GLM-5.2 Deep Dive: Million-Token Context, MIT Open Source & Full-Stack Domestic Chip Training

GLM-5.2 offers 1M-token context, MIT open source, and full domestic chip training amid US AI export controls.
Zhipu launched GLM-5.2 just one day after US export controls cut foreign access to Claude's top models. The model features a truly usable 1-million-token context window, dual thinking modes for agentic engineering, and MIT licensing with full open-source weights promised. Trained entirely on Huawei Ascend 910B chips with zero NVIDIA dependency, it represents a strategic move toward AI sovereignty. While official benchmarks are pending, community tests suggest it rivals Claude Opus in coding tasks, though it lacks native multimodal support and has higher latency in thinking mode.
A Dramatic Contrast Within 48 Hours
On June 12, the U.S. government issued an export control order requiring Anthropic to immediately cut off all foreign users' access to Claude Sonnet 5 and Haiku 5—its two most advanced models. Sonnet 5 had been live for just three days before being forced offline. Anthropic issued a statement that day saying it would comply but disagreed, and promptly sued the U.S. Department of Defense.
Just one day later, on the evening of June 13, Zhipu AI announced that GLM-5.2 was fully available to developers, with a promise to open-source it under the MIT license the following week. Within the same 48-hour window, the world's most powerful closed-source model was shutting its doors while a Chinese open-source model was opening its windows—the timing was surgically precise.
Zhipu's official statement was blunt: "Frontier intelligence should not belong to only a few, nor should it be revocable at any moment by a handful of rules."
There are at least three layers of strategic thinking behind this:
- Providing an open alternative: Offering a viable option for overseas developers cut off from top-tier closed-source models
- Capturing developer mindshare: Securing market positioning among Chinese developers
- Consolidating the open-source niche: Establishing a competitive position for Chinese open-source at the frontier
Only by stacking all three layers can you understand why this "surprise launch" felt so urgent.
One detail must be clarified, though: as of publication, GLM-5.2's standalone API has not yet officially launched. Currently, only users subscribed to the Coding Plan can access it, and full free availability will require a few more days.
Million-Token Context: From Claimed to Truly Usable

GLM-5.2's first core selling point is its 1-million-token ultra-long context window. One million tokens translates to roughly 500,000 Chinese characters—equivalent to about three copies of Dream of the Red Chamber.
The number itself isn't remarkable; several large models currently claim million-level context. But Zhipu repeatedly emphasizes one key phrase—"truly usable." Those two words carry a subtext: many models on the market that claim million-token context often can't actually reach that length in practice—they either lose track of content in the middle or simply throw errors. Zhipu's point is that GLM-5.2's 1 million tokens can genuinely be used to their full extent.
One community test case is particularly compelling: a developer completed approximately 177,000 tokens of work in a single turn on GLM-5.2. More critically, the model automatically discovered a fatal bug during that session—one that had previously gone undetected during manual code review. This shows it doesn't just "hold a lot"—it can actually "do real work" within a large context.
Compared to the previous generation, the improvement is even more striking: GLM-5.1 had a 200,000-token context; GLM-5.2 multiplied that by 5x. For programmers, this means you can feed an entire large codebase in one go for global refactoring, instead of patching things piece by piece.
GLM-5.2's Dual Thinking Modes
GLM-5.2 supports two thinking modes:
- Thinking Mode: The model reasons before answering, suitable for complex programming and logic tasks
- Standard Mode: Gives answers directly, with faster response times
The trade-off is that in Thinking Mode, the first token takes 30 to 60 seconds—impatient users will find this painful.
Zhipu's positioning for GLM-5.2 is also crystal clear—agentic engineering. It's an evolution from the old "vibe coding" approach of writing code by feel, to a model that can plan, execute, and verify on its own across long-horizon agent tasks.
The Benchmark Fog: Don't Misattribute Previous-Gen Scores

