Gemini 3.5 Live Translate Launch: A Deep Dive into the Speech-to-Speech Translation Model Supporting 70+ Languages
Google releases Gemini 3.5 Live Translate with end-to-end speech-to-speech translation across 70+ languages.
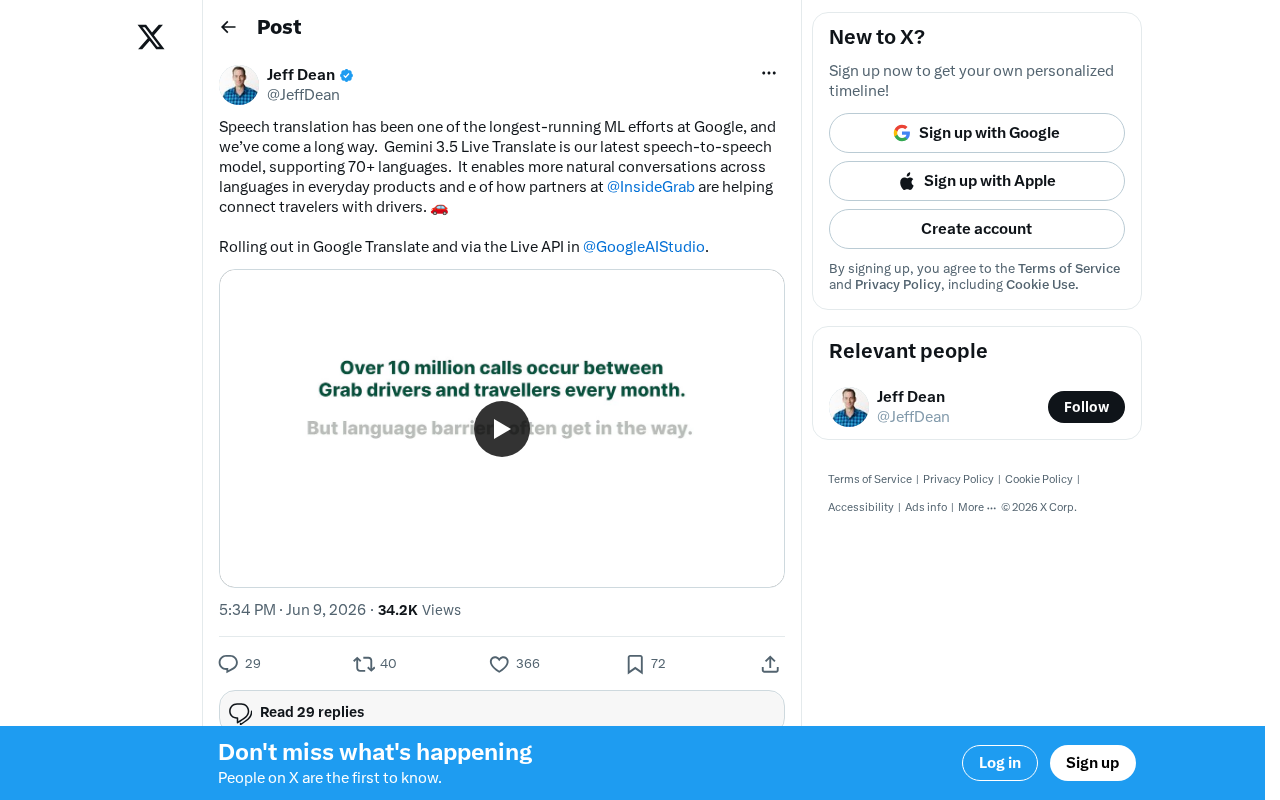
Google has launched Gemini 3.5 Live Translate, an end-to-end speech-to-speech translation model supporting 70+ languages. Unlike traditional cascaded systems, it directly converts speech between languages while preserving intonation and emotion. The model is available through Google Translate and the Live API, with Grab as a launch partner for real-time driver-passenger communication in Southeast Asia.
A Milestone Moment for Speech Translation
Google has officially released Gemini 3.5 Live Translate, its latest speech-to-speech translation model supporting over 70 languages. As one of Google's longest-running research directions in machine learning, speech translation technology has finally achieved a qualitative leap forward.
The core highlight of this model is that it achieves true "real-time speech translation" — no longer the traditional cascaded pipeline of "speech-to-text → text translation → text-to-speech," but rather end-to-end direct speech-to-speech conversion. This means the translation process can better preserve intonation, emotion, and the natural rhythm of conversation.
Traditional speech translation systems use a cascade architecture that breaks the task into three independent modules: automatic speech recognition (ASR) converts speech to text, machine translation (MT) converts source language text to target language text, and text-to-speech (TTS) synthesizes the translated text into speech. The core problem with this cascaded approach is that each stage introduces errors and accumulates latency. More critically, the paralinguistic information carried in speech — such as intonation, speaking rate, emotional coloring, and pause rhythm — is largely lost during the intermediate text representation stage. End-to-end models use a single neural network to directly map from source language speech to target language speech, bypassing the intermediate text representation, thereby better preserving this non-textual information while significantly reducing overall latency.
Product Implementation of Gemini 3.5 Live Translate
Partnership with Grab: Real-Time Translation for Ride-Hailing
Google showcased a highly compelling real-world application — a partnership with Southeast Asian ride-hailing giant Grab. In this scenario, travelers and drivers can have real-time cross-language conversations through Gemini 3.5 Live Translate. A tourist who only speaks Chinese can communicate naturally and fluently with a Thai-speaking driver in Bangkok — something that was nearly impossible before.
