Getting Started with AI Agents: A Complete Learning Path from Zero to Production

Complete beginner's guide to AI Agent architecture, core paradigms, and production deployment strategies.
This article systematically explains AI Agent fundamentals including the three core modules (planning, memory, tool use), the ReAct reasoning-action paradigm, multi-agent collaboration patterns, and RAG integration. It covers common development challenges like hallucinations and context window limits, lightweight deployment strategies, and provides a structured learning path from zero knowledge to production-ready Agent systems.
Why Now Is the Best Time to Learn AI Agents
During China's 2025 Spring Festival Gala, the appearance of five humanoid robots and Doubao-powered interactive agents brought the concept of AI Agents into the mainstream spotlight. From a niche technical term in the tech community to a hot topic among the general public, AI Agents are becoming the most exciting direction in the AI field.
For learners looking to break into AI, Agents offer an excellent entry point — unlike large model training, which demands deep mathematical expertise and massive computing resources, Agent development focuses more on architecture design, workflow orchestration, and business implementation, making it accessible even to those with zero coding experience. A content creator on Bilibili shared a systematic Agent learning roadmap, spanning from foundational concepts to production deployment across a six-week study plan. Let's break down the core knowledge points in this learning framework.

AI Agent Core Architecture: Understanding the Agent's "Brain"
What Is an AI Agent?
An AI Agent is essentially an AI system capable of autonomously perceiving its environment, formulating plans, and executing actions. Unlike traditional chatbots, an Agent can not only answer questions but also invoke tools, decompose tasks, make independent decisions, and even collaborate with other Agents to accomplish complex objectives. If traditional chatbots operate in a passive "you ask, I answer" mode, then Agents operate in an active "give me a goal, and I'll figure out how to achieve it" mode. This shift from passive response to active execution is the fundamental reason why Agents are driving industry transformation.
Planning, Memory, and Tool Use: The Three Core Modules
The first step in learning about Agents is understanding the three core modules in their architecture:
-
Planning Module: How an Agent decomposes a complex task into executable sub-steps. This involves techniques like Chain-of-Thought (CoT) and task decomposition. Chain-of-Thought (CoT) is a prompting technique proposed in 2022 by Jason Wei and colleagues at Google Research. Its core idea is to guide large language models to show intermediate reasoning steps before providing a final answer. The inspiration comes from how humans solve complex problems — we don't jump directly to the answer but instead lay out our reasoning steps. In an Agent's planning module, CoT enables the model to break down a request like "book me a flight to Shanghai next Wednesday" into ordered steps: searching for flights, comparing prices, confirming times, and executing the booking. Subsequent developments like Tree-of-Thought and Graph-of-Thought further enhanced complex reasoning capabilities.
-
Memory Module: Includes short-term memory (current conversation context) and long-term memory (historical interactions, knowledge bases). The memory mechanism determines whether an Agent can maintain coherence across multiple interaction rounds.
-
Tool Use: The Agent's "hands and feet" — performing actual operations by calling external tools like search engines, databases, and code executors through APIs.
The coordinated operation of these three modules constitutes the critical leap from an Agent that "can chat" to one that "can get things done."
How Agents Work: Key Paradigms
The ReAct Paradigm: The Agent's Core Action Framework
In the Agent technology stack, ReAct (Reasoning + Acting) is one of the most mainstream working paradigms. The ReAct paradigm was formally introduced in 2022 by teams from Princeton University and Google Brain in the paper "ReAct: Synergizing Reasoning and Acting in Language Models." Before this, the industry's use of large models was split into two separate directions: pure reasoning (like Chain-of-Thought) and pure action (like directly calling APIs). ReAct's breakthrough was interleaving both together. Its theoretical foundation traces back to "situated cognition" theory in cognitive science — human thinking and action are not isolated but dynamically evolve through continuous interaction with the environment.
