Gemini Omni Video Style Transfer: Change Video Visual Styles with Natural Language
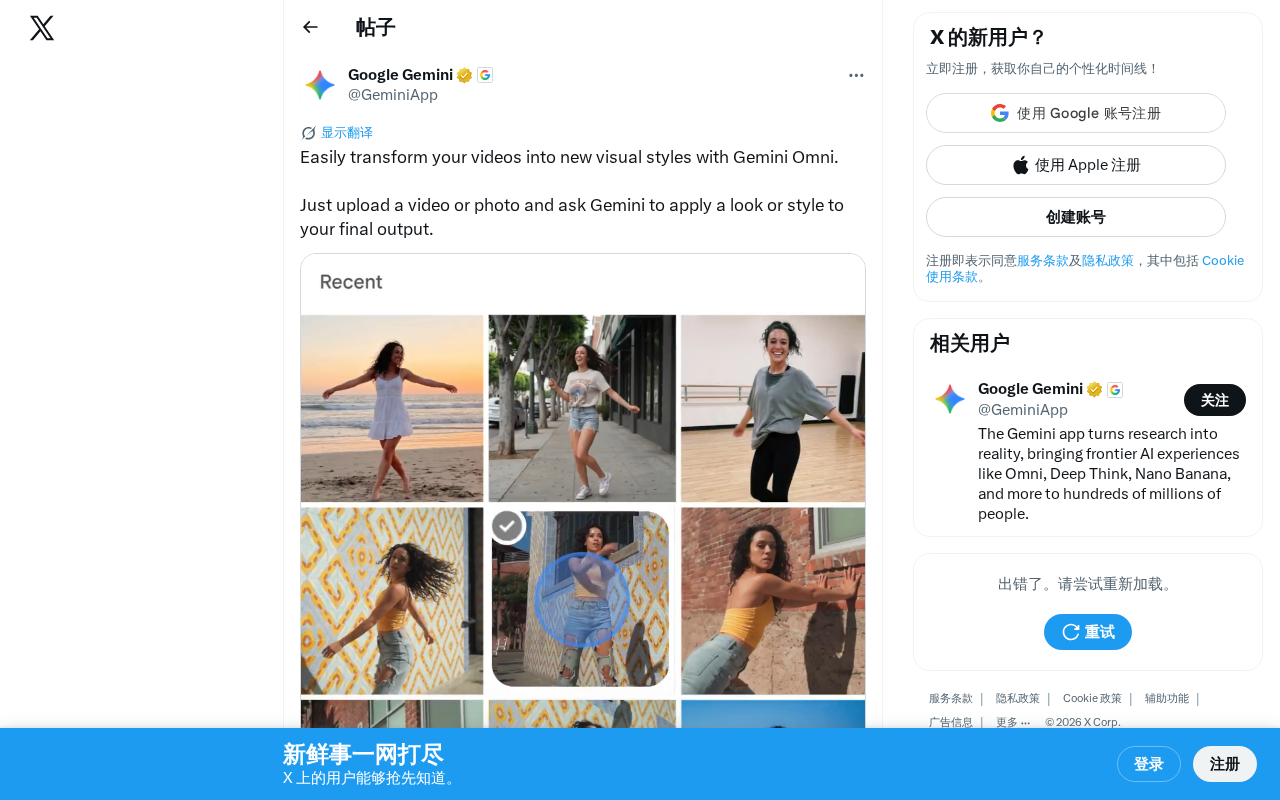
Gemini Omni enables natural language-driven video style transfer, democratizing AI video editing.
Google's Gemini Omni model allows users to transform videos or photos into any visual style through natural language descriptions. Built on a native multimodal architecture that processes text, image, and video within a unified framework, it solves core challenges like temporal consistency in video style transfer. Standing on a decade of neural style transfer advances, this technology dramatically lowers video creation barriers, marking AI video editing's paradigm shift from tool-assisted to intent-driven.
Google's latest Gemini Omni model introduces a remarkable capability — video style transfer. Users simply upload a video or photo, describe the desired visual style in natural language, and Gemini transforms the content into an entirely new artistic form. This marks AI video editing's transition from professional tools to mainstream accessibility.
What Is Gemini Omni Video Style Transfer
Gemini Omni's video style transfer feature is essentially the product of deeply combining multimodal understanding with generation capabilities. Unlike traditional video filters that simply overlay color or texture effects, it performs holistic style reconstruction of the visual content based on semantic understanding of the video.
