Frontier Code Deep Dive: Code That Runs ≠ Code That Merges — A Quality Revolution in Programming Benchmarks
Frontier Code benchmark shows code that passes tests still fails real-world code review standards.
Cognition's Frontier Code benchmark redefines programming evaluation by asking whether AI-generated code is truly mergeable, not just functional. With six quality dimensions, a five-stage QC process, and an 81% reduction in false positives vs. SWE-Bench Pro, it reveals that even top models like Claude 3.5 Sonnet score only 13.4% on the hardest tasks — exposing code quality as AI programming's next major bottleneck.
The Fundamental Flaw in Programming Benchmarks: Passing Tests ≠ Mergeable
Cognition recently released a new programming benchmark called Frontier Code, and its core philosophy strikes at the heart of current programming evaluation shortcomings — most benchmarks only care whether model-generated code can pass tests, but Frontier Code asks a far more demanding question: Would a project maintainer actually merge this PR?
In modern software development, Pull Requests (PRs) are the core mechanism of collaborative workflows. After completing code changes, developers don't push directly to the main branch — instead, they create a PR requesting project maintainers to review and merge the changes. Maintainers evaluate submissions across multiple dimensions including code style, architectural consistency, test coverage, and performance impact. PRs that don't meet standards are sent back for revision or closed outright. In large open-source projects, the merge rate is typically far lower than the submission rate, making "mergeability" a much higher quality bar than mere "functional correctness."
This distinction is critical. A patch can pass all existing tests and still be poor quality: overly broad changes, modifications to unrelated files, low-quality tests, ignored code style conventions, or fixes that solve the immediate problem but make future maintenance harder. In real code reviews, maintainers routinely reject such code — but traditional programming benchmarks are completely blind to these issues.
Evaluation Framework: Three Nested Subsets and Dual Metrics
Frontier Code includes three nested subsets covering different difficulty tiers:
- Extended: The complete benchmark with 150 tasks, including easier ones
- Main: The hardest 100 tasks from the set
- Diamond: The most rigorous 50 tasks
The test report includes two core metrics: pass rate and score. Pass rate is a binary judgment — if any single "blocking factor" (an issue maintainers consider a hard red line) is unmet, the attempt is marked as failed. The score is a weighted sum of all evaluation criteria, but critically: if a solution fails to satisfy any blocking factor, the score drops straight to zero.
Each model is run five times at each reasoning effort level and averaged, with charts showing the model's best-performing reasoning effort setting.
Diamond-Level Results: Even the Best Models Barely Pass
In the most rigorous Diamond subset, the results are sobering:
| Model | Score | Pass Rate |
|---|---|---|
| Claude 3.5 Sonnet | 13.4% | 14.5% |
| GPT-4o | 6.3% | 7.2% |
| Claude 3.0 Opus | 5.2% | — |
| Gemini 1.5 Pro | 4.7% | — |
| GPT-4o Mini | 4.6% | — |
| Kimi K2.6 | 3.8% | — |
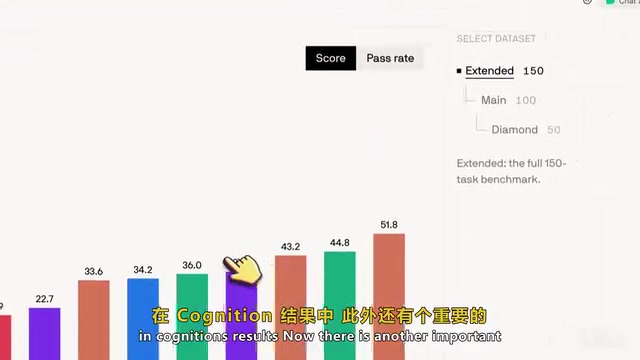
Even the best-performing model can only solve a tiny fraction of tasks. This is exactly what the benchmark was designed for — the hardest 50 tasks are far from saturated.
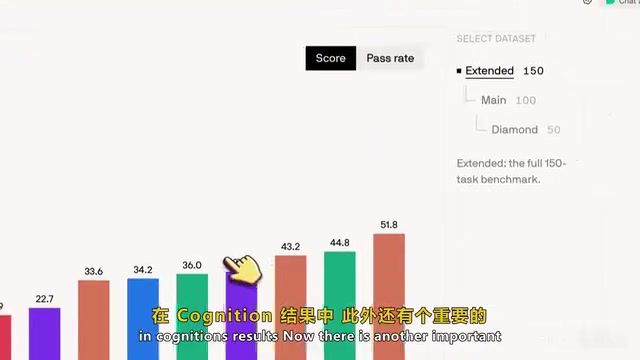
The efficiency dimension is worth noting. While Claude 3.5 Sonnet achieved the highest score at the Diamond level, it came at a steep cost: approximately 70,000 output tokens per run, averaging about $8 per attempt, with each inference taking roughly 7.7 minutes and requiring about 83 tool calls. In LLM usage, tokens are the fundamental unit for billing and measuring computation — one token corresponds to roughly 3/4 of an English word or 1-2 Chinese characters. Output tokens typically cost 3-6x more than input tokens because generation requires autoregressive inference token by token. When a coding agent tackles complex tasks, it needs to invoke tools multiple times (reading files, executing commands, searching codebases), with each interaction accumulating token consumption. 70,000 output tokens translating to roughly $8 can quickly add up to significant expenses in enterprise-scale deployments, making token efficiency a critical dimension for evaluating coding agent practicality. By comparison, GPT-5.5 scored slightly lower but consumed less than a quarter of the tokens. This means there's a clear trade-off between cost and performance.