Its core workflow alternates between Reasoning and Acting:
- Thought: Analyze the current state and decide what to do next
- Action: Invoke a tool or execute an operation
- Observation: Obtain the results of the action
- Loop: Continue thinking and acting based on observation results
This "think one step, do one step" approach allows Agents to dynamically adjust strategies rather than committing to a rigid plan from the start. Understanding the ReAct paradigm is a key turning point in mastering Agent development. It's worth noting that after ReAct, improved paradigms like Reflexion (adding self-reflection mechanisms) and LATS (combining Monte Carlo Tree Search for planning) have emerged, but ReAct remains the foundation for understanding how Agents work.
Core Challenges in Agent Development
The most common challenges encountered when developing Agents in practice include:
-
Hallucination Issues: The large model may generate inaccurate tool invocation parameters. For example, an Agent calling a search API might fabricate a non-existent function name, or generate syntactically incorrect SQL queries when accessing a database. This is essentially the large language model's tendency to "confidently make things up" amplified in tool-calling scenarios.
-
Loop Traps: An Agent repeatedly executes the same operation at certain steps. For instance, an Agent searching for information that doesn't get satisfactory results might infinitely repeat the same search request without knowing to try a different strategy. Setting maximum iteration counts and implementing "infinite loop detection" mechanisms are common solutions.
-
Context Window Limitations: Long task chains may exceed the model's processing capacity. The context window refers to the maximum number of tokens a large language model can process in a single inference. Tokens are the basic units of text processing — in Chinese, roughly 1-2 tokens per character. Although mainstream models in 2024-2025 have expanded windows to 128K or longer, each round of thinking, acting, and observing accumulates token consumption, and complex tasks involving a dozen steps can easily exceed the window limit. Industry solutions include summarizing and compressing historical information, sliding window mechanisms, and storing intermediate results in external memory systems.
Solutions to these problems often require effort in prompt engineering, error handling mechanisms, and task orchestration strategies.
Advanced Capabilities: Multi-Agent Collaboration and RAG Integration
How Multi-Agent Systems Work Together
A single Agent's capabilities are ultimately limited. Truly powerful systems are often completed through collaboration among multiple specialized Agents. The concept of Multi-Agent Systems (MAS) originated in distributed artificial intelligence and can be traced back to the 1980s. In the current LLM-driven Agent ecosystem, a typical multi-agent collaboration scenario might look like this:
- One Agent handles information retrieval
- One Agent handles data analysis
- One Agent handles content generation
- A "manager" Agent handles task assignment and quality control
The key to multi-agent collaboration lies in communication protocol design and task allocation strategies. There are currently three mainstream architectural patterns: first, centralized architecture, where a "manager" Agent coordinates uniformly, similar to a project manager in a company; second, decentralized architecture, where Agents communicate as equals and negotiate autonomously, similar to open-source community collaboration; third, hierarchical architecture, where Agents form superior-subordinate relationships and decompose tasks layer by layer. Regarding communication protocols, Anthropic's MCP (Model Context Protocol) and Google's A2A (Agent-to-Agent) protocol are becoming important industry reference frameworks, defining how Agents pass task descriptions, status information, and execution results to each other. Mastering multi-agent architecture design is also the dividing line between junior developers and senior architects.
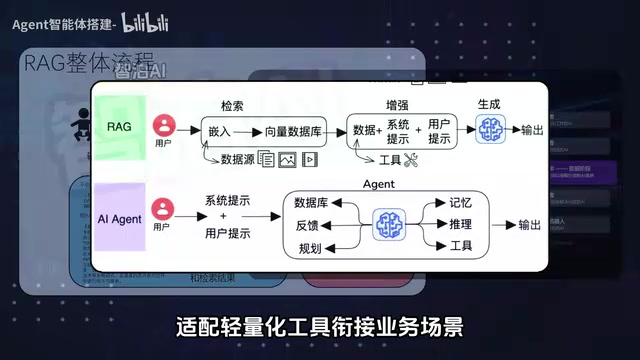
Deep Integration of RAG and Agents
The combination of RAG (Retrieval-Augmented Generation) with Agents is one of the most practically valuable technical directions today. RAG was first proposed by the Meta AI team in 2020 to address large language models' knowledge cutoff dates and hallucination issues. Its basic workflow has three steps: first, enterprise documents are converted into vectors through an Embedding model and stored in a vector database (such as Milvus, Pinecone, or Chroma); then, when a user asks a question, the most relevant document chunks are retrieved through semantic similarity; finally, the retrieval results are sent to the large model along with the user's question to generate an answer.