Grab is Southeast Asia's largest super-app platform, headquartered in Singapore, with operations spanning ride-hailing, food delivery, and financial services across eight countries including Singapore, Malaysia, Indonesia, Thailand, Vietnam, the Philippines, Myanmar, and Cambodia. Southeast Asia is one of the most linguistically diverse regions in the world — Indonesia alone has over 700 local languages, and countries like Thailand, Vietnam, and Cambodia each have different official languages. Cross-language interactions on Grab's platform are extremely frequent every day, especially in popular tourist cities where the language barrier between drivers and passengers is one of the core pain points affecting service experience.
This case is significant because it represents the transition of AI translation technology from "functional" to "excellent." Ride-hailing scenarios have extremely high requirements for translation: low latency, high accuracy, and the ability to handle various accents and noisy environments. Grab's decision to integrate this technology is itself a powerful validation of its maturity.
Open Access: Google Translate and Live API
Gemini 3.5 Live Translate is currently available to users and developers through two channels:
- Google Translate: Directly integrated into the Google Translate app, allowing everyday users to immediately experience real-time speech-to-speech translation
- Live API (Google AI Studio): Provides API access for developers, enabling third-party applications to embed real-time translation capabilities into their products, just like Grab
Google AI Studio is Google's AI model experimentation and deployment platform for developers, where they can test various capabilities of the Gemini model series and obtain API keys. The Live API is an interface specifically designed for real-time interaction scenarios, supporting streaming audio input and output. This means developers don't need to wait for users to finish an entire sentence before translating — they can begin processing and outputting translation results while the user is still speaking. This streaming capability is crucial for achieving low-latency conversational experiences and is the key technical differentiator from traditional batch-processing translation APIs.
This dual-track release strategy satisfies both consumer users' immediate needs and paves the way for B2B ecosystem expansion.
Technical Deep Dive into End-to-End Speech Translation
Technical Challenges Behind 70+ Language Coverage
Supporting over 70 languages may seem like just a number, but the underlying technical challenges are substantial. Different languages vary enormously in grammatical structure, word order, and cultural expression patterns. Especially in speech-to-speech mode, the model must simultaneously understand the semantics and prosody of the source language while regenerating natural speech output in the target language.
From a technical architecture perspective, Gemini 3.5 Live Translate likely benefits from the multimodal capabilities of the Gemini model series. Gemini itself is a natively multimodal model capable of simultaneously processing text, audio, images, and other input types, providing a natural architectural advantage for speech translation. The Gemini series, developed by Google DeepMind, was designed from the ground up to natively support multiple modalities during training, rather than stitching together separate encoders for different modalities as earlier multimodal models did. This native multimodal training means the model's internal representations of different modalities are unified, enabling cross-modal reasoning within a shared latent space. For speech translation tasks, this means the model can simultaneously understand the acoustic features and semantic content of speech and directly generate output in the target language's speech space without requiring an explicit text decoding step.
Competitive Comparison: Shifting Industry Landscape
Real-time speech translation has long been a battleground for tech giants. Meta previously released the SeamlessM4T model, and Microsoft has integrated real-time translation into Teams. Google's differentiated advantages with this release include:
- Language coverage breadth: 70+ language support is industry-leading
- High degree of productization: Direct integration into Google Translate, the world's most widely used translation tool
- Ecosystem openness: The Live API enables third-party developers to quickly integrate the capability
Meta's SeamlessM4T (Massively Multilingual & Multimodal Machine Translation), released in 2023, was the industry's first unified model supporting multi-task translation across speech and text, covering speech recognition for approximately 100 languages and text translation for nearly 100 languages. Meta subsequently released upgraded versions of the Seamless series, including SeamlessStreaming (supporting streaming translation to reduce latency) and SeamlessExpressive (preserving speech expression features like emotion and intonation). Microsoft primarily addresses this space through Azure AI Speech services and real-time caption translation in Teams meetings, with its advantage lying in deep integration for enterprise scenarios. By comparison, Google's Gemini 3.5 Live Translate release demonstrates clear competitive differentiation in terms of productization speed and ecosystem openness for third-party developers.
How Developers Can Access the Gemini Real-Time Translation API
For developers, through Google AI Studio's Live API, any application involving cross-language communication — whether customer service systems, education platforms, or social products — can quickly gain professional-grade real-time translation capabilities.
The maturation of speech translation technology is gradually making the "Tower of Babel" vision a reality. When translation latency is low enough, accuracy is high enough, and language support is broad enough, language will no longer be a barrier to human communication. The democratization of this capability may give rise to an entirely new wave of cross-language application scenarios — from international telemedicine consultations and global education live-streaming classrooms to real-time interaction in multilingual communities. Speech translation is transforming from a laboratory technology into an infrastructure-level universal capability.
Key Takeaways
Related articles

Vibe Coding Beginner's Guide: A Complete Roadmap to Building Software with AI — No Coding Experience Required
Vibe Coding lets anyone build software using plain language instructions with AI. Learn what it is, when to use it, which tools to pick, and how to get started.

Beginner's Guide to Vibe Coding: Turn Ideas into Products with AI — No Coding Experience Required
Vibe Coding lets anyone build software products through natural language conversations with AI — no programming skills required. Learn the concept, top tools (Cursor, Claude Code, Codex), and how to get started.
Codex in Action: One Prompt, 47 Minutes, a Complete Algorithm Research Paper
Testing OpenAI Codex: one detailed prompt generates a complete algorithm paper in 47 minutes, including working code, figures, and LaTeX manuscript. Covers prompt design, quality assessment, and real submission experience.