Another important detail: not all models use the same test environment. OpenAI models use Codex, Gemini models use Gemini CLI, open-source models use Mini Agent, and Devon is used for SWE-Bench. Therefore, this benchmark measures the combined performance of model and agent environment.
Why Older Benchmarks Fall Short: False Positive vs. False Negative Rates
In the context of programming benchmarks, false positives and false negatives borrow from the hypothesis testing framework in statistics. A false positive means the benchmark accepts a solution that is actually incorrect (typically due to incomplete test coverage), while a false negative means the benchmark rejects a solution that is actually correct (typically due to overly rigid test requirements). A high false positive rate means the benchmark "lets through" flawed code, leading to overestimation of model capabilities; a high false negative rate means the benchmark is too rigid, rejecting solutions that use different but equally valid implementation approaches, leading to underestimation of true model capability. An ideal benchmark should keep both rates low.
| Benchmark | False Positive Rate | False Negative Rate |
|---|---|---|
| SWE-Bench Pro | 36.0% | 6.8% |
| DeepSuite | 44.9% | 1.2% |
| TerminalBench 2.0 | 6.8% | 5.9% |
| TerminalBench 2.1 | 5.6% | 2.8% |
| Frontier Code | 6.9% | — |
Frontier Code's false positive rate is approximately 81% lower than SWE-Bench Pro's (from 36.0% down to 6.9%). It's worth noting that SWE-Bench is a coding agent benchmark introduced by a Princeton University research team in 2023, built from real GitHub repository issues and their corresponding PRs. It requires models to automatically generate code patches based on issue descriptions and validate them against the repository's test suite. SWE-Bench marked a shift in programming evaluation from algorithm competition-style problems to real software engineering scenarios, spawning variants like SWE-Bench Lite, SWE-Bench Verified, and SWE-Bench Pro that progressively improved rigor and difficulty. However, its core evaluation criterion remains test passage — precisely the limitation Frontier Code aims to transcend. While Frontier Code isn't perfect and still has false positives and negatives, its error rates are significantly lower than earlier benchmarks.
Language Coverage and Key Differences in Prompt Design

Frontier Code Extended's 150 tasks cover a broader range of programming languages: TypeScript (19%), JavaScript (15%), C/C++ (15%), Python (13%), Java (13%), Go (10%), and more. By comparison, SWE-Bench Pro is heavily concentrated on Python (36%), Go (38%), and TypeScript (19%). Language diversity matters because coding agents can perform very differently across ecosystems — different languages have vastly different type systems, package management mechanisms, build toolchains, and community coding conventions. Capabilities a model builds in the Python ecosystem don't necessarily transfer to the complex build environments of C++ or Java.
Regarding prompt length, SWE-Bench Pro has a median of 30,098 characters, while Frontier Code's task description alone has a median of just 9,082 characters — only one-third of the former. This means models must infer more intent from fewer direct instructions while still adhering to the repository's general standards.
For patch size, Frontier Code involves modifications to approximately 6 files, though the median lines of code isn't extreme. It doesn't create difficulty by inflating patch size — instead, it raises the bar through quality requirements and maintainability standards.
Six Quality Dimensions: How Frontier Code Evaluates Code

Frontier Code comprehensively evaluates submitted solutions across six dimensions:
- Behavioral Correctness: Does the patch actually solve the problem?
- Regression Safety: Does it break existing functionality?
- Code Compliance: Does it pass builds, formatters, and linter checks?
- Test Correctness: Do the agent-written tests genuinely reflect expected behavior?
- Impact Scope: Does the patch only touch the necessary parts of the codebase?
- Code Quality: Does the code fit with the existing codebase and follow sound design patterns?
A linter is a type of static code analysis tool that detects potential errors, style inconsistencies, and suspicious programming patterns without running the code. Common linters include Pylint/Ruff for Python, ESLint for JavaScript, and golangci-lint for Go. In modern software engineering practice, linters are typically integrated into CI/CD pipelines and run automatically after code submission. Passing linter checks is one of the basic thresholds for code merging, but linters can only catch surface-level code quality issues — they can't evaluate architectural design soundness or business logic correctness. This is precisely why Frontier Code layers additional evaluation dimensions on top of linter checks.