In 2024-2025, RAG technology evolved from Naive RAG to Advanced RAG to Modular RAG, introducing optimization strategies like query rewriting, hybrid retrieval, reranking, and adaptive retrieval. By using RAG as the Agent's knowledge retrieval tool, intelligent agents can make decisions based on proprietary enterprise data and the latest information rather than relying solely on the large model's training data. More importantly, when RAG is combined with Agents, retrieval is no longer a one-time passive operation but a tool that Agents can actively, repeatedly, and strategically invoke — achieving a qualitative leap from "passive Q&A" to "active exploration."
This integration has broad application prospects in customer service systems, knowledge management, and business process automation.
Production Deployment: From Demo to Production Environment
Lightweight Deployment Strategies
Not every scenario requires a GPT-4-level large model. In actual business settings, lightweight deployment often offers better cost-effectiveness:
- Using open-source smaller models (such as Qwen, GLM series) to reduce costs. Taking Alibaba's Qwen series as an example, its 7B parameter version can run on a single consumer-grade GPU, and when fine-tuned for specific tasks, its performance can approach or even exceed general-purpose large models.
- Fine-tuning for specific scenarios to achieve large model performance with smaller models. Fine-tuning refers to secondary training of a pre-trained model using domain-specific data, dramatically improving the model's performance in that domain. Currently popular parameter-efficient fine-tuning techniques like LoRA and QLoRA can complete fine-tuning at extremely low computational costs.
- Designing Agent architecture thoughtfully to reduce unnecessary model invocation counts. Each large model call means time latency and API costs. Through caching mechanisms, conditional logic, and task pre-filtering, model invocation counts can be reduced by over 50%.
Business Scenario Adaptation and Integration
The last mile of Agent deployment is connecting technical capabilities with specific business requirements. This requires:
- Requirement Decomposition: Clarify business objectives and identify which processes are suitable for Agent intervention. Not all business processes are suitable for Agent-ification — processes with clear rules and fixed workflows might be more efficiently handled by traditional automation tools, while processes requiring flexible judgment and multi-source information integration are where Agents truly shine.
- Scenario Customization: Design dedicated tool sets and workflows based on industry characteristics
- Compatibility Solutions: Handle integration with existing systems, including API connections with enterprise ERP, CRM, OA systems, as well as compliance requirements for data security and permission management.
- Performance Evaluation: Establish quantitative metrics and continuously optimize Agent performance. Common evaluation dimensions include task completion rate, response time, user satisfaction, and hallucination rate.

AI Agent Learning Recommendations and Roadmap Summary
For learners starting from zero, the following recommendations are worth considering:
- Understand concepts before hands-on practice: Don't rush to write code — first get a clear understanding of Agent core architecture and working principles
- Start with a single Agent: Build a fully functional single Agent before attempting multi-agent collaboration
- Prioritize prompt engineering: In Agent development, prompt design is just as important as writing code. A carefully crafted System Prompt can define the Agent's role, capability boundaries, output format, and behavioral guidelines, directly determining the Agent's performance ceiling.
- Follow open-source frameworks: Frameworks like LangChain, AutoGen, and CrewAI can significantly lower the development barrier. LangChain has the most complete ecosystem, offering full-chain capabilities from model invocation to tool integration; AutoGen, developed by Microsoft Research, has core strengths in multi-agent conversation orchestration; CrewAI uses the "AI team" metaphor and has a lower learning curve. Additionally, low-code platforms like Dify and Coze allow non-technical users to build Agent applications through visual interfaces, making them ideal starting points for learners with zero coding background.
The AI Agent wave has only just begun. Whether you're a technical practitioner or a business professional, mastering the core logic and application methods of Agents will give you a head start in the coming AI era. The key isn't how fast you learn, but how deeply you understand and how practically you implement.
