GLM5 Architecture Leaked: 745B Parameters, DeepSeek V4 May Launch Quantized Smaller Model First

GLM5 code leak reveals 745B-parameter MoE architecture as Chinese LLM competition intensifies
A GLM5 code leak reveals a 745B-parameter MoE architecture replicating DeepSeek V3's design, likely the viral mystery model Pony Alpha. DeepSeek V4 is rumored to launch a 200B quantized version first, with the flagship potentially exceeding 1T parameters. In the open-source ecosystem, AI Group released XCoder with a synthetic dataset, and ByteDance open-sourced Protonics, a biomolecular prediction model surpassing AlphaFold 3. Chinese LLMs are entering an accelerated phase of parameter-scale competition and multi-domain breakthroughs.
GLM5 Code Leak: 745B Parameters Replicating DeepSeek Architecture
Recently, it has been reported that GLM5 has appeared in the latest PR code for a VLM (Vision Language Model). The code explicitly contains the "GLM5" identifier, and parts of its technical architecture fully replicate DeepSeek V3's design.
Based on available information, GLM5's total parameter count is estimated at approximately 745B, with around 44B active parameters, giving an activation ratio of roughly 1:17—very close to DeepSeek V3's 1:18.5. This means GLM5 also adopts the MoE (Mixture of Experts) architecture—a technical approach that dramatically scales model parameters through sparse activation mechanisms without proportionally increasing computational costs. The core idea is to replace the model's feed-forward network layers with multiple "expert" sub-networks, where a lightweight Router dynamically selects only a few experts to participate in computation during each inference pass. Taking DeepSeek V3 as an example, its total parameters are 671B, but only about 37B parameters are activated per token. This design makes the actual computational cost during training and inference far lower than an equivalently-sized dense model, while retaining the knowledge capacity advantages of large parameter counts. The MoE architecture was first proposed by Jacobs et al. in 1991, and in recent years, with the successful deployment of Google's Switch Transformer, Mixtral, and other models, it has become the mainstream technical choice for ultra-large-scale language models.
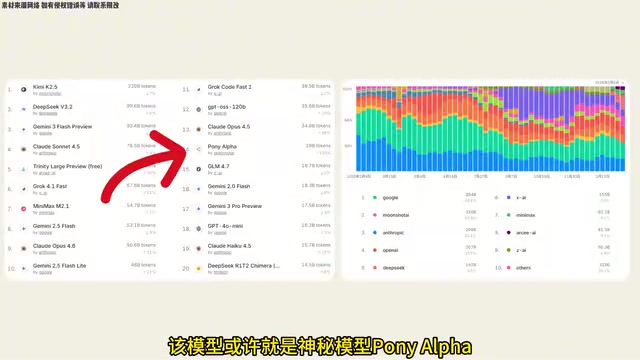
You may not have noticed, but this model is very likely the mysterious model "Pony Alpha" that previously sparked heated discussion. This model suddenly went viral due to its strong capabilities, even driving up the market valuations of some Chinese AI companies, with Zhipu seeing the largest gains. Further clues show that the model's tokenizer is identical to GLM4's, it self-identifies as a "Zhipu new model," and its frontend style is extremely similar to GLM4.
The competition among large models during the Spring Festival period has become increasingly exciting, with Chinese companies accelerating their pursuit and even benchmarking against top international standards.
DeepSeek V4 Roadmap: Quantized Version First, Flagship May Exceed 1T Parameters
Another major piece of news comes from a researcher at Princeton University's AI lab. According to their disclosure, DeepSeek will not directly release a major V4 version this month, but will instead first release a smaller model with approximately 200B parameters.
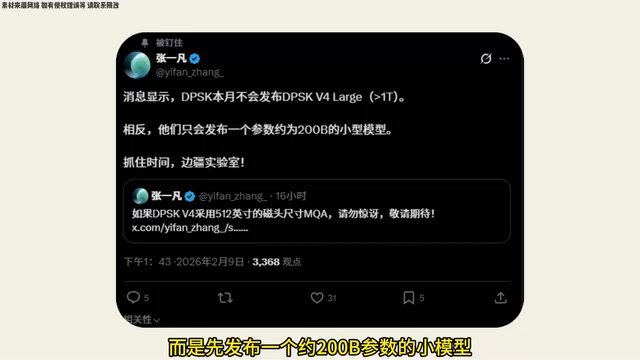
If this information is accurate, it means DeepSeek V4 will include multiple models of different sizes:
- First release: A quantized version with approximately 200B parameters, positioned as a lightweight flagship
- Flagship version: Parameters potentially exceeding 1T (trillion), representing the true full-size model
This strategy aligns with industry trends—releasing a quickly deployable smaller model first to meet market demand, then following up with the complete flagship model. However, it must be emphasized that this information has not been officially confirmed by DeepSeek, and we still need to wait for an official announcement.
