Grill With Docs: Doubling AI Programming Collaboration Efficiency with a Unified Language
Grill With Docs applies DDD's Ubiquitous Language concept to achieve persistent, cross-session AI programming collaboration.
Grill With Docs evolves the viral "Grill Me" AI skill by incorporating Domain-Driven Design principles—specifically Ubiquitous Language, Bounded Contexts, and Architecture Decision Records. By maintaining a shared context.md file as a persistent language contract between developer and AI, it solves cross-session terminology drift, reduces token waste, and dramatically improves AI reasoning quality.
Introduction: A Viral Skill's Self-Revolution
A few months ago, a developer created an LLM skill called "Grill Me" with just four sentences. It made the AI act like an interviewer, continuously asking probing questions until both parties reached a shared understanding of the requirements. The skill went viral—every day, users reported that it "completely changed the game." However, the creator himself wasn't satisfied. He discovered a fundamental flaw in Grill Me and developed a more powerful alternative: Grill With Docs.
This isn't just a skill iteration—it's a paradigm upgrade for AI programming collaboration. Its core idea comes from a classic software engineering methodology: Domain-Driven Design (DDD). And this methodology's impact on AI may be even more significant than its impact on humans.
Domain-Driven Design is a software design methodology proposed by Eric Evans in his 2003 book of the same name. Its core argument is that the essential complexity of complex software lies not in the technical layer, but in the business domain itself. DDD introduces a series of strategic and tactical patterns, including Bounded Context, Aggregate Root, Value Object, and more. In traditional software development, DDD is primarily used to solve communication alignment problems in large teams. In AI collaboration scenarios, this need for language alignment is amplified even further—because LLMs have no persistent memory, every session requires rebuilding context from scratch, turning "ubiquitous language" from a best practice into a near-essential piece of infrastructure.
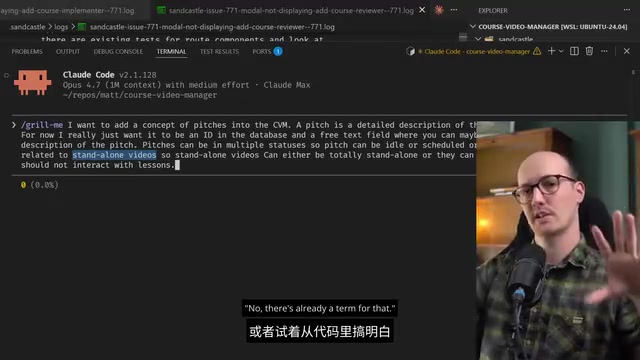
Grill Me's Limitations: The Absence of Cross-Session Language Alignment
The Problem Emerges
Grill Me's working principle is simple: have the LLM continuously probe along every branch of design decisions, resolving dependencies one by one. Many users reported that "at first, the questions felt like they were slowing me down, but over time they actually saved time—once all the context was gathered, everything could be done in one shot."
But with deeper use, several critical problems gradually surfaced:
- AI over-verbosity: Frequently using lengthy descriptions to express concepts that already have well-defined terms
- Inconsistent terminology: Developer jargon (like "standalone video") that the AI doesn't understand, requiring re-explanation every time
- Consensus can't be preserved: Even when great shared expressions are reached in a conversation, these agreements are never recorded
- Context repeatedly lost: Every new session requires re-explaining all the non-obvious aspects of the codebase and domain from scratch
Root Cause
The essential problem is: Grill Me only solves "requirement alignment within a single conversation" but doesn't solve "language alignment across sessions." You and the AI lack a persistent, shared "language contract."
The technical root of this problem lies in how current LLMs work: they perform stateless inference based on context windows. At the start of each conversation, the model doesn't "remember" previous interactions unless that content is explicitly passed in as context. Even as context windows have expanded to 128K tokens or longer, this stateless mechanism still means: cross-session knowledge accumulation must rely on external storage mechanisms. Without external documentation support, every new session is a cognitive reconstruction process starting from zero—this not only wastes tokens but also leads to accumulated understanding drift.
