Gemini Omni Video Editing Arrives in India: An Upload-and-Edit AI Experience
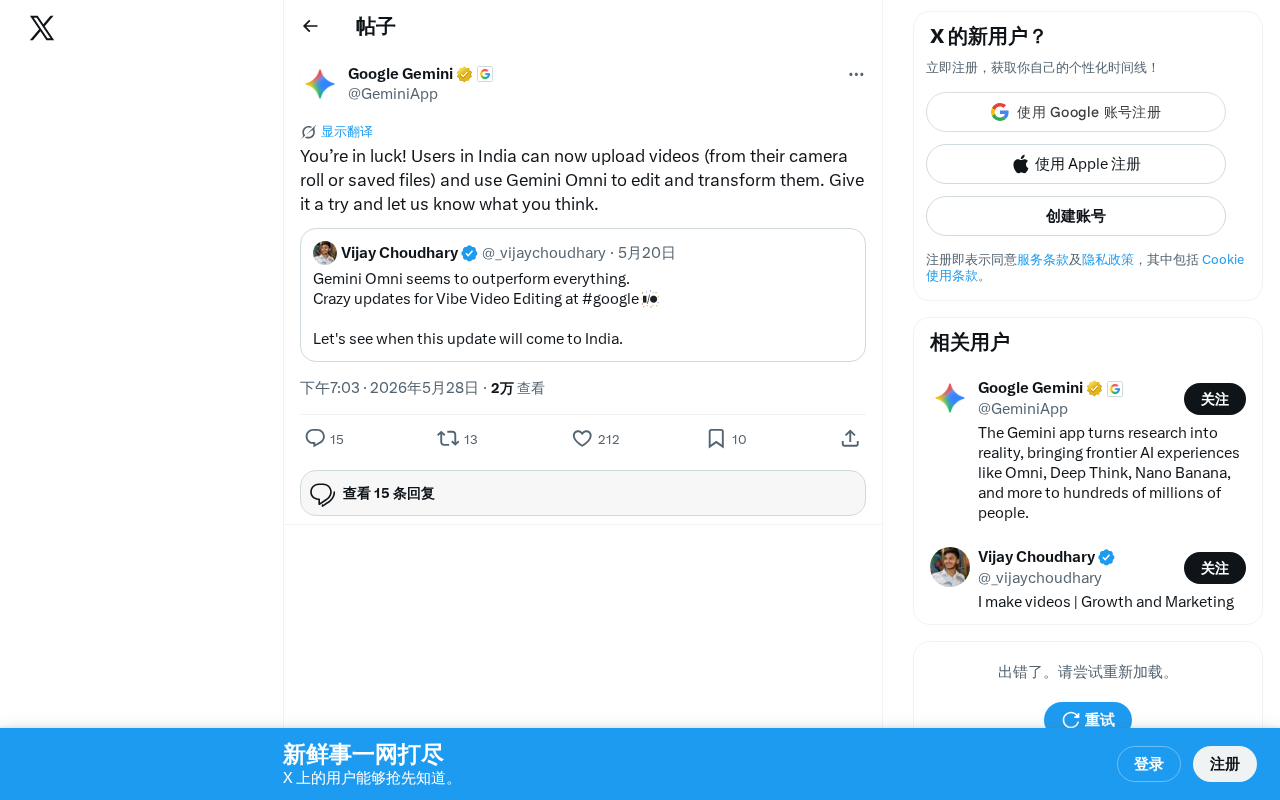
Gemini Omni video editing feature officially launches for users in India
Google has announced that Indian users can now upload videos through Gemini Omni for AI-powered editing and transformation. The feature leverages multimodal large model capabilities across video understanding, instruction alignment, and generation execution to deliver a conversational video editing experience. Google chose India for the initial launch due to its massive user base and strong video consumption demand, while differentiating itself by embedding video editing into its conversational assistant ecosystem. This feature marks a significant evolution of AI from content understanding to content creation.
Gemini Omni Video Editing Officially Launches in India
Google recently announced that users in India can now upload videos through Gemini Omni for editing and transformation. The rollout of this feature marks another significant expansion for Gemini in the multimodal AI application space and signals Google's accelerated push to deploy AI video processing capabilities in the critical Indian market.
Gemini Omni and Multimodal Large Models: Technical Background
Gemini is a family of multimodal large language models released by Google DeepMind in late 2023, available in multiple versions including Ultra, Pro, Flash, and Nano. The "Omni" variant specifically refers to the version with full cross-modal perception and processing capabilities, able to handle text, images, audio, and video inputs simultaneously. The core technical breakthrough behind multimodal large models lies in a unified feature representation space — by mapping data from different modalities into the same vector space, the model can understand semantic relationships across modalities. Video processing is considerably more complex than image processing because it introduces a temporal dimension: the model must understand inter-frame motion, scene transitions, and narrative logic, placing greater computational demands on the Transformer architecture's attention mechanism. Built on this technical foundation, the "Omni" in Gemini Omni's name literally means "all-capable" — from initial text understanding, to image analysis, and now video editing, Gemini is progressively delivering on its multimodal AI promise.
