Gemini Omni Video Generation: One-Click Synthesis from Mixed Text, Image, and Video Inputs
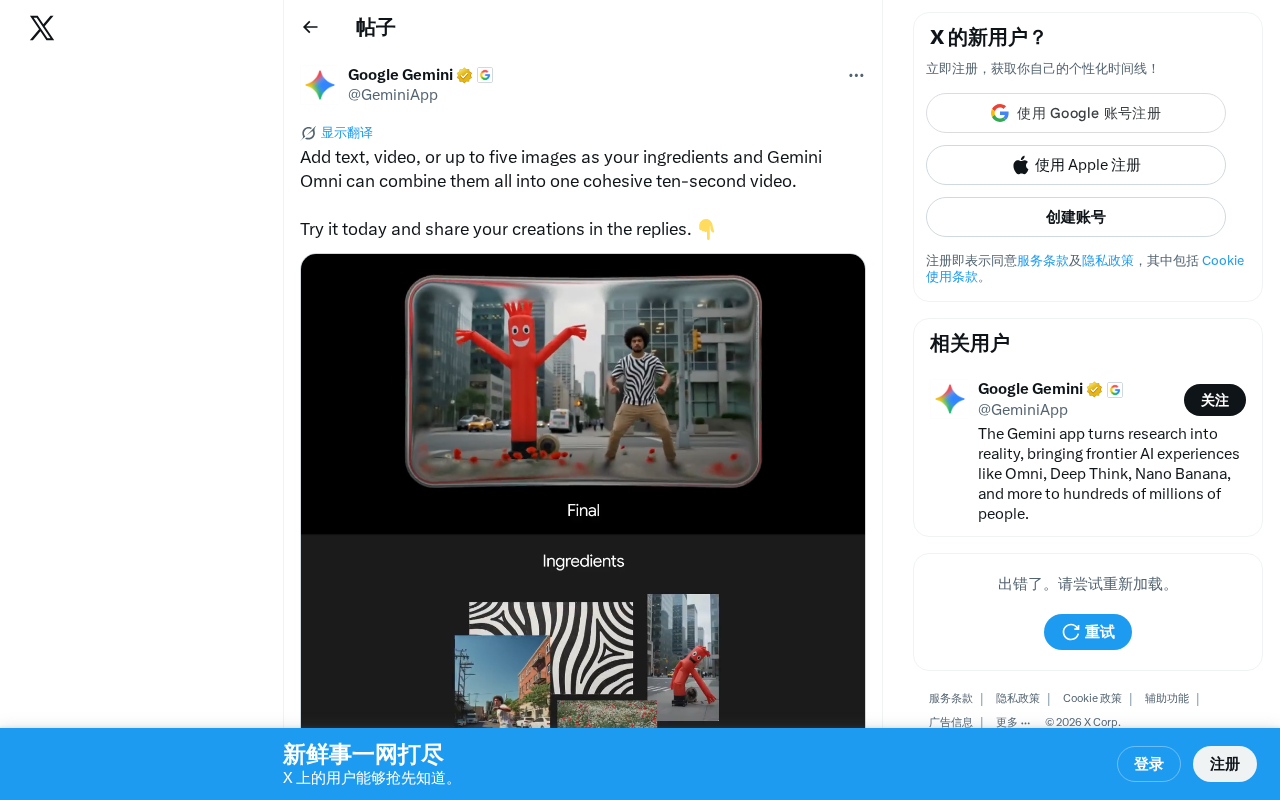
Google Gemini Omni launches multimodal mixed-input ten-second video generation
Google's latest Gemini Omni video generation feature supports multimodal mixed input of text, images (up to five), and video to synthesize coherent ten-second videos with one click. Built on a natively multimodal architecture, it achieves cross-modal semantic alignment and content consistency through a unified Transformer framework. Compared to competitors like Sora and Runway, its core differentiation lies in the flexibility of multimodal mixed input and platform integration strategy, suitable for social media creation, commercial marketing, and other scenarios.
Google's latest Gemini Omni video generation feature has attracted widespread attention — users can use text, video, or up to five images as "raw materials," and AI will fuse them into a coherent ten-second video. This capability marks a new phase in multimodal AI video creation.
Gemini Omni Feature Highlights: Multimodal Input, One-Click Video Synthesis
The biggest highlight of Gemini Omni's video generation capability is its flexible multimodal input support. Users are no longer limited to a single input format and can freely combine the following materials:
- Text descriptions: Describe the desired video content through natural language
- Image assets: Up to five images supported as visual references
- Video clips: Existing video footage can also serve as input
These different types of materials can be mixed and matched. Gemini Omni understands and fuses them, ultimately outputting a coherent ten-second video.
The Technical Evolution of Multimodal Large Models
To understand the significance of Gemini Omni, we first need to understand the development trajectory of Multimodal Large Language Models (MLLMs). MLLMs are AI systems capable of simultaneously processing multiple data types including text, images, audio, and video. Early AI models were mostly "unimodal" — the GPT series focused on text, DALL-E focused on image generation, each operating independently. Around 2023, as the Transformer architecture became further generalized and large-scale pretraining datasets grew richer, researchers began exploring ways to unify different modalities within a single model framework.
