Gemini 3.2 Pro Leaked Tests Disappoint, GPT-5.6 Already in Internal Testing

AI iteration accelerates: Gemini 3.2 Pro underwhelms, GPT-5.6 enters testing, Claude excels in cybersecurity
Multiple major AI developments this week: Google's Gemini 3.2 Pro leaked tests show underwhelming results with slight SVG improvements but weak UI, nearly indistinguishable from its Flash version. OpenAI's GPT-5.6 has entered internal testing at a remarkable pace. Claude's new preview solves in 6-10 attempts what takes human cybersecurity experts 20 hours. The industry is shifting from pursuing breakthrough leaps to continuous incremental optimization.
Key Developments Overview
This week brought several major developments in AI: Google's Gemini 3.2 Pro has its first leaked test results, OpenAI's GPT-5.6 has entered internal testing, and Claude's new preview version shows stunning performance in cybersecurity. These developments all point to one trend — AI model iteration cycles are shrinking dramatically, and the competitive landscape is intensifying.
Gemini 3.2 Pro Leaked Tests: Underwhelming Performance Raises Concerns
SVG Generation Improved but Far from a Quantum Leap
The first leaked test results for Gemini 3.2 Pro have surfaced, and based on what's been shown so far, the performance isn't impressive. In the most common SVG tests, the new model's ability to write code for PS5 controllers, falcons, bicycles, and other graphics has improved over previous versions — the falcon looks more proportional, the bicycle is more complete, and custom SVG functionality is now supported.
SVG (Scalable Vector Graphics) is an XML-based 2D graphics description language. Unlike raster images, it describes shapes, paths, and colors through mathematical formulas, allowing infinite scaling without quality loss. An AI model's ability to generate SVG code is considered an important metric for measuring its spatial reasoning and code generation capabilities, as the model needs to understand an object's geometric structure, spatial relationships, and visual proportions, then translate them into precise coordinates and path instructions. This is more challenging than generating ordinary text code, because any tiny coordinate deviation results in visually obvious errors.
However, significant flaws remain: logic isn't coherent enough, graphic alignment has issues, and problems like disconnected arms and incorrect orientations persist in some outputs. Given that the Gemini series has been quiet for quite some time, users were expecting a quantum leap, not incremental improvements.
UI Generation Capability Notably Weak
More concerning is the UI generation performance. Based on the leaked test results, UI capabilities have either been weakened or this version simply didn't focus on that direction. Google may have been fine-tuning for SVG code, but improvements in UI aren't apparent. If this is the final UI quality level, it's genuinely disappointing for users expecting comprehensive improvements.
Flash Version Nearly Indistinguishable from Pro Version
Most puzzling of all, the Gemini 3.2 Flash model codenamed "FENTA" (with two other versions called Sprite and Cola) performs nearly on par with 3.2 Pro. Comparing the two side by side, it's almost impossible to tell which is Pro and which is Flash — sometimes Flash even performs better.

In large language model product lines, Pro versions typically refer to models with more parameters and stronger reasoning capabilities but slower response times, while Flash versions are lightweight models optimized through Knowledge Distillation or pruning, sacrificing some performance for faster inference speed and lower computational costs. Distillation techniques allow smaller models to learn the output distribution of larger models, so theoretically Flash models should be "compressed versions" of Pro models with a noticeable performance gap. When the two converge in performance, it may indicate that the Pro version's training hasn't fully converged, or that the Flash version's distillation was exceptionally effective.
Logically, Pro models should be stronger than Flash models. If the gap between them is this small, the Pro version's positioning becomes awkward. However, it's important to emphasize that these are early leaks, and only the final release will determine the models' true performance. Google is expected to officially release these models around the May 19th I/O conference.
GPT-5.6 in Internal Testing: Jaw-Dropping Iteration Speed
Significantly Shortened Development Cycles
According to leaks, the first checkpoints of GPT-5.6 have entered internal testing, with release potentially as early as next month. There are currently two internal codenames — "Amber Alpha" and "Beacon Alpha" — likely representing different versions of GPT-5.6, with OpenAI testing to determine which performs better.
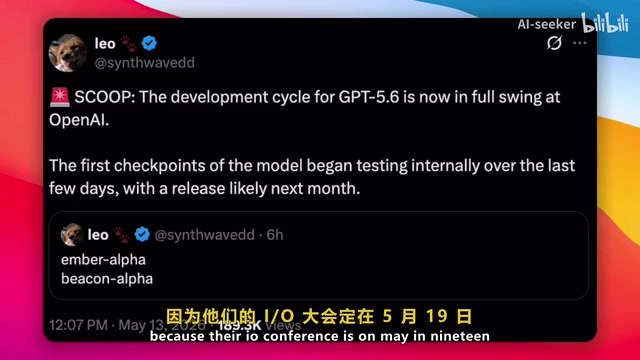
A checkpoint is an intermediate state snapshot periodically saved during model training, containing all weight parameters at that moment. Major AI labs typically save multiple checkpoints during training, then evaluate and test these checkpoints to select the best-performing version for subsequent alignment training (RLHF) and safety fine-tuning. OpenAI's approach of testing two codenamed versions simultaneously likely means they're exploring different training recipes — such as different data ratios, learning rate strategies, or architecture variants — using A/B testing to determine the final release.
What's most remarkable is that GPT-5.5 was released just weeks ago, and the iteration cycle has already become absurdly fast. GPT-5.5 was a massive success for OpenAI, significantly outperforming Claude Opus 4.7, and now they seem intent on maintaining this competitive pace, planning to use GPT-5.6 to once again surpass Google's upcoming models.