Grill With Docs Design Philosophy: Unified Language + Persistent Documentation
Inspiration from Domain-Driven Design
The solution draws inspiration from a core concept in Eric Evans' Domain-Driven Design (DDD)—Ubiquitous Language.
The essence of ubiquitous language is: the codebase, developers, and domain experts all use the same set of language. When a domain expert says "this part of the application has a problem," the developer knows exactly which part of the code it corresponds to, because the code itself uses the same terminology. This concept is powerful because it eliminates the "translation layer"—in traditional development, what business people say needs to be translated by product managers into requirement documents, then translated by developers into code. Each translation layer introduces information loss and ambiguity. The goal of ubiquitous language is to have all participants directly use the same vocabulary, eliminating this loss at the source.
Applying this concept to human-AI collaboration: if the AI also masters this ubiquitous language, it can express more precise meaning with fewer tokens, without needing to re-describe context every time.
Three Core Components of Grill With Docs
The new skill adds three key layers on top of Grill Me:
1. Context.md — Shared Language Document
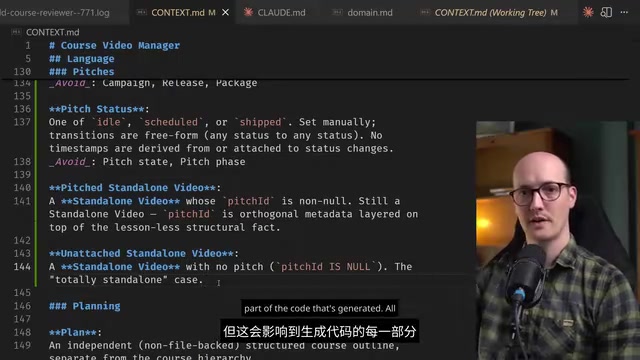
This is a Markdown file placed in the repository that records definitions of all shared terms within that context. For example:
- "Standalone Video" = a video with a null lesson ID (not associated with any course)
- "Pitch" = the packaging of a video (title, description, presentation style), determined before the content itself
For large monorepos, you can use a context map to manage multiple bounded contexts; for a single application, one context file suffices.
In DDD, a Context Map is a tool for describing relationships between multiple bounded contexts. A bounded context defines the boundary within which a model applies—the same word may have completely different meanings in different contexts (for example, "user" in an authentication context refers to the holder of login credentials, while in a billing context it refers to the owner of a paying account). In large monorepos, different modules often correspond to different business domains, and using a unified global glossary would actually cause confusion. Therefore, maintaining independent context.md files for each bounded context, then describing their mapping relationships through a context map, is a more reasonable organizational approach. This layered management ensures terminology precision within each boundary while maintaining the possibility of cross-boundary communication through mapping relationships.
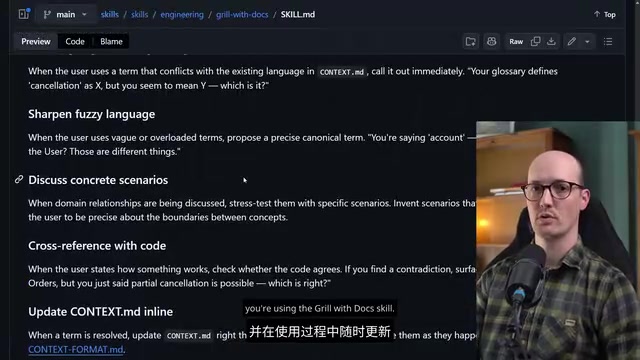
2. Language Cross-Referencing and Clarification Mechanism
During the Grilling process, the AI proactively:
- Cross-references newly appearing terms against the existing glossary
- Clarifies ambiguous wording
- Discusses specific scenarios and cross-references with code
- Updates context.md in real-time
The essence of this mechanism is transforming context.md from a static document into a "living" knowledge base. Each conversation serves as a validation and incremental update of this knowledge base, ensuring it always reflects the project's latest cognitive state.
