GPT-5.2 Codex vs Opus 4.5 Hands-On: A Comprehensive Comparison of Coding Ability, Speed, and Developer Experience

GPT-5.2 Codex shows coding improvements but Opus 4.5 wins on speed and developer experience.
This hands-on comparison tests GPT-5.2 Codex against Opus 4.5 across frontend generation, physics simulation, 3D rendering, and code refactoring. While Codex shows improvements in visual understanding and frontend quality, Opus 4.5 excels in spatial reasoning, response speed, and IDE integration. For daily development, Opus 4.5 remains the more practical choice, while Codex shines in backend logic and cybersecurity tasks.
Key Findings
OpenAI has officially launched GPT-5.2 Codex, positioned as the most advanced intelligent coding model designed specifically for professional software engineering and cybersecurity. This article puts GPT-5.2 Codex head-to-head against Anthropic's Opus 4.5 through multiple real-world test cases—including frontend generation, physics simulation, 3D scene rendering, and code refactoring—to help developers make more informed decisions.


GPT-5.2 Codex: Official Positioning and Capability Improvements
According to OpenAI's official introduction, GPT-5.2 Codex achieves significant improvements across three core dimensions:
- Long context understanding: Markedly enhanced ability to process large-scale code files
- Tool calling: Smoother collaboration with external tools
- Vision capabilities: Thanks to the GPT-5.2 base model's visual enhancements, it can more accurately interpret screenshots, technical diagrams, UI interfaces, and more
On benchmarks, GPT-5.2 Codex scores slightly higher than GPT-5.2 on SWBench Pro and about 2 percentage points higher on Terminal Bench. SWBench (Software Engineering Bench) is an AI coding evaluation benchmark developed by a Princeton University team that extracts issues and corresponding pull requests from real GitHub open-source projects, requiring AI models to autonomously modify codebases to solve problems after understanding the issue descriptions. SWBench Pro is its advanced version, featuring more complex cross-file modifications and architecture-level refactoring tasks, while Terminal Bench focuses on evaluating a model's ability to operate in terminal environments, including command-line tool usage, script writing, and system debugging. Notably, official scores for the standard SWBench were not published, suggesting they may not have surpassed Opus 4.5's performance.
In cybersecurity, 5.2 Codex far exceeds GPT-5 Codex on professional CTF evaluations. CTF (Capture The Flag) is the most mainstream competition and evaluation format in cybersecurity, where participants must discover vulnerabilities, crack encryption, reverse-engineer, or exploit system weaknesses to obtain hidden "flags" in simulated security environments. Using CTF as an AI model evaluation standard means the model needs advanced capabilities such as vulnerability pattern recognition, attack chain reasoning, and security code auditing. OpenAI also showcased an example of a user discovering a critical vulnerability in Reactor through Codex, marking AI's transition from passive assistance to active discovery in real-world security auditing.
Frontend Generation Testing: Creative Expression and Visual Quality
Ice Terracotta Warrior Breakdancing App
The test employed a clever approach—copying Anthropic's open-source frontend Skills directly as Agent Markdown files to guide Codex away from generating mediocre designs. Agent Markdown files are structured instruction documents that provide system-level behavioral guidance and design specifications for AI coding assistants. Anthropic's open-source frontend Skills are essentially a carefully designed set of prompt engineering templates containing UI design principles, component architecture standards, visual aesthetics criteria, and more. After injecting these Skills, the AI model references these specifications when generating code. This approach reflects an important trend in current AI programming: compensating for models' shortcomings in aesthetics and design standards through external knowledge injection—essentially a domain-specific Context Engineering practice.
The results were impressive: the generated "Ice Terracotta Warrior Breakdancing" app supports clicking to switch between different rhythms, the copy aligns with Chinese culture, and the typography is beautifully designed.
Periodic Table
GPT-5.2 Codex generated a fully functional periodic table page: clicking different elements displays detailed information on the right, with an element discovery timeline and comparison feature below, and non-selected elements automatically fade when a category is chosen. Codex stored the detailed element information in a dedicated JSON file, reaching over 2,000 lines of code. Page quality showed noticeable improvement compared to GPT-5.1.