Regarding GLM-5.2's benchmarks, a bunch of numbers are already circulating online—77.8, 58.4, 95.3, and so on. But it must be stated clearly: as of now, not a single official benchmark for GLM-5.2 itself has been published. The high scores floating around all come from GLM-5 or GLM-5.1, misattributed to 5.2.
To gauge GLM-5.2's capabilities, we can only reference its predecessors:
| Model | Benchmark | Score | Comparison |
|---|---|---|---|
| GLM-5.1 | SWE-Bench PRO | 58.4 | Surpasses GPT's 57.7 and Claude Opus's 57.3 |
| GLM-5 | SWE-Bench Verified | 77.8% | Top tier among open-source models |
These numbers show that Chinese open-source LLMs have genuinely reached the world's top tier, but benchmarks and real-world feel have always been two different things. One developer on Zhihu put it this way after hands-on testing: "Setting aside aesthetics and multimodal capabilities, GLM-5.2 can genuinely go toe-to-toe with Claude Opus." The community evaluator NOWBON gave it A-tier ratings on three out of five engineering tasks.
Controversy exists too. In Linux community discussions, some raised concerns about inflated benchmarks, and one third-party early evaluation scored it around 81—about 6% lower than Opus and Sonnet. However, this is a single data point with limited evidentiary weight.
My assessment: GLM-5.2's true capability level can only be determined after the weights are open-sourced and the community conducts large-scale retesting. At this point, any definitive ranking would be irresponsible.
GLM-5.2 Open-Source License & Domestic Chip Compatibility Explained
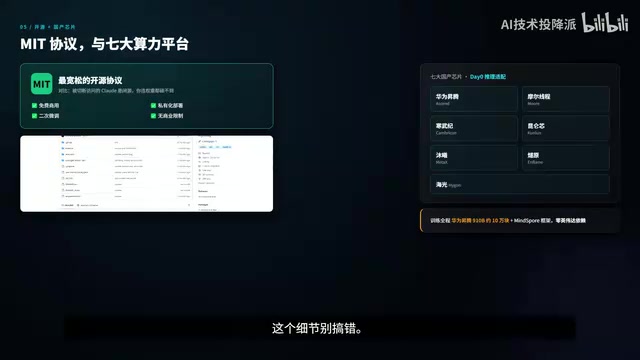
The Weight of the MIT License
GLM-5.2 adopts the MIT license, one of the most permissive open-source licenses available. Specifically, this means:
- ✅ Free for commercial use
- ✅ Private deployment allowed
- ✅ Fine-tuning on top of it allowed
- ✅ No commercial restrictions whatsoever
For comparison: Claude, which just had its access cut off, is closed-source—users can't even touch the weights. One model shuts the door on you and can be revoked at any time; the other hands you the code and weights directly. That's the strategic weight of the MIT license in today's environment.
Full-Stack Training on Huawei Ascend Domestic Chips
The GLM-5 series was trained end-to-end on Huawei Ascend 910B chips—approximately 100,000 of them—paired with Huawei's proprietary MindSpore framework, with zero NVIDIA dependency throughout. Additionally, inference compatibility has been completed for 7 major domestic chips:
- Huawei Ascend
- Moore Threads
- Cambricon
- Kunlun Chip
- Muxi
- Enflame
- Hygon
All were ready to run on launch day (D-0 compatibility).
But a caveat is needed here: The 7-chip compatibility achievement, as reported in public sources, explicitly belongs to GLM-5 and GLM-5.1. As of now, no source has confirmed that GLM-5.2 has completed compatibility with all 7 vendors. The more accurate statement is "the GLM-5 series is compatible with 7 domestic chips," not "GLM-5.2 is compatible with 7 domestic chips."
Furthermore, next week's open-source release is an official promise, but GLM-5.2's standalone weights are not yet visible on Hugging Face or GitHub. Promises and delivery sometimes differ by a few days—the last mile of open-sourcing is when the weights actually drop.
GLM-5.2 Practical Selection Guide: Strengths & Limitations Fully Analyzed

Strengths: Long-Context Scenarios
- Large-scale codebase global refactoring: The 1-million-token context swallows an entire project at once—no more piecemeal patching
- Ultra-long document review: Contracts, research reports processed clause by clause, with patience and no omissions
- Long-horizon agent tasks: Complex workflows like automatically writing complete financial research reports or composing full-length textbooks
Four Clear Limitations
- No native visual multimodal support: Image understanding and video comprehension require the multimodal version
- Hallucination risk with ultra-long context: The longer the context, the higher the accumulated hallucination risk across multi-turn conversations; the Mixture-of-Experts architecture may also experience routing drift on ultra-long task chains
- Higher latency and cost: Thinking Mode requires 30–60 seconds for the first token, making it unsuitable for real-time interaction and customer service scenarios; peak-hour billing at 3x rates means costs aren't cheap
- Aesthetics and documentation stronger than pure coding: Community feedback consistently suggests its documentation capabilities outperform its pure coding abilities, and there may be a gap between benchmark scores and real-world performance
GLM-5.2 Pricing Reference
Within Zhipu's internal positioning, GLM-5.2 is a premium model directly competing with Claude Opus, with quota consumption calculated at the premium tier:
- Max Plan: 469 RMB per month (consistent across multiple sources)
- Lite and Pro Plans: Prices vary across sources (some say 49/140, others say 20/100)—check Zhipu's official website for real-time pricing
- New users: 5-day free trial
- Standalone API: Per-usage pricing not yet announced; referencing the previous generation, approximately $3 per million tokens
One-line selection advice: For complex programming + large context, choose GLM-5.2; if you need image understanding or real-time low latency, look elsewhere.
Strategic Significance Beyond Technical Specs
Don't treat GLM-5.2 as just another model iteration. Against the backdrop of that 48-hour window, it provides a Chinese anchor point for the "openness vs. lockdown" narrative.
When the world's most frontier closed-source models can be revoked at any moment by a single government order, a Chinese open-source LLM with an MIT license, publicly available weights, and deployable by anyone offers something invaluable: certainty. For developers, that certainty matters far more than a few extra points on a benchmark.
Of course, three open questions remain for time to answer:
- What will GLM-5.2's own official benchmark scores actually look like?
- Will the weights be open-sourced next week as promised?
- Can all 7 domestic chip vendors successfully complete compatibility for 5.2?
For developers, the most practical advice is this: once the API goes live, test it yourself—hands-on experience doesn't lie. Frontier intelligence should be open, usable, buildable, and in service of every developer.
Related articles

Anthropic Dynamic Workflows Explained: When to Use Them and Pitfalls to Avoid
Deep dive into Anthropic Dynamic Workflows: core mechanisms, differences from single Agent and Sub-Agent patterns, and a decision tree for when to use them vs. when to avoid burning tokens.

The Era of Managed Agents: Anthropic vs. Google's Two Diverging Approaches
Deep analysis of Anthropic vs Google's Managed Agent architectures, pricing strategies, and selection guidance. Managed Agents are emerging as a new AI infrastructure product category.
Setting Up Claude Code from Scratch: An Installation & Configuration Troubleshooting Guide
A complete guide for beginners to set up Claude Code, covering VS Code installation, plugin troubleshooting, API configuration, model switching pitfalls, and practical usage tips.