The Competitive Landscape of Chinese LLMs from a Parameter Scale Perspective
If DeepSeek V4's flagship version indeed exceeds 1T parameters, combined with GLM5's 745B parameters, Chinese large models are entering an entirely new phase of parameter scale competition. Understanding this race requires returning to the basic framework of Scaling Laws—this theory proposed by OpenAI in 2020 revealed the power-law growth relationship between model performance and parameter count, training data volume, and compute, establishing the industry consensus that "bigger means stronger." However, the 2022 Chinchilla scaling law further refined this understanding: under a fixed compute budget, appropriately reducing model parameters while increasing training data often yields better performance. This also explains why the MoE architecture is so favored—GLM5 with 745B parameters only activates 44B parameters during actual inference, making its real computational cost closer to a medium-scale dense model, while its knowledge storage capacity approaches full-parameter levels. Of course, parameter count is not the only metric for measuring model capability—architecture design, training data quality, and inference efficiency are equally critical.
Gemini 2.0 Preview Available Across All Platforms
Google's Gemini 2.0 preview is now available across all platforms, and users can try it for free.
Since Gemini 2.0's release a few days ago, it has received widespread praise, and this model is seen as Google's second major product since the end of the year. For regular users, this is a great opportunity to experience cutting-edge AI capabilities at zero cost.
Open-Source Ecosystem Continues to Flourish
AI Group Open-Sources XCoder Coding Model
AI Group fine-tuned the Qwen 38B model to create XCoder, a coding model that achieves significant improvements in coding performance. More importantly, the team also simultaneously open-sourced a large-scale fully synthetic dataset suitable for training code models from scratch.

The dataset generation approach is particularly noteworthy:
- Data synthesis performed by O3 Mini
- Solutions generated using DeepSeek R1 and Qwen 3
- The XCoder model itself was trained using this dataset
This paradigm of "using strong models to synthesize data for training new models" is becoming the mainstream methodology in the open-source community. It is essentially an extension of knowledge distillation, academically referred to as "Model-Generated Data" training. This paradigm emerged because acquiring high-quality human-annotated data is extremely expensive, while frontier large models already possess the ability to generate answers approaching human expert levels. The core logic is: strong models serve as "teachers" generating large volumes of annotated training samples, while weaker or specialized models serve as "students" fine-tuning on this data, thereby obtaining strong capabilities at lower cost. XCoder's training paradigm—with O3 Mini synthesizing problems and DeepSeek R1 and Qwen 3 generating solutions—is a typical implementation of this methodology, confirming that the open-source community is forming a reusable high-quality data production pipeline that significantly lowers the barrier to obtaining high-quality training data.
ByteDance Open-Sources Protonics Biomolecular Structure Prediction Model
ByteDance has open-sourced Protonics, a biomolecular structure prediction model that surpasses AlphaFold 3 in core capabilities and significantly leads other models in the field.
To understand the significance of this breakthrough, one needs to appreciate AlphaFold's historical importance. AlphaFold is a protein structure prediction system launched by DeepMind in 2020 that overwhelmingly surpassed traditional computational biology methods in the CASP14 competition, hailed as one of the most important breakthroughs in biology in nearly 50 years. AlphaFold 2, released in 2022, predicted structures for over 200 million proteins and open-sourced them all, greatly accelerating drug development. AlphaFold 3, launched in 2024, further expanded to joint structure prediction of DNA, RNA, and small molecule ligands, covering a broader range of biomolecular types. ByteDance's Protonics claims to surpass AlphaFold 3 in core capabilities, meaning it has achieved new breakthroughs in the accuracy or coverage of all-atom 3D structure prediction.
Protonics provides all-atom 3D structure prediction capabilities, carrying significant implications for drug development and synthetic biology—precise molecular structure prediction can compress candidate drug screening cycles from years to weeks. This also demonstrates that Chinese tech companies' investments in AI for Science are producing world-class results.
Summary and Outlook
From GLM5's architecture leak to DeepSeek V4's rumored roadmap, to the continued flourishing of the open-source ecosystem, Chinese large models are experiencing an unprecedented period of acceleration. Several trends worth watching:
- MoE architecture becomes mainstream: Both GLM5 and DeepSeek are adopting large parameter counts + sparse activation strategies, balancing capability and efficiency
- Multi-size model matrices: Companies are no longer releasing single models, but building complete product lines from lightweight to flagship
- Synthetic data-driven training: The methodology of using strong models to generate training data is maturing
- AI for Science breakthroughs: Vertical domains like biomolecular structure prediction are producing results that surpass international benchmarks
The large model market after the Spring Festival is destined to be anything but quiet—let's wait for the official announcements from each company.
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.