Getting Started with Huawei Ascend C Operator Programming: Kernel Functions and Hands-On Development Guide

A comprehensive guide to Huawei Ascend C operator programming with kernel functions and hands-on development.
This article systematically covers Huawei Ascend C operator programming, including kernel function concepts, the three-stage pipeline paradigm (Copy In, Compute, Copy Out), double buffering mechanisms, and the four-category API system. It walks through a complete AddCustom addition operator development workflow — from project creation and implementation to building, running, and verification — helping developers quickly get started with Ascend chip operator development.
Huawei Ascend C is an operator programming language designed for AI Core, using C++-like syntax that enables developers to efficiently write compute operators that run on Ascend chips. Based on the second chapter of the official Ascend C tutorial, this article systematically covers the core knowledge from C++ fundamentals to complete operator development, helping developers quickly build a solid understanding of operator programming.
Kernel Functions: The Core Concept of Ascend C Operator Development
The Kernel Function is the most fundamental concept in Ascend C operator development. It is a compute function that runs on the AI Core, responsible for executing the operator's core computation tasks. Kernel functions are launched from the Host side and executed in parallel on the Device side — think of them as parallel compute units running on the Ascend chip, where each kernel function instance processes a portion of the data, ultimately working together to complete the entire operator's computation.
The concept of kernel functions originates from heterogeneous computing programming models, first popularized by NVIDIA CUDA. In a heterogeneous computing architecture, the system consists of a general-purpose processor (Host, typically a CPU) and a specialized accelerator (Device, such as a GPU or NPU). The Host handles program control flow and data preparation, while the Device handles massively parallel computation. As the core compute unit within the NPU, Huawei Ascend's AI Core architecture is deeply optimized for matrix and vector operations, featuring dedicated Cube compute units (for matrix multiplication) and Vector compute units (for vector operations). This means kernel functions must be written with hardware characteristics in mind to achieve maximum performance.
Writing kernel functions requires following specific syntax conventions:
- Use the
__kernel__type qualifier to mark the entry function - Entry parameters must match the hardware's vector computation width
- Use the
__aicore__call prefix to indicate the function will execute on the AI Core
These special qualifiers and prefixes are the key markers that distinguish kernel functions from ordinary C++ functions.

The kernel function invocation flow follows a fixed procedure: first, complete device initialization on the Host side through AscendCL interfaces, then create execution streams and events, configure kernel function parameters and launch execution, and finally perform stream synchronization to wait for computation to complete. AscendCL (Ascend Computing Language) is the unified programming interface for Huawei Ascend AI processors, similar to NVIDIA's CUDA Runtime API. It provides a suite of fundamental capabilities including device management, memory management, model inference, and operator invocation. Developers use AscendCL to perform device initialization (aclInit), context creation (aclrtCreateContext), stream management (aclrtCreateStream), and other operations. The "Stream" is a key concept here — it represents an ordered operation queue where operations within the same stream execute sequentially, while operations across different streams can execute in parallel, providing the foundation for operator-level parallel scheduling. Understanding this invocation flow is a prerequisite for correctly deploying operators and a key area for troubleshooting runtime errors.
Ascend C Programming Paradigm: The Three-Stage Pipeline Model
Ascend C employs a structured three-stage model to organize the operator execution flow, clearly separating data flow, computation logic, and concurrency control.
The Three-Step Data Flow Pattern
Data flow follows a "Copy In → Compute → Copy Out" three-step pattern:
- Copy In: Data is transferred from global memory into the AI Core's local buffer
- Compute: Core computation is performed in the local buffer
- Copy Out: Results are transferred back to global memory
This pattern ensures that compute units always have data available, maximizing hardware utilization efficiency.
Three Execution Stages and Pipeline Parallelism
Ascend C defines three execution stages: the Pipe stage handles data transfer, the Compute stage handles core computation, and the Complex stage enables custom pipeline orchestration. The key insight is that these three stages execute in parallel within the pipeline — while the Compute stage processes the current data block, the Pipe stage is already prefetching the next data block. This overlapping execution model is critical for achieving high performance.
The three-stage pipeline model draws inspiration from classic processor pipeline techniques. In AI chips, global memory (typically HBM or DDR) access latency is far higher than local SRAM access latency — potentially by tens to hundreds of times. If a serial "copy in - compute - copy out" approach is used, the compute units sit completely idle during data transfers, resulting in extremely low hardware utilization. Pipeline parallelism divides data into multiple blocks (tiles) and has different stages simultaneously process different data blocks, allowing data transfer latency to be masked by the computation process. This technique is known as "Latency Hiding" in the high-performance computing field and is a core optimization strategy for fully leveraging AI chip compute power.
Double Buffering Mechanism
Vector programming employs a double buffering mechanism that prefetches the next batch of data while computing the current data, effectively hiding memory access latency. Through TPipe, developers can conveniently build double-buffered pipelines, achieving seamless overlap between data transfer and computation.
