AI Coding Tools Moving from "Writing Code" to "Doing Engineering"
The release of Fable 5 reflects an important trend in the AI coding tool space: a capability leap from "writing code" to "doing engineering." Future AI coding assistants need to not only generate code snippets but also understand the project holistically, participate in architectural decisions, and ensure engineering quality. Behind this trend is the continuous improvement of large language model reasoning capabilities and the gradual maturation of Agent frameworks in engineering practice.
From a broader perspective, the essence of software engineering is not just writing code but managing complexity. The distinction between "essential complexity" and "accidental complexity" proposed by Brooks in The Mythical Man-Month remains applicable today—AI tools have already made significant progress in eliminating accidental complexity (such as syntax errors and boilerplate code), while next-generation tools like Fable 5 are attempting to touch the boundaries of essential complexity, helping developers address fundamental challenges in system design, module interaction, and long-term evolution.
For developers following the AI coding space, Fable 5 is worth continued attention. Its actual performance in complex engineering scenarios will serve as an important reference for testing the capability ceiling of this generation of AI coding tools.
Key Takeaways
Related articles

A Gen-Z Woman Making $1.5M/Month: Deconstructing the Growth Methodology Behind AI Apps
Gen-Z indie dev Nicole built 4 hit AI apps earning $1.5M/mo. Deep dive into her industrialized UGC engine, traffic testing system, and minimalist tech stack.
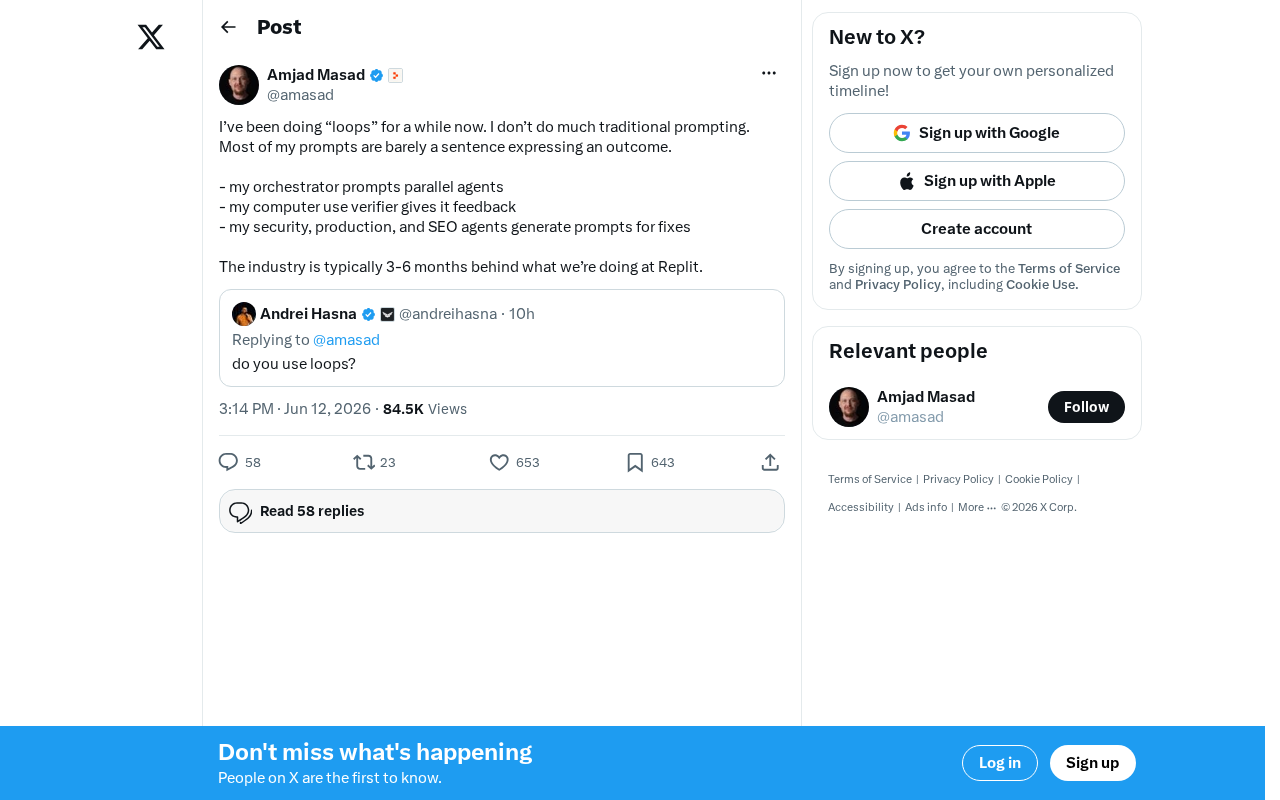
Replit's AI Loops Workflow Explained: Multi-Agent Collaboration Replaces Prompt Engineering
Deep dive into Replit's AI Loops workflow: how orchestrators, parallel agents, and Computer Use Verifiers build automated closed-loop systems through multi-agent collaboration.
Claude Code + Skills: A Practical Guide to AI-Powered Test Case Generation
Learn how to use Claude Code + Skills to auto-generate enterprise-grade test cases. Covers AI Agent vs LLM differences, the four core capabilities, and the complete workflow from requirements to test cases.