Two Key Drivers Behind Accelerated Iteration
There are two core reasons for the acceleration:
First, AI is participating in its own development. Models are now writing code themselves, which undoubtedly accelerates R&D progress significantly. Specifically, AI participating in its own development (sometimes called an early form of "recursive self-improvement") currently manifests at several levels: AI assists in writing training infrastructure code, automates hyperparameter searches, generates and filters training data, and assists with model evaluation. OpenAI has publicly stated that they extensively use their own models internally to accelerate software engineering work. This differs from sci-fi notions of "AI self-evolution" — the current stage is more like AI serving as an efficient R&D assistant, freeing human engineers from repetitive work, thereby compressing overall development cycles. But this positive feedback loop is indeed accelerating the pace of model iteration.
Second, market competition is extraordinarily fierce. The industry's iteration speed is extremely fast, and OpenAI and other labs have no choice but to accelerate their release frequency. In the future, it may be difficult to see the kind of breakthrough performance leaps we've seen in the past. Instead, we'll see more frequent minor updates, personalized features, and architectural optimizations.
This means the industry is transitioning from "pursuing explosive leap growth" to a new phase of "continuous incremental optimization."
Claude New Preview: Major Breakthrough in Cybersecurity
Solving in 6-10 Attempts What Takes Humans 20 Hours
Claude's new preview version shows stunning performance in cybersecurity testing. Facing enterprise-level cyberattacks with up to 32 steps that typically take human experts 20 hours to resolve, the new Claude preview model can handle them in just 6 to 10 attempts.
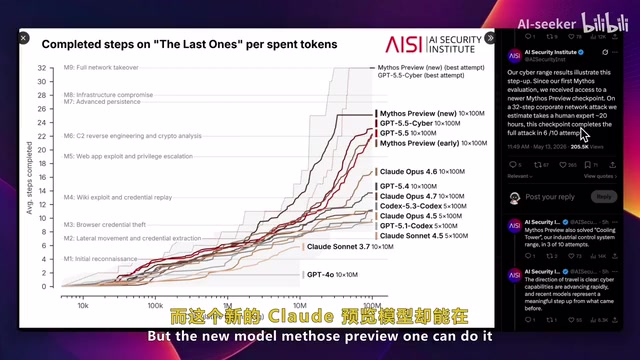
The "32-step enterprise-level cyberattack" test mentioned here is likely based on standardized scenarios from CTF (Capture The Flag) competitions or red team exercises. These tests typically simulate real multi-stage attack chains (Kill Chains), including initial reconnaissance, vulnerability exploitation, privilege escalation, lateral movement, data exfiltration, and more. Each step requires analyzing system configurations, identifying vulnerabilities, writing exploit code, and evading detection mechanisms. Human experts need 20 hours because each step involves extensive information gathering and trial-and-error. An AI model completing this in 6-10 attempts demonstrates that its pattern recognition and attack path planning capabilities have achieved efficiency surpassing humans.
Looking at the test data, Claude Opus 4.6 initially held the lead, then GPT 5.5 tied with it upon release, followed by GPT 5.5 Cyber (a version specifically fine-tuned for cybersecurity) briefly taking the lead, before Claude's new preview version reclaimed the top spot.
The Double-Edged Sword Effect Cannot Be Ignored
This capability is a double-edged sword — if a model can both solve security problems and is equally adept at discovering and exploiting vulnerabilities, things get complicated. This is precisely why cybersecurity-related models have adopted a phased release strategy, giving enterprises and governments time to adapt to this new reality.
Codex Coming to Mobile
Worth noting is that OpenAI's Codex team is working on launching a mobile application, potentially as a standalone app or integrated into an existing platform. Users will be able to use remote control features, which is an important addition for mobile development scenarios.
Codex was originally a code generation model launched by OpenAI in 2021, which later evolved into a complete AI programming agent platform. Bringing it to mobile means developers can remotely control code repositories through natural language commands in any scenario — reviewing Pull Requests, fixing urgent bugs, or even launching complete development tasks. This is particularly important for DevOps and on-call scenarios, where engineers can handle production environment issues without opening a laptop. The remote control feature likely relies on a cloud sandbox-like architecture, allowing AI agents to execute code operations in securely isolated environments while providing real-time feedback and approval mechanisms through the mobile interface.
Summary and Outlook
The AI industry is currently at a subtle turning point: models are already powerful enough, and future competition will increasingly manifest in iteration speed, specialized fine-tuning, and user experience optimization. Google needs to prove itself at the May 19th I/O conference, while OpenAI is trying to maintain its lead through rapid-fire iteration. For users, more frequent model updates mean continuously improving experiences, but also mean we need to adjust expectations — revolutionary breakthroughs may become increasingly rare, with incremental improvements becoming the norm.
Key Takeaways
- Gemini 3.2 Pro leaked test results are underwhelming — SVG generation improved but UI capability is weak, and it's nearly indistinguishable from the Flash version
- GPT-5.6 has entered internal testing with codenames Amber Alpha and Beacon Alpha, potentially releasing as early as next month
- AI model iteration cycles are shrinking dramatically, driven by AI participating in its own development and fierce market competition
- Claude's new preview version shows stunning cybersecurity test performance, solving in 6-10 attempts what takes human experts 20 hours
- The industry is transitioning from pursuing breakthrough leaps to a new phase of continuous incremental optimization
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.