Double buffering is one specific implementation of pipeline parallelism. Its core idea is to allocate two equally-sized buffer areas (Buffer A and Buffer B) in local storage. While the compute unit processes data in Buffer A, the DMA (Direct Memory Access) engine simultaneously transfers the next batch of data into Buffer B. When computation on Buffer A completes, the compute unit immediately switches to Buffer B to continue computing, while the DMA engine loads new data into the now-free Buffer A. This ping-pong alternating pattern ensures the compute unit is almost never idle waiting for data. In Ascend C, the TPipe and TQue designs are specifically intended to simplify double-buffered pipeline construction — developers only need to set the queue depth to 2 to automatically enable double buffering.
Ascend C API System: Four Major Categories Explained
Ascend C provides a rich API system, divided into four major categories by function:
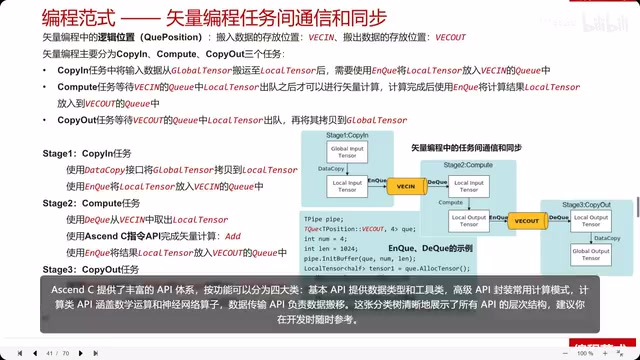
Basic APIs
Basic APIs are the foundation for building all operators:
- GlobalTensor: Represents a tensor in global memory
- LocalTensor: Represents a tensor in the local buffer
- TPipe: Builds data pipelines
- TQue: Manages data queues within pipelines
- TBuf: Manages buffers
The distinction between GlobalTensor and LocalTensor reflects the memory hierarchy of Ascend chips. Ascend AI processors typically contain multiple storage levels: the outermost is the Host-side system memory, followed by Device-side global memory (Global Memory, typically HBM — High Bandwidth Memory), and the innermost is each AI Core's private local memory (SRAM such as Unified Buffer and L1 Buffer). Global memory has large capacity but high access latency, while local memory has small capacity but extremely fast access speeds. GlobalTensor corresponds to the data view in global memory, and LocalTensor corresponds to the data view in local memory. Developers need to explicitly manage data movement between different levels using APIs like DataCopy — similar to the relationship between global memory and shared memory in GPU programming.
Compute APIs
These provide rich mathematical operations and neural network operators:
- Basic operations: Add, Sub (subtraction), Mul (multiplication), Max/Min
- Activation functions: ReLU, Sigmoid
- Matrix operations: MatMul, ReduceMax, ReduceMin
These APIs map directly to AI Core hardware instructions at the low level. For example, vector addition is compiled into SIMD instructions for the Vector compute unit, and matrix multiplication is mapped to systolic array instructions for the Cube compute unit. When developers call these high-level APIs, the compiler automatically handles instruction scheduling, register allocation, pipeline arrangement, and other low-level details, significantly lowering the development barrier.
Data Transfer APIs
- DataCopy: Supports bulk copying of contiguous data blocks
- DataMove: More flexible element-level movement
- Get/Set methods: Read and write specific elements in tensors
Hands-On: Complete Development Workflow for the AddCustom Addition Operator
Requirements Analysis
The AddCustom operator takes two input tensors, performs element-wise addition, and outputs a result tensor. The data types, shape constraints, and supported hardware platforms for inputs and outputs need to be clearly defined.
In real-world operator development, input data sizes often far exceed the local memory capacity of a single AI Core, so data must be divided into multiple small blocks (tiles) for batch processing — a process called Tiling. The Tiling strategy design directly impacts operator performance: blocks that are too large cause local memory overflow, while blocks that are too small increase data transfer frequency and pipeline startup overhead. A good Tiling strategy must comprehensively consider local memory capacity, data alignment requirements (Ascend chips typically require 32-byte alignment), vector computation width, and other hardware constraints. In the AddCustom operator, developers need to determine the data block size and loop count for each processing iteration based on the total input tensor size and the AI Core's local memory capacity.
Four-Step Development Workflow

Step 1: Create the Operator Project
Use the Ascend command-line tool to automatically generate a project template. The generated directory structure includes:
kernel/: Stores kernel function implementationshost/: Stores Host-side codescripts/: Stores build and run scriptsCMakeLists: Configures build options
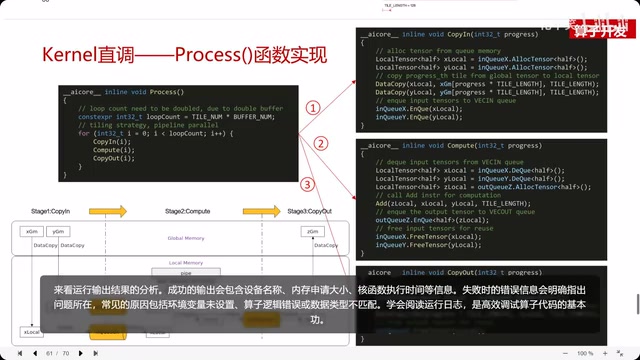
Step 2: Write the Operator Implementation Code
Implement the element-wise addition logic in the kernel function: first define the pipe object and buffers, transfer input data into local tensors through the pipe, use the Add interface to perform element-wise addition, and finally transfer the computation results back to global memory.