Feature Details: AI Video Editing Through Simple Upload
According to the official announcement, Indian users can now upload videos from their Camera Roll or saved files, then use Gemini Omni to edit and transform the footage. Users no longer need to rely on professional video editing software — Gemini's AI capabilities alone can handle video content processing.
This "conversational video editing" experience relies on the coordination of multiple technical layers: first, the video understanding layer, which uses visual encoders (such as ViT variants) to extract features from video frames and combines temporal modeling to understand dynamic content; second, the instruction alignment layer, which uses RLHF (Reinforcement Learning from Human Feedback) or instruction fine-tuning to enable the model to understand natural language editing commands; and finally, the generation execution layer, where the model parses user instructions into structured editing operation sequences and hands them off to the underlying video processing engine, delivering a seamless end-to-end experience.
While Google has not yet provided a detailed list of all supported editing features, the description of "edit and transform" suggests Gemini Omni likely supports the following capabilities:
- Video content understanding and analysis: Semantic understanding of video content powered by multimodal large models
- Intelligent editing and trimming: Performing video cuts, splicing, and other operations through natural language commands
- Style transformation: Applying stylistic effects or format conversions to videos
Strategic Significance: Why Google Chose India for the Initial Launch
Massive User Base and Video Consumption Demand
India is not only one of the world's largest markets by user volume — it's also a strategic battleground for AI companies. India has over 500 million active smartphone users, many of whom rely on mobile devices as their primary internet gateway. Video content consumption accounts for the lion's share of traffic — YouTube has over 460 million monthly active users in India, and after the TikTok ban, homegrown short-video platforms surged rapidly, creating strong demand for video creation. At the same time, India boasts a large English-speaking user base and a rapidly growing pool of tech talent, making it an ideal market for real-world stress testing of AI products. Tech giants including Google, Meta, and Microsoft have all designated India as a priority market for AI product launches — driven by both commercial scale considerations and the technical motivation of optimizing model generalization through a diverse user base. Google's decision to launch this feature in India first clearly reflects its recognition of the market's enormous potential.
Building Differentiation Against Competitors
The AI video space has evolved into a multi-polar competitive landscape. OpenAI's Sora uses a diffusion Transformer architecture and is known for high-quality text-to-video generation, but requires long generation times and heavy compute resources. Runway's Gen series targets professional creators with fine-grained video editing controls. Pika Labs focuses on ease of use for everyday consumers. On the Chinese side, products like Kuaishou's Kling and ByteDance's Jimeng are also iterating rapidly.
By integrating video editing capabilities directly into Gemini, Google has taken a differentiated path — embedding the feature within a conversational assistant ecosystem that already serves hundreds of millions of users, rather than building a standalone video tool. This "assistant-native" positioning lowers user migration costs: no additional app installation is needed, and everything can be done within the Gemini chat interface. This "conversational video editing" experience could become a key differentiator for Gemini compared to other AI video tools, though it still faces challenges from specialized vertical tools in the professional creation space.
The Evolution of Multimodal AI: From Understanding to Creation
As one of the most information-dense media formats, video places higher demands on both AI model comprehension and generation capabilities. Compared to static images, video data grows by orders of magnitude — a 30-second HD video contains hundreds of frames, and the model must understand the content of each frame while grasping the temporal logic and semantic coherence between them.
The launch of this feature also reflects a major trend in the AI industry: the shift from "understanding" to "creation". AI is no longer merely a tool for analysis and answering questions — it is becoming a powerful content creation assistant. For everyday users, this means the barrier to video creation will continue to drop. Editing, color grading, and effects work that once required mastery of professional software may soon be achievable with a single natural language command.
Future Outlook: Where Gemini Video Editing Is Headed
The feature is currently available only in the Indian market, and Google's announcement invites users to actively try it out and share feedback, suggesting the feature may still be in an early rollout phase. As user feedback accumulates and model capabilities iterate, we can expect:
- Gradual expansion to more countries and regions
- Continued enhancement of AI editing capabilities, such as support for more complex video effects and transitions
- Deep integration with the Google ecosystem, including synergies with YouTube, Google Photos, and other products
For users and developers following AI developments, Gemini Omni's exploration of video editing is worth watching closely. It represents not only the cutting edge of multimodal AI technology but also a glimpse into the future of AI-assisted content creation.
Key Takeaways
- Google Gemini Omni's video upload and editing feature is now officially available to users in India
- Users can upload videos from their camera roll or files and edit and transform them using AI
- India's selection as the launch market reflects Google's focus on the region's massive user base
- This feature marks a significant evolution for Gemini from content understanding to content creation
- The feature is currently in an early rollout phase and is expected to expand to more regions in the future
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.