"Speechless" Barbershop
The "Speechless Barbershop" page generated in Plan mode effectively incorporated the "speechless" keyword from the prompt into the design. Plan mode is an important working mode in AI coding assistants where the model outputs a detailed implementation plan before directly generating code, including architecture design, file structure, component breakdown, technology choices, and implementation steps. This "plan first, execute second" approach draws from the design-first philosophy in software engineering. From a cognitive science perspective, it essentially forces the model into "slow thinking" (System 2 thinking), improving output quality through explicit chains of reasoning. The text stacking and overly small font issues present in earlier 5.2 versions have been significantly improved in the Codex version.
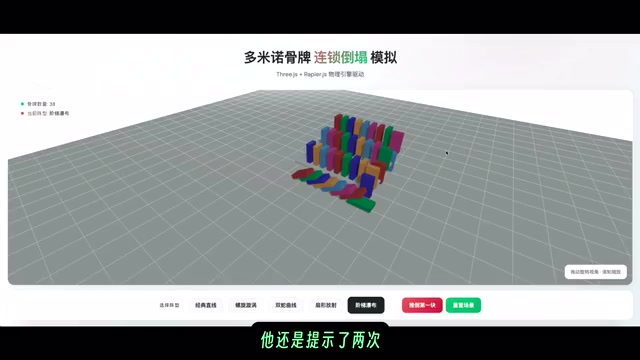
Critical Comparison: Domino Physics Simulation Test
This is a task that severely tests an AI model's spatial understanding—setting up five different domino formations and implementing a chain-reaction toppling effect. Domino chain-reaction physics simulation is an extremely comprehensive test task. The model needs to understand positional relationships and spacing of objects in 3D space, master rigid body collision, gravitational effects, and force transmission physics, and translate this knowledge into precise code parameters. Spatial reasoning has always been a weak point for large language models, as spatial information in text descriptions from pre-training data is far less intuitive than visual data.
GPT-5.2 Codex's Performance
5.2 Codex's generated dominoes failed to achieve continuous toppling. After one prompt revision, the problem still wasn't fully resolved. It took two prompts to reach a basically usable state, indicating room for improvement in spatial reasoning. This confirms that even the most advanced coding models still require multiple iterations for tasks involving precise physics parameter tuning.
Opus 4.5's Performance
Using CC's VS Code plugin with Opus 4.5 (Syncing mode enabled), all five formations were designed in a single prompt. Syncing mode is a real-time collaboration mode provided by Anthropic's Claude Code VS Code plugin that allows AI to continuously monitor code changes in the background while providing suggestions, auto-completions, and error fixes as the developer writes code. Unlike the traditional request-response pattern, Syncing mode creates an experience closer to "pair programming," with AI participating as an always-online collaborator in the development process.
The first formation achieved perfect chain-reaction toppling. While other formations had some issues, the overall effect was superior. The staircase waterfall formation was particularly impressive, demonstrating Opus 4.5's advantage in physics simulation scenarios.
3D Scene Generation: Minecraft-Style Spring Festival Reunion Page
A Minecraft-style New Year gathering scene served as another important test dimension. This type of task requires the model to simultaneously possess 3D spatial modeling capabilities, cultural element understanding, and visual aesthetic judgment—a comprehensive test of AI's overall abilities.
GPT-5.2 Codex: The TV was embedded in the floor (incorrect spatial positioning), window angles were off, lantern light reflections looked decent, but overall 3D spatial awareness was mediocre. These issues reflect the model's ongoing difficulty in converting abstract spatial concepts into precise 3D coordinates and transformation matrices.
Opus 4.5: Block characters were slightly mispositioned, but the TV had vibrant colors and correct placement, the TV cabinet rendered well, and the windows, lanterns, and "Fu" (fortune) characters were all well-placed. The overall atmosphere was stronger with higher 3D scene fidelity.