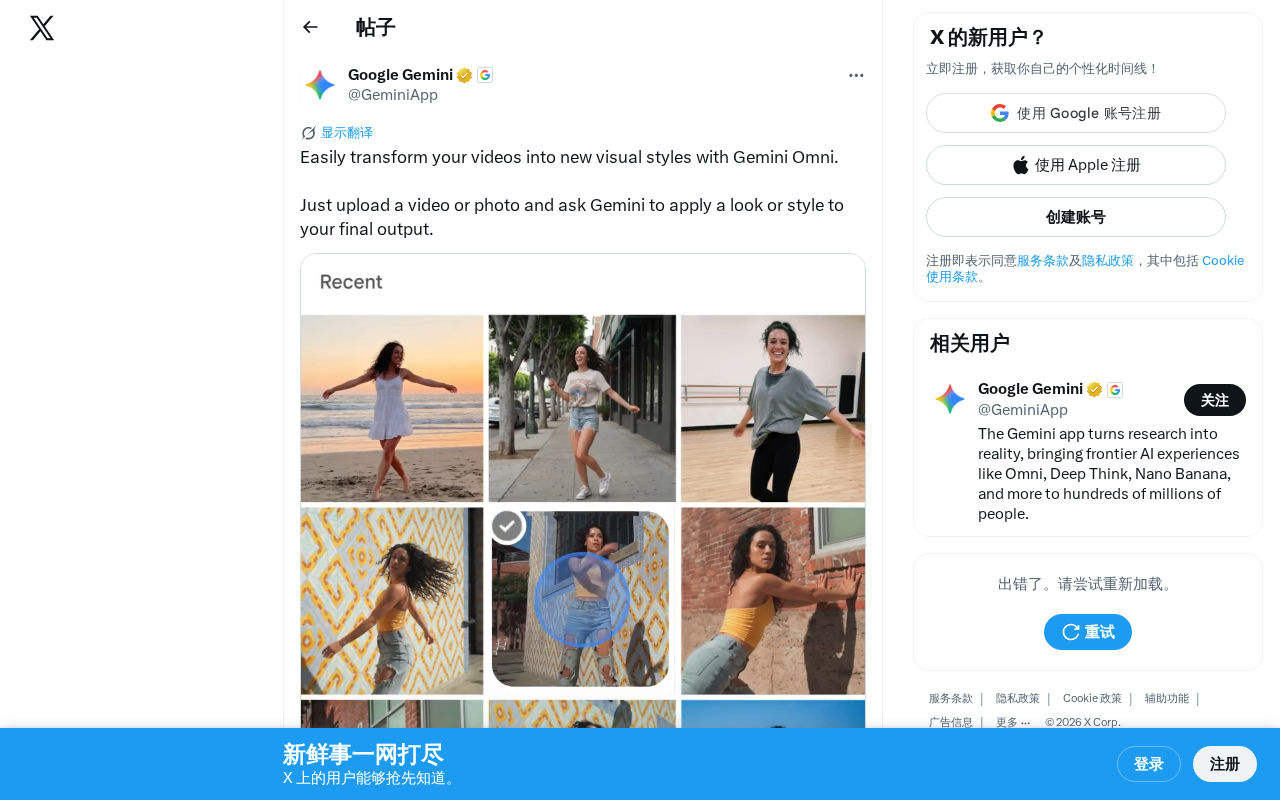
The user workflow is extremely simple: upload a video or photo, then tell Gemini in natural language what visual style you want — such as "watercolor painting style," "cyberpunk style," "Studio Ghibli animation style," etc. — and Gemini applies that style to the final output.
Technical Breakthroughs and Industry Significance
A Decade of Neural Style Transfer Accumulation
The starting point of AI style transfer technology traces back to 2015, when Leon Gatys and colleagues at the University of Tübingen published "A Neural Algorithm of Artistic Style," first demonstrating that convolutional neural networks (CNNs) could separate and recombine an image's "content" and "style." The method leveraged feature responses at different layers of VGG networks — shallow layers capturing textures and brushstrokes, deeper layers encoding semantic content — optimizing generated images through gradient descent iteration. However, this approach required several minutes of iterative computation per image, making real-time application impossible. Subsequently, feed-forward network approaches improved speed by three orders of magnitude, followed by GAN-based solutions like CycleGAN and StyleGAN, and the recent rise of Diffusion Models, which finally brought style transfer quality and flexibility to commercially viable standards. Gemini Omni's video style transfer stands on the shoulders of this decade of technical accumulation, deeply fusing diffusion model generation capabilities with large language model semantic understanding to achieve an interaction paradigm leap from "specifying a reference style image" to "describing style in natural language."
The Leap from Image Style Transfer to Video Style Transfer
Previously, AI style transfer was primarily concentrated in the static image domain. Extending style transfer to video faces enormous technical challenges, the most critical being "Temporal Consistency." If each video frame is independently stylized, even with perfect single-frame results, subtle random differences between adjacent frames produce severe flickering and jittering during playback — a phenomenon known as "Temporal Artifacts."
