Getting Started with AI Full-Stack Development: A Knowledge Framework from Machine Learning to Large Language Models

A structured learning path guide from machine learning to large language models for developers.
Based on the introductory module of an AI full-stack development course, this article systematically maps the hierarchical relationships between artificial intelligence, machine learning, deep learning, and large language models, while tracing the technological evolution from Big Data to Transformer architectures. It advocates a spiral learning approach—concepts first, alternating between theory and practice—to help developers of varying backgrounds find an efficient path into AI development.
For developers looking to break into the field of AI and large language models (LLMs), a common source of confusion is: How much machine learning do I need to learn? To what depth should I master deep learning? And what exactly is the relationship between all these concepts? Based on the introductory module of an AI full-stack development course, this article systematically maps out the knowledge landscape from machine learning to large models, helping readers with different backgrounds find the learning path that suits them best.
Course Positioning: Balancing Zero-Basis Fundamentals with Hands-On Projects
The design philosophy of this course is clear: the introductory module handles conceptual foundations, while subsequent chapters dive into hands-on practice organized by technology domain. The overall structure includes an introductory module (theoretical foundations), followed by sections on DeepSeek, Dify, MCP, FastGPT, enterprise applications, as well as model architecture and training.
For absolute beginners, the goal of the introductory module is to help you understand concepts rather than implement them. For example, you need to know that machine learning is divided into three major categories—supervised learning, unsupervised learning, and semi-supervised learning—and understand the relationship between deep learning and neural networks. But you don't need to write machine learning algorithms from scratch.