Related articles
The Decline of Tokenmaxxing: Why Selling Outcomes Matters More Than Selling Tokens
The Tokenmaxxing craze is fading as enterprise AI procurement shifts from chasing Token counts to focusing on actual business outcomes. Learn why outcome-based AI evaluation is the right approach.
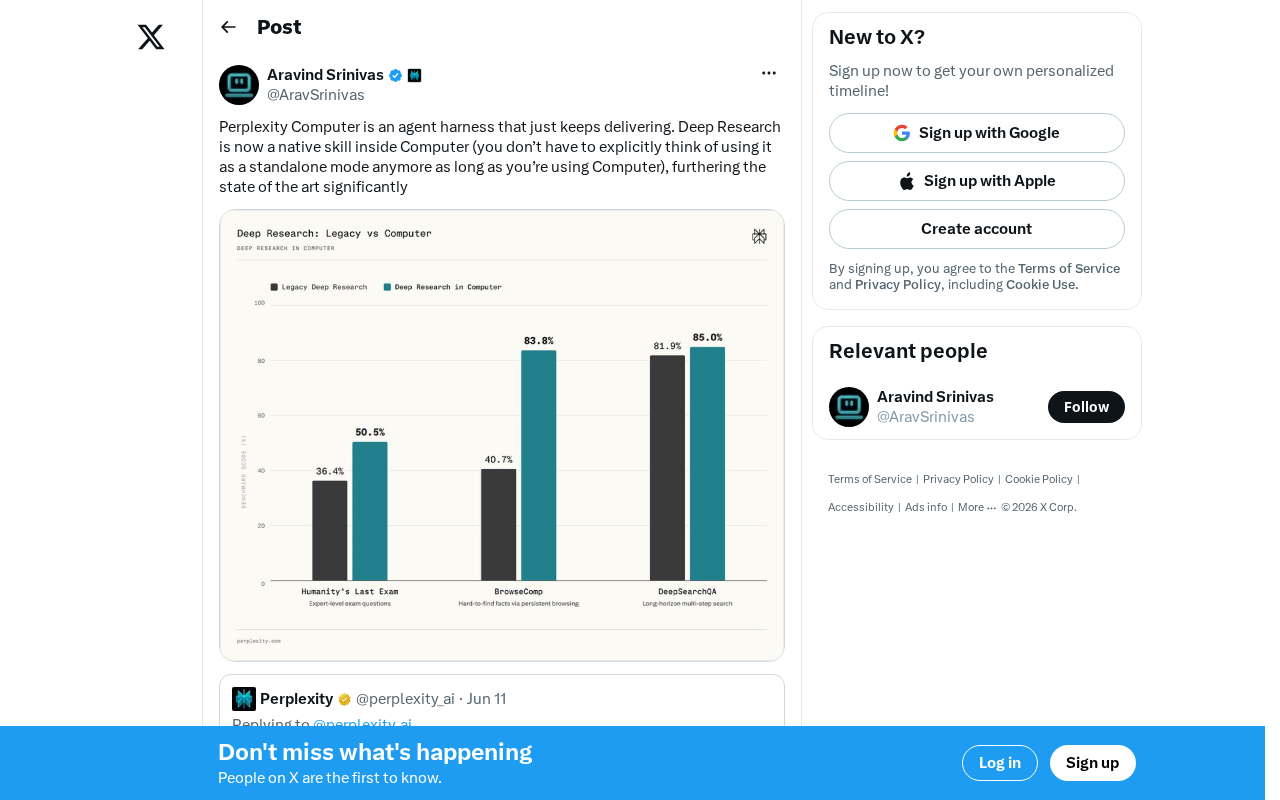
Perplexity Computer Integrates Deep Research as a Native Skill: A New Paradigm for AI Agent Capability Fusion
Perplexity integrates Deep Research as a native skill in Computer, enabling automatic invocation without manual mode switching. Analyzing the Agent Harness design philosophy and AI capability fusion trends.

Key Takeaways from Andrew Ng × OpenAI's Prompt Engineering Course: Two Core Principles Explained
Deep dive into Andrew Ng & OpenAI's ChatGPT Prompt Engineering course: Base LLM vs instruction-tuned models, two core prompting principles, and API-first development thinking for developers.