3. ADR (Architecture Decision Records)
For non-obvious decisions that can't be written into context.md, ADRs are used. ADRs are simple Markdown files specifically for recording decisions that are "hard to reverse" and "would surprise someone without context."
Architecture Decision Records are a lightweight documentation practice proposed by Michael Nygard in 2011. Each ADR typically contains five parts: title, status (proposed/accepted/deprecated), context (background and constraints when the decision was made), the decision itself, and expected consequences. The core value of ADRs lies in recording "why" rather than "what"—code can tell you the system's current state, but it can't tell you why this approach was chosen over another. In AI collaboration, ADR value is further amplified: when AI needs to modify or extend existing code, without understanding the background and constraints of historical decisions, it can easily make modifications that contradict the original design intent, leading to architectural decay.
Key judgment criterion: if it's just an interchangeable choice like "use this library or that one," no ADR is needed; but if the decision will have cascading effects downstream, it must be recorded.
Practical Demo: How Shared Language Improves AI Reasoning Quality
A Typical Grill With Docs Session
Using "add a Pitch entity to the app" as an example, the AI's performance is noticeably different:
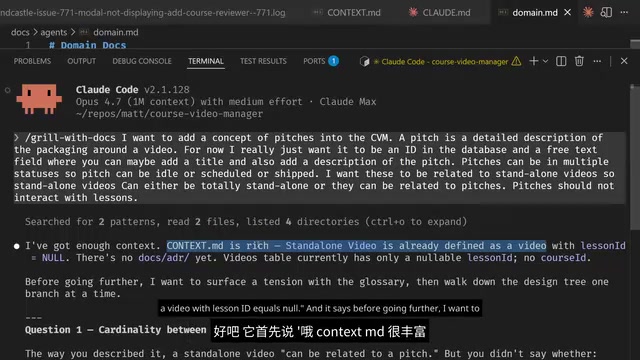
Step 1: Read context.md
The AI first recognizes that "standalone video is already defined as a video with a null lesson ID"—no re-explanation needed.
Step 2: Focus on Language, Not Implementation
The AI proactively raises terminology questions: "What's the cardinality relationship between pitch and standalone video? Does one pitch contain multiple videos, or is it one-to-one?" This is far more efficient than jumping straight into the code layer.
This sequence of "align language first, then discuss implementation" is crucial. In traditional development, premature entry into implementation details is one of the primary sources of requirement drift. When the AI first confirms the precise meaning of terms and relationships between entities, subsequent code generation naturally aligns better with business intent.
Step 3: Discover Semantic Conflicts
The AI keenly notices: if standalone videos can now be associated with pitches, does the definition of "standalone" need to be updated? This seemingly minor question actually impacts UI design, data models, and user cognition.
This is precisely the power of ubiquitous language—when term definitions are sufficiently precise, any conflict between new features and existing definitions is automatically exposed. Without the explicit definition in context.md, the AI might directly ignore this semantic contradiction and generate logically self-contradictory code.
Step 4: Update Shared Documentation
At the end of the session, the AI proactively writes newly reached consensus into context.md, including the pitch entity definition, pitch status state machine, and its relationship with standalone videos.
User Feedback Validation
One early tester's experience is representative: "At first it made me define a lot of terms, and some were hard to agree on. But after four or five sessions, the AI caught the context during grilling and magically aligned with thoughts I hadn't even articulated yet."
This "understands you better over time" experience is essentially the cumulative effect of context.md serving as external memory. As the terminology definitions in the document become richer and more precise, the AI has less room for guessing, and its output naturally becomes more aligned with the developer's intent.
Core Benefits: Three-Fold Improvement of Unified Language for AI Collaboration
1. More Concise Responses
With a shared language, the AI no longer needs to verbosely and repeatedly describe everything. It can simply say "the definition of standalone video needs to change, and we need to adjust how pitches are displayed"—one sentence conveying information that previously required a lengthy explanation.