Background: The Essential Differences Between Three Learning Paradigms Supervised learning trains models using labeled data—for example, image classification where each image is annotated with a category. Unsupervised learning automatically discovers structure from unlabeled data, such as clustering algorithms. Semi-supervised learning falls between the two, leveraging a small amount of labeled data alongside large volumes of unlabeled data for training. Notably, the pre-training phase of large language models is essentially self-supervised learning—a special form of unsupervised learning where the model learns language patterns from massive text corpora by predicting the next token, without requiring human annotation. This is the key reason why large models can leverage internet-scale data.
For those already working in the AI industry (such as AI operations or application development), this section can be skimmed quickly, with focus placed on the subsequent hands-on chapters.
The course primarily uses the DeepSeek large model for application development, covering Agent technology, quick-start with the MCP protocol, Dify workflow orchestration, integration with messaging ecosystems like WeChat and DingTalk (NandBot), and both theory and practice of DeepSeek distillation techniques.
The AI Technology Landscape: A Venn Diagram to Clarify Concept Relationships
Understanding the relationships between various AI concepts is a prerequisite for establishing the right learning path. The course presents a highly valuable Venn diagram of AI technologies.
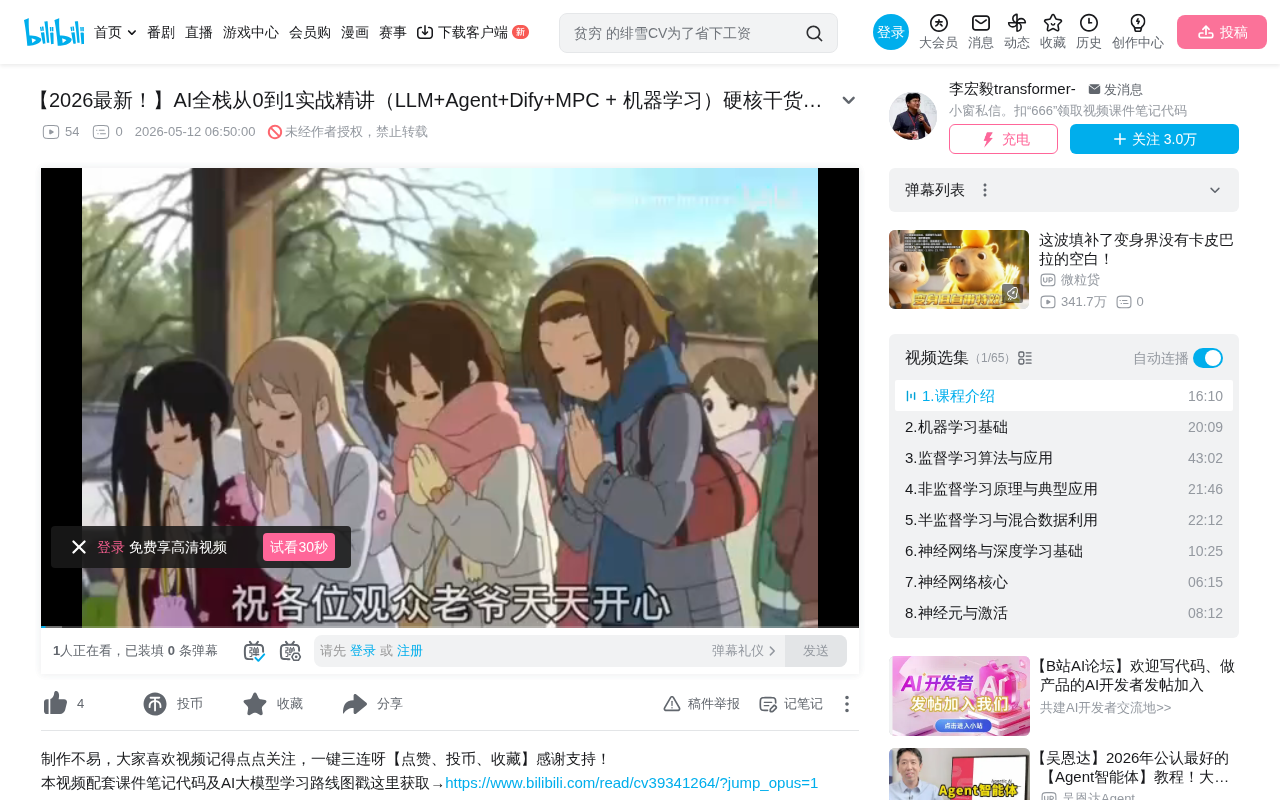
From this diagram, several key relationships emerge:
- Artificial Intelligence is the broadest conceptual category
- Neural Networks have a very wide scope, with Deep Learning being a subset
- Deep Learning overlaps with and partially covers Pattern Recognition and Machine Learning
- Big Data, Data Science, and other fields are related to AI but each has its own focus
This hierarchical relationship can be simplified as: Artificial Intelligence > Machine Learning > Deep Learning. From an algorithmic perspective, machine learning is essentially a method for automatically learning patterns from data, deep learning achieves this learning through the specific algorithmic form of neural networks, and large language models are fundamentally deep neural networks—but given today's developments, the influence of large models has far exceeded the label of "deep learning."