The Host-side code executes in the order of device initialization → memory allocation → data copy → kernel function launch.
Step 3: Write Build and Run Scripts
SCons is the recommended build tool for Ascend C, using SConstruct files to define compilation options, dependencies, and target files. SCons is a Python-based open-source software build tool. Unlike traditional Make/CMake, it uses Python scripts to describe build rules, offering advantages such as cross-platform support, precise dependency analysis, and easy extensibility. Huawei chose SCons as the recommended build tool primarily because operator compilation involves cross-compilation — Host-side code is compiled with a standard compiler, while Device-side kernel functions require the Ascend-specific compiler — and SCons' flexibility makes this multi-target compilation workflow easier to manage. In the SConstruct file, developers can specify chip model, compilation optimization level, header file paths, link libraries, and other key parameters. The run.sh script is responsible for setting environment variables and executing build and run commands.
Step 4: Build, Run, and Verify
After executing run.sh, SCons automatically compiles the kernel function and Host-side code to generate an executable. Successful output will include information such as device name, memory allocation size, and kernel function execution time.
Development Considerations
Several key details require attention during the coding process:
- Data type consistency: Input and output tensor data types must match. Ascend chips support multiple data types including float16, float32, int8, and int32, with different data types corresponding to different computation precision and throughput levels
- Buffer size matching: Local buffers must meet data block size requirements and satisfy hardware alignment constraints (typically 32-byte alignment)
- Pipe depth settings: This affects pipeline parallelism and memory usage. A depth of 2 enables double buffering; greater depth increases parallelism but also increases local memory consumption
- Environment variable configuration: The CANN software package path must be correctly set. CANN (Compute Architecture for Neural Networks) is Huawei Ascend AI processor's heterogeneous computing architecture, comprising a complete toolchain including compiler, runtime libraries, and debugging tools
Operator Engineering: Testing and Automated Verification
In real projects, a complete operator project also includes data generation scripts, result verification modules, and test cases. Taking the data generation script gen_data.py as an example, it is responsible for generating test data that conforms to the operator's input specifications, including specified data types, shapes, and value ranges. Good test data should cover boundary conditions and typical scenarios to thoroughly verify the operator's correctness and robustness.
Through the run package, the entire workflow of compilation, execution, and result verification can be completed with a single command. This automated approach greatly improves development and testing efficiency and is standard practice in industrial-grade operator development. In Huawei's operator development ecosystem, the verification phase typically includes accuracy verification (comparing operator output element-by-element against a CPU reference implementation or PyTorch/NumPy computation results) and performance verification (using Profiling tools to analyze metrics such as operator execution time, memory bandwidth utilization, and compute unit utilization), ensuring the operator meets expectations in both correctness and performance dimensions.
Summary
The learning path for Ascend C operator development can be summarized as: master C++ basic syntax → understand the kernel function mechanism → become familiar with the three-stage programming paradigm → flexibly apply the API system → complete hands-on development. Developers are encouraged to use the AddCustom operator as a baseline template and subsequently practice by modifying the addition to multiplication, subtraction, and other operations, gradually accumulating Ascend operator development experience. For developers with CUDA development experience, the Ascend C programming model shares many conceptual similarities — kernel functions correspond to CUDA Kernels, GlobalTensor corresponds to Global Memory, LocalTensor corresponds to Shared Memory, and TPipe corresponds to CUDA Streams — understanding these correspondences can accelerate the learning process.
Key Takeaways
Related articles

A Gen-Z Woman Making $1.5M/Month: Deconstructing the Growth Methodology Behind AI Apps
Gen-Z indie dev Nicole built 4 hit AI apps earning $1.5M/mo. Deep dive into her industrialized UGC engine, traffic testing system, and minimalist tech stack.
Replit's AI Loops Workflow Explained: Multi-Agent Collaboration Replaces Prompt Engineering
Deep dive into Replit's AI Loops workflow: how orchestrators, parallel agents, and Computer Use Verifiers build automated closed-loop systems through multi-agent collaboration.
Claude Code + Skills: A Practical Guide to AI-Powered Test Case Generation
Learn how to use Claude Code + Skills to auto-generate enterprise-grade test cases. Covers AI Agent vs LLM differences, the four core capabilities, and the complete workflow from requirements to test cases.