Harness Engineering: A Practical Guide to AI Development — From Prompts to Mastering AI Agents

AI development evolves from Prompt Engineering to Harness Engineering, systematically constraining AI Agents via a three-layer architecture.
This article introduces three paradigm shifts in AI engineering: from Prompt Engineering to Context Engineering to Harness Engineering. Harness Engineering systematically addresses common AI Agent failures — directional drift, context loss, and error accumulation — through its Information Layer (helping Agents understand projects), Constraint Layer (limiting Agent behavior boundaries), and Automation Layer (self-verification and error correction), achieving a balance between AI productivity and code quality.
From Prompt Engineering to Harness Engineering: Three Paradigm Shifts in AI Development
In today's rapidly evolving landscape of large AI models, engineering methodologies continue to advance. Recently, a concept called Harness Engineering has been gaining widespread attention in the developer community. It represents the third major paradigm shift in AI engineering — from "Prompt Engineering" to "Context Engineering" to "Harness Engineering."
A brief recap of these three stages:
- Prompt Engineering: Guiding model outputs through carefully crafted prompts — the most fundamental form of AI interaction
- Context Engineering: Building on prompt engineering by systematically managing contextual information to provide the model with richer background knowledge
- Harness Engineering: Building a complete system of constraints, validation, and automation that enables AI Agents to work efficiently within controlled boundaries
This evolutionary path reflects the industry's deepening understanding of AI engineering — we need AI not only to "get things done" but also to "get things right" and "avoid mistakes."
Technical Background: The Rise and Limitations of Prompt Engineering