The Data Science Triangle: Mathematics, Computer Science, and Domain Knowledge
The course also presents another important interdisciplinary perspective, dividing related fields into three pillars:
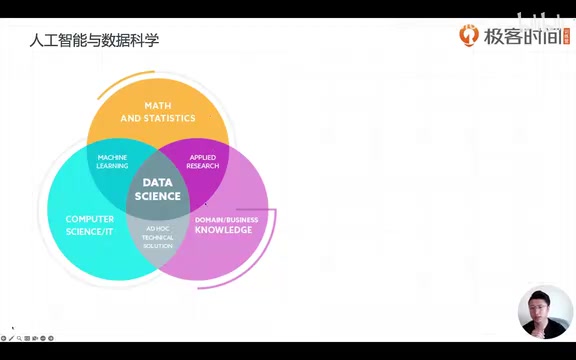
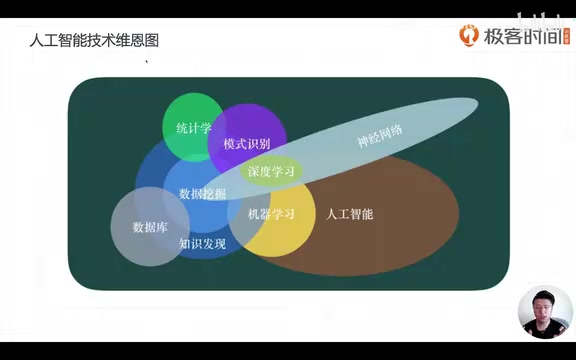
- Mathematics & Statistics — Statistics can discover patterns from samples and forms the mathematical foundation of machine learning
- Computer Science / Information Technology — Provides algorithm implementation and engineering capabilities
- Domain Knowledge / Business Knowledge — Determines how technology is applied in practice
Machine Learning sits precisely at the intersection of mathematics/statistics and computer science. This explains why learning machine learning requires a certain mathematical foundation (such as solving optimization problems), but is not entirely equivalent to pure mathematical research.
An interesting evolutionary path: many technologies initially emerged as ad hoc solutions—addressing specific business problems using computational methods. When these solutions were found to be horizontally applicable to other scenarios, they gradually became productized, evolving from solutions into products, and sometimes even into research directions or academic disciplines.
The Rise and Fall of Tech Buzzwords: From Big Data to Large Models
The course offers a highly insightful observation: the popularity of technical terms reflects the stage of technological development.
Around 2015, "Big Data" was the hottest buzzword. Technologies like Hadoop, MapReduce, and Spark—driven by Google—enabled people to store and process massive internet-scale data, giving rise to applications like Taobao's recommendation algorithms.
Background: The Historical Context of Big Data Technologies Hadoop is an open-source distributed computing framework developed by the Apache Foundation, with its core ideas derived from Google's GFS and MapReduce papers published in 2003-2004. MapReduce decomposes large-scale data processing into two phases—Map and Reduce—enabling clusters of commodity servers to process petabyte-scale data. Later, Spark replaced disk I/O with in-memory computation, improving processing speed by orders of magnitude. This technological wave gave rise to professions like data engineers and data analysts, and paved the way for the large-scale training data infrastructure that machine learning would later require. Today, these technologies have matured into data warehouses, data lakes, and other established engineering infrastructure—no longer in the spotlight, but their value has never diminished.
The same pattern occurred in deep learning. A few years ago, TensorFlow and PyTorch were the hottest frameworks, but now the focus has shifted to Hugging Face Transformers built on top of them—because the latter directly addresses large language models, a newer technological layer.
Background: The Rise of the Hugging Face Ecosystem Hugging Face is an AI company founded in 2016 whose open-source Transformers library has become the de facto standard toolkit in the NLP and large model space. It provides a unified API that wraps hundreds of pre-trained models including BERT, GPT, LLaMA, DeepSeek, and more. Developers don't need to implement complex Transformer architectures from scratch—just a few lines of code to load and use state-of-the-art models. The Hugging Face Hub, as a model hosting platform, currently hosts over 500,000 public models, dramatically lowering the barrier to LLM application development. It's one of the core ecosystems that today's AI full-stack developers must be familiar with.
Old technical terms may no longer be mentioned, but their substance remains rich, and their shadows can still be seen in new technologies. New technologies are like ability radar charts—when a breakthrough occurs in one dimension, people give it a new name, while the larger category it belongs to is no longer emphasized because it's not precise enough.
The takeaway for learners: don't get caught up chasing every hot buzzword. Instead, understand the internal logic of technological evolution.