Code Refactoring Ability and Speed Bottlenecks
In a component splitting task for a file with over 2,000 lines of code, GPT-5.2 Codex took approximately half an hour and still had minor bugs after completion. Component splitting in code refactoring is one of the core practices in frontend engineering, requiring the model to understand inter-component dependencies, state management logic, and props passing chains while maintaining functional integrity and interface consistency during the split. While the modification speed was acceptable, a half-hour wait is clearly too long for daily development.
This is 5.2 Codex's biggest current weakness—extremely slow speed, especially at the highest thinking level. The model's inference speed is constrained by multiple factors: deeper chain-of-thought reasoning requires more computational steps, processing large-scale code contexts consumes significant memory bandwidth, and there may be server-side compute allocation strategies at play. In contrast, Opus 4.5 in High mode responds much faster, and its deep IDE integration significantly reduces context-switching costs—developers don't need to switch back and forth between browser and editor—making it more suitable for development scenarios requiring frequent iteration.
Interaction Experience Comparison
| Dimension | GPT-5.2 Codex | Opus 4.5 |
|---|---|---|
| Language support | Frequently responds in English | Responds in Chinese during Chinese conversations |
| Process feedback | Less textual feedback during intermediate stages | Rich interaction patterns |
| Interface | Codex platform only | VS Code plugin integration |
| Response speed | Extremely slow (High mode) | Relatively fast (Syncing mode) |
| Plan display | Brief | Detailed layout presentation |
Differences in interaction experience affect not only development efficiency but also the developer's flow state. When an AI assistant's response latency exceeds a certain threshold, the developer's attention is easily disrupted, leading to decreased thought continuity. Opus 4.5's deep integration through the VS Code plugin keeps developers in their familiar IDE environment, combined with rich process feedback and detailed plan displays, creating a smoother human-AI collaboration experience.
Selection Guide: Which AI Coding Model Is Right for You?
- Plan mode is key: Regardless of which model you use, Plan mode significantly improves code output quality. By forcing the model to think structurally before coding, it effectively reduces the time cost of rework and debugging.
- Frontend Skills boost: Using Anthropic's open-source frontend Skills as guidance files is recommended to effectively avoid mediocre designs. This Context Engineering methodology applies to other domains as well—developers can customize their own Skill files based on their tech stack and design standards.
- Choose Opus 4.5 for daily development tasks: Fast speed, good interaction experience, excellent Chinese support—ideal for high-frequency iteration
- Choose Codex for backend and complex problems: Has unique advantages in complex backend logic and cybersecurity, particularly in scenarios requiring deep code auditing, vulnerability analysis, and large-scale codebase comprehension
Conclusion
GPT-5.2 Codex demonstrates OpenAI's continued progress in AI coding models, with genuine improvements in frontend generation quality and visual understanding. However, in terms of actual user experience, speed bottlenecks and interaction shortcomings make it difficult to comprehensively surpass Opus 4.5 for now. Which model to choose ultimately depends on your specific use case and tolerance for response latency. For most daily programming tasks, Opus 4.5 remains the more pragmatic choice. The current competitive landscape of AI coding tools is shifting from pure model capability competition to a comprehensive experience competition encompassing response speed, IDE integration, interaction design, and ecosystem—developers need to consider all these dimensions when making their selection.
Related articles
v0 Snowflake Integration Enters Public Preview: Generate Data Dashboards with Natural Language
Vercel's v0 announces public preview of Snowflake integration, enabling users to connect data sources and auto-generate professional dashboards using natural language prompts.
Duel Agents: Multi-AI Agent Competition Mechanism That Automatically Selects the Most Cost-Effective Coding Solution
Duel Agents uses multi-model parallel competition and recursive task decomposition as a routing layer before tools like Claude Code, automatically selecting the most cost-effective AI coding result with claimed 70% savings.
Claude Code Desktop Configuration Guide: Login-Free Setup + Chinese Localization + DeepSeek Integration
Complete guide to configuring Claude Code Desktop: login-free setup via Developer Mode, DeepSeek integration through CC Switch, Chinese localization, and custom Skill loading.