To assess these dimensions, Frontier Code employs several innovative methods. The most interesting is reverse classic testing — taking the agent's submitted tests and running them against the original code version. If they pass on the old code, it means the agent's tests didn't actually detect the bug or behavioral change. There's also adaptive scoring, which uses a tool called Mutagen to dynamically adjust reference tests to accommodate different implementation approaches, thereby reducing false negatives. Mutation testing is an advanced technique for evaluating test suite quality. Its core idea is to make small, meaningful modifications to source code (called "mutants") — such as changing > to >=, deleting a line of code, or modifying a return value — then checking whether existing tests can detect these changes. If a test suite fails to catch a mutant, it indicates a blind spot in test coverage for that area. The Mutagen tool used in Frontier Code is based on this principle, dynamically adjusting reference tests to accommodate different agent implementation approaches, enabling more accurate correctness judgments and reducing misjudgments caused by different implementation paths.
Five-Stage Quality Control: Over 40 Hours of Refinement Per Task
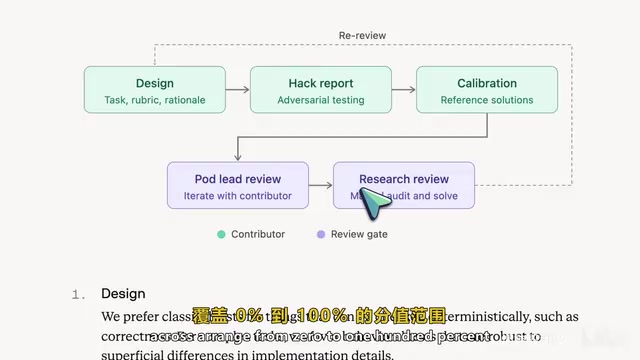
Frontier Code's quality control process spans five stages, ensuring each task's evaluation criteria can withstand scrutiny:
- Task Design: Creators decide which checks use hard automated tests and which are based on scoring rubrics
- Break Reports: Authors attempt to exploit scoring rubric loopholes with poor-quality solutions while testing different valid approaches to avoid false negatives
- Rubric Calibration: Four solutions of varying quality are written covering the 0% to 100% score range, making scoring more discriminating
- Lead Review: Senior evaluation leads review tasks and iterate with contributors
- Research Review: Cognition researchers conduct final reviews on random samples, solving tasks themselves to ensure instructions are clear and scoring is fair
These tasks were completed in collaboration with maintainers from 36 top-tier open-source projects, with over 40 hours invested per task. Maintainers have deep knowledge of their projects' internal design patterns, code style requirements, and what kind of code gets rejected. This deep involvement ensures evaluation criteria aren't arbitrarily defined by outside observers but genuinely reflect the code review culture and quality expectations of actual open-source communities.
Case Study: Code That Passes Tests but Isn't Good Code
Consider a task from a JSON Schema C++ repository: the model needs to create a new logging helper function that always outputs to standard error with an automatic warning prefix, then replace all existing warning messages with the new function.
Claude Opus scored only 4.8% on this task. It converted the first line of multi-line warnings to use the LogWarn interface, but subsequent lines still wrote directly to standard error. While the current runtime behavior is identical, this isn't good abstraction design — because callers assume LogWarn will always point to the same stream as standard error. If LogWarn is later modified to route warnings elsewhere or add metadata, the subsequent lines would break. This type of issue is known in software engineering as a "Leaky Abstraction" — code that superficially uses an abstraction layer but actually depends on the abstraction's internal implementation details, causing upper-layer code to break when the underlying implementation changes.
Even though it currently runs correctly, this is still considered a quality defect. This is precisely where Frontier Code's core value lies — it evaluates not just current functional correctness but long-term code maintainability.
Limitations and Implications: Code Quality as AI Programming's Next Bottleneck
Frontier Code's limitations should be viewed objectively:
- Test tasks are not yet public (to prevent data contamination), so external parties cannot deeply scrutinize every scoring criterion. Data contamination is one of the core challenges in LLM evaluation — if benchmark questions and answers appear in a model's training data, the model may "solve" problems through memorization rather than reasoning, inflating evaluation results. This is why an increasing number of high-quality benchmarks choose not to publish their complete question banks.
- Differences in agent test environments mean scores reflect the combined performance of model and tooling
- Prompt-based scoring can measure dimensions that unit tests cannot reach, but subjective scoring may introduce bias
But the more valuable insight is this: code quality is becoming the next bottleneck for coding agents. Simply passing tests is no longer sufficient as an evaluation standard. Code changes written by models need to be well-scoped, maintainable, idiomatic, thoroughly tested, and acceptable to codebase owners. This is a higher bar, and based on current results, no model has truly cracked it yet.
Key Takeaways
Related articles
AI Agent Core Architecture Breakdown: From Concept to Enterprise-Grade Intelligent Agent Development
Deep dive into AI Agent architecture: perception, brain, and action modules. Covers RAG memory systems, tool calling mechanisms, Chain of Thought reasoning, and enterprise agent development roadmap.
Hands-On Tutorial: Build an AI Agent from Scratch with 200 Lines of Python
Build an AI Agent from scratch with 200 lines of Python, covering prompts, memory, tool calling, RAG, and Skills — a practical guide for developers.
Anthropic Reverses Controversial Policy of Secretly Throttling AI Researchers Using Claude
Anthropic reverses its controversial policy of secretly throttling Claude Fable/Mythos responses to frontier LLM development requests after community backlash, raising critical questions about AI transparency.