Two Core Lessons in the Introductory Module
Lesson 1: Theoretical Foundations of Machine Learning and Deep Learning
Key topics include:
- Three categories of machine learning: supervised learning, unsupervised learning, semi-supervised learning
- Neural networks as the prototype of deep learning
- The evolution of deep learning: increasing layer depth, optimization algorithm improvements, iterations in compute power and data
- Core concepts like neurons and activation functions
Lesson 2: The Full Landscape of Large Model Development and Key Technologies
Focusing on the Transformer architecture:
- Evolution from classic deep learning architectures like CNN and RNN to Transformer
- Attention mechanism → Self-attention mechanism → Multi-head attention mechanism
- Introduction of positional encoding
- Technical iterations and breakthroughs from 2017 to the present
- DeepSeek's "catfish effect" on research directions
Background: Why the Transformer Architecture Is Revolutionary Transformer is a revolutionary architecture proposed by a Google team in the 2017 paper Attention Is All You Need. Before this, sequence modeling tasks primarily relied on RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks), which suffered from inherent limitations like vanishing gradients and inability to parallelize computation. Transformer completely abandoned recurrent structures, relying solely on attention mechanisms to handle sequential relationships. This not only solved the long-range dependency problem but also dramatically improved training parallelism, laying the unified architectural foundation for subsequent large language models like GPT, BERT, and DeepSeek.
The Core Principle of Attention Mechanisms: Attention mechanisms were originally designed to solve the alignment problem in machine translation—traditional models compressed entire input sentences into fixed-length vectors, causing information loss for long sentences. Attention mechanisms allow the model to dynamically "attend to" different positions in the input sequence when generating each output token, assigning different weights. Self-Attention further enables every token within a sequence to compute relevance with all other tokens, capturing intra-sentence semantic dependencies. Multi-Head Attention runs multiple attention computations in parallel, capturing various semantic relationships from different subspaces—one of the core reasons for Transformer's powerful performance.
Background: DeepSeek's Catfish Effect DeepSeek is a series of large language models released by DeepSeek AI (headquartered in Hangzhou) starting in late 2023. In early 2025, DeepSeek-R1 achieved reasoning capabilities comparable to OpenAI's o1 at an extremely low training cost (reportedly around $6 million), sending shockwaves through the global AI community. Its core technical innovations include: Mixture of Experts (MoE) architecture that dramatically reduces inference computation, reinforcement learning-driven chain-of-thought training (GRPO algorithm), and aggressive model distillation strategies. DeepSeek's emergence shattered the perception that "large models require billions of dollars in compute investment," reigniting research enthusiasm in academia and the open-source community for efficient training methods—dubbed the "catfish effect" on the US AI monopoly landscape.

Learning Advice: Concepts First, Depth in Moderation
A core principle repeatedly emphasized throughout the course is: Understanding concepts—knowing what something is, what it's used for, and why it exists—is enough. You don't need to work through all the theoretical derivations of machine learning and deep learning during the introductory phase.
This "spiral learning" methodology is worth adopting: first establish a conceptual framework, then gradually deepen theoretical understanding through practice—alternating between hands-on work and theory. For engineers looking to transition into AI full-stack development, this is likely the most efficient learning path: invest your limited energy in understanding core concepts and hands-on practice, rather than spending excessive time on mathematical derivations.
Key Takeaways
- AI full-stack development learning path: the introductory module covers conceptual foundations (machine learning, deep learning, Transformer), while subsequent chapters provide hands-on practice with DeepSeek, Dify, MCP, and other technology domains
- The hierarchical relationship of core AI concepts: Artificial Intelligence > Machine Learning > Deep Learning; large language models are fundamentally deep neural networks but their influence has transcended traditional classifications
- The rise and fall of tech buzzwords reflects development stages: hot terms like Big Data and deep learning frameworks are gradually superseded by higher-level concepts (such as large language models and Transformers)
- Learning methodology: adopt spiral learning where conceptual understanding takes priority over mathematical derivation, with practice and theory alternating as the most efficient transition path
- The Transformer architecture is key to understanding large models: from attention mechanisms to self-attention, multi-head attention, and positional encoding—these form the technological cornerstone of modern large models
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.