From a token economics perspective, this means more effective information can be transmitted within the same context window limits. When the AI doesn't need to spend large amounts of tokens describing basic concepts, it has more "cognitive bandwidth" for deep reasoning and creative thinking.
2. More Precise Reasoning
Since LLMs "think" with language (chain of thought), a unified language means the AI's reasoning chain also aligns more closely with your intent, achieving more accurate reasoning with fewer tokens.
There's a deep technical reason for this: Chain of Thought is the core mechanism LLMs use for complex reasoning. Research shows that when a model needs to use vague or verbose expressions to describe a concept, each step in its reasoning chain introduces additional ambiguity and noise, which accumulates and amplifies across multiple reasoning steps. Conversely, when precise terminology is available, the model can complete more accurate reasoning in fewer tokens, with higher certainty at each step and consequently greater reliability in final conclusions. This explains why unified language isn't just a communication efficiency issue—it's a fundamental issue of AI reasoning quality.
3. More Readable Code
When planning documents, conversation style, and code naming all use the same language, code naturally becomes easier to read and search. Want to find everything about pitches? Just search directly.
This consistency also brings a hidden benefit: the cost of code review and knowledge transfer is dramatically reduced. New developers joining the project (or new AI sessions) only need to read context.md to quickly understand the project's core concepts and terminology system, rather than having to reverse-engineer business meaning by reading large amounts of code.
Scenario Selection Guide
| Scenario | Recommended Approach | Reason |
|---|---|---|
| Projects with a codebase | Grill With Docs | Continuously benefits from shared language |
| No codebase / general scenarios | Grill Me | Suitable for one-off tasks like writing or planning |
| Early project stages | Grill With Docs | Early stages are the best time to establish shared language |
| Multi-person collaboration projects | Grill With Docs | Unified language serves both team members and AI |
Conclusion: DDD's New Value in the AI Era
The most interesting finding from this case is: software engineering practices that work for humans work equally well for AI—and often with even more significant results. The ubiquitous language, bounded contexts, and decision records emphasized by Domain-Driven Design have gained entirely new application value in AI collaboration scenarios.
This phenomenon is no coincidence. DDD's core assumption is that "software complexity stems from communication complexity," and AI collaboration is essentially a high-frequency, high-density communication activity. Human teams can gradually build tacit consensus through daily interactions, code reviews, whiteboard discussions, and other channels; but AI has none of these channels—its only information source is explicitly passed-in text. This means all knowledge that can be "understood implicitly" in human teams must be "stated explicitly" in AI collaboration—and DDD happens to provide a mature framework for making tacit knowledge explicit.
When we stop treating AI as a tool that needs repeated education and instead treat it as a collaborator with whom we can co-build a language system, the efficiency of human-AI collaboration takes a qualitative leap. Language alignment isn't a nice-to-have—it's the infrastructure of efficient AI programming.
Key Takeaways
Related articles

Your Pension Forced to Buy AI Bubble Stocks: The Truth Behind Nasdaq's Rule Changes
Nasdaq's fast-track rule changes may force your 401K and pension funds to buy SpaceX, OpenAI, and Anthropic stock. Analysis of the $4T valuation bubble and what investors can do.
GPT 5.6 Internal Testing Codename Revealed, Google Pays SpaceX $920M Monthly for Computing Power
OpenAI begins GPT 5.6 Kindle Alpha internal testing with stronger base reasoning. Google partners with SpaceX at $920M/month for computing power. Gemma 4 QAT enables edge deployment, Claude Cowork doubles credits.
Create Now Review: Can You Really Build Apps with Natural Language and Zero Coding Experience?
In-depth review of Create Now's AI software development tool: intelligent requirements discovery, modular development, visual iteration, and one-click deployment. Can zero-experience users turn ideas into real software?