Google's Gemini series is a representative product of this trend. Its design philosophy has been "natively multimodal" from the start, rather than stitching independent models together. This stands in stark contrast to OpenAI's approach of maintaining GPT-4V (visual understanding) and DALL-E (image generation) separately, and is the fundamental reason why Gemini Omni can achieve truly multimodal mixed input.
Technical Analysis: From Unimodal to True Multimodal Fusion
Previously, mainstream AI video generation tools mostly supported only single-modality inputs like "text-to-video" or "image-to-video." Gemini Omni unifies multiple modalities into a single generation pipeline, which technically requires the model to possess two key capabilities.
Cross-Modal Understanding
The model must simultaneously understand text semantics, image content, and video temporal information, and establish correlations between these different representations. This is precisely the core direction of Google's continued investment in multimodal large models.
The core challenge of cross-modal understanding lies in how to map different types of data into the same "semantic space" for unified representation. The current mainstream technical approach uses a unified Transformer architecture, converting text tokens, image patches, and video frames into vector representations through their respective encoders, then interacting and fusing them within a shared Attention Mechanism. Images are typically divided into fixed-size patches, with each patch treated as a basic unit similar to a text token. Video adds a temporal dimension on top of this, requiring additional Temporal Encoding to capture dynamic changes between frames. Google disclosed in Gemini's technical report that its model was exposed to multimodal data simultaneously during the pretraining phase, rather than first training a language model and then performing multimodal fine-tuning. This makes semantic alignment between different modalities deeper and more natural.
Content Consistency Preservation
Fusing five potentially stylistically diverse images into a "coherent" video requires the model to maintain visual style, thematic, and narrative consistency throughout the generation process. This places very high demands on AI video generation quality.
There are currently two major technical approaches in AI video generation: Diffusion Models and Autoregressive Models. Products represented by Sora and Runway Gen-3 primarily adopt the diffusion model approach. The core idea is to start from random noise and gradually generate high-quality video frames through an iterative denoising process, using spatiotemporal attention mechanisms to ensure inter-frame coherence. Sora also introduces a "video compression network" that compresses video into low-dimensional spatiotemporal patches, then performs diffusion generation in this space, significantly improving generation efficiency. Content Consistency is one of the most difficult technical challenges in video generation — when input materials have vastly different styles, the model needs to preserve the core visual features of each material while unifying color tone, lighting, motion rhythm, and other dimensions. This places extremely high demands on both the model's depth of semantic understanding and precision of generation control.
Application Scenarios for Gemini Omni Video Generation
Although ten seconds is a limited duration, in a content ecosystem dominated by short videos and social media, this feature has broad practical value:
- Social media content creation: Quickly transform travel photos, product images, etc. into dynamic video content
- Creative expression and storytelling: Use a few key frames plus text descriptions to let AI fill in transitions and dynamic effects
- Commercial marketing material production: Brands can quickly synthesize product images and promotional copy into short video ads
- Education and demonstrations: Transform static educational images into more intuitive dynamic presentations
Competitive Landscape: The AI Video Generation Race Heats Up
This feature release intensifies competition in the AI video generation space. Products like OpenAI's Sora, Runway's Gen-3, and Pika are all continuously iterating. Google's choice to integrate video generation capabilities directly into Gemini, rather than launching a standalone product, reflects its "unified" multimodal strategy — having one model handle all modalities of input and output.
Competition in the AI video generation space is not just a technical contest but also reflects fundamentally different product strategies among major tech companies. OpenAI launched Sora as a standalone product, focusing on ultimate generation quality and longer video duration (supporting up to 60 seconds), targeting professional creators and film industry professionals. Runway has deeply cultivated the creative tools ecosystem, with Gen-3 having unique advantages in video editing and style control, having established partnerships with multiple Hollywood studios. Pika positions itself in the consumer market, emphasizing ease of use and rapid generation. Google's choice to integrate video generation directly into Gemini reflects its platform strategy of building a "super AI assistant" — by unifying text, image, video, code, and other capabilities under a single entry point, it increases user stickiness and usage frequency while laying the foundation for AI upgrades across enterprise product lines like Google Workspace. The risk of this "unified" approach is that a single model needs to maintain competitiveness across multiple dimensions simultaneously, and any weakness could affect the overall user experience.
Compared to competitors, Gemini Omni's differentiated advantage lies in the flexibility of multimodal mixed input. Most competitors still rely primarily on text prompts as the main input method, while Gemini Omni allows users to freely combine text, images, and video, both lowering the creative barrier and providing richer creative control.
Summary
From pure text conversations to multimodal content generation, Gemini's capability boundaries are expanding rapidly. Ten-second videos may be just a starting point — as generation quality and duration continue to improve, AI-assisted video creation is poised to become a tool accessible to everyone. The feature is now available, and interested users can try it immediately.
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.