Early video style transfer research used Optical Flow estimation to constrain pixel correspondence between adjacent frames, but optical flow computation easily fails in occluded regions and fast-motion scenes. More modern approaches inject Temporal Attention mechanisms into the diffusion model's denoising process, allowing the model to "see" the state of adjacent frames when generating each frame, maintaining consistency at the feature space level. Additionally, video style transfer requires reconstructing visual appearance while preserving original motion trajectories, demanding deep model understanding of motion semantics — such as clothing movement during walking, ripple flow on water surfaces — rather than mere pixel-level texture replacement. Gemini Omni's breakthrough in this area reflects Google's years of technical investment in video generation foundation models (such as prior research including Lumiere and VideoPoet).
Natural Language-Driven Video Creation Paradigm
Traditional video stylization tools typically require users to possess certain professional knowledge — understanding parameter meanings, mastering color grading techniques, and familiarity with effects software operation logic. Gemini Omni simplifies all of this into a single natural language instruction. This transformation in interaction means the barrier to video creation has been dramatically lowered, allowing anyone to become a "director" of visual style.
Native Multimodal Architecture: Fundamental Differences from Traditional Stitched Approaches
Gemini Omni's ability to achieve video style transfer is thanks to its Native Multimodal Architecture. To understand the significance of this architecture, one must first understand the industry's previous mainstream approach: traditional multimodal AI systems typically adopt a "modality alignment" stitching approach, using independent visual encoders (such as CLIP's image encoder) to convert images into vector representations, feeding these vectors to a language model for processing, and finally generating visual output through an independent image decoder. The problem with this architecture is that visual information inevitably loses fine-grained visual details when converted into vectors processable by the language model, with a "semantic gap" in information transfer between modules.
Native multimodal architecture unifies text, image, audio, video, and other modality data into the same feature space from the training stage. Google DeepMind explicitly stated in the Gemini technical report that the Gemini series was multimodal-native from its inception, rather than having visual capabilities added later to a language model foundation. This design means that when the model understands the text instruction "Studio Ghibli animation style," it can directly activate visual feature representations associated with that style — soft color tones, hand-drawn line textures, specific lighting treatment methods — without requiring secondary translation from text to image, achieving more precise style-semantic alignment. Rather than stitching visual understanding and generation together as independent modules, it processes text, image, and video information simultaneously within a unified model framework. This end-to-end design enables the model to better understand user intent and generate matching visual output.
Application Scenarios for Gemini Omni Video Style Transfer
The potential application scenarios for this feature are extremely broad:
- Content Creators: Short-video creators can quickly give their work distinctive visual styles, enhancing content recognition
- Brand Marketing: Companies can transform product videos into different artistic styles, adapting to different platforms and audiences
- Education: Transform instructional videos into animation styles, enhancing learning engagement
- Personal Users: Turn everyday family videos into artistic works, adding a sense of ceremony to daily life
Competitive Landscape and Future Trends
Video style transfer is not a track exclusive to Google. Current major players in the AI video generation and editing space show clear divergence in technical approaches. OpenAI's Sora uses a Diffusion Transformer (DiT), representing video data as Spacetime Patches, with its core advantage in generating entirely new videos from text rather than stylizing existing videos. Runway's Gen series and Pika focus more on video editing workflows, offering keyframe control, motion brushes, and other fine-grained operation tools targeting professional creators. Stability AI's Stable Video Diffusion takes an open-source route, allowing developers to deploy locally and perform customized fine-tuning.
In comparison, Google's strategy is to deeply integrate video capabilities into Gemini as a unified multimodal platform, leveraging the Google account ecosystem and YouTube's content distribution channels to directly reach ordinary consumers. This "platform integration" rather than "standalone product" approach enables Gemini's video features to create synergies with Search, Gmail, Google Docs, and other products, building an ecosystem moat that competitors find difficult to replicate. From a longer-term perspective, competition in video generation technology will ultimately shift from single-capability comparisons to comprehensive contests involving data flywheels, inference costs, and ecosystem integration.
From a broader perspective, AI video editing is undergoing a paradigm shift from "tool-assisted" to "intent-driven." Future video creation may no longer require complex timeline editing and parameter adjustments — creators will only need to clearly express "what I want," and AI will handle everything from understanding to execution.
This is not just technological progress but another milestone in the democratization of creation. When technical barriers are no longer obstacles, what truly determines work quality will return to creativity itself — and that is precisely what humans excel at most.
Key Takeaways
- Gemini Omni supports converting videos or photos into entirely new visual styles through natural language instructions, with an extremely low barrier to entry
- The feature is based on Gemini's native multimodal architecture, processing text, image, and video information simultaneously within a unified framework, avoiding the semantic gap of traditional stitched approaches
- Video style transfer requires solving core technical challenges such as inter-frame temporal consistency; Gemini Omni's breakthrough marks the maturation of Google's video generation technology
- AI style transfer technology has undergone a decade of evolution from CNN neural style transfer, through GANs, to diffusion models — Gemini Omni is the culmination of this accumulation
- Application scenarios span content creation, brand marketing, education, and many other fields
- AI video editing is shifting from tool-assisted to intent-driven paradigms, advancing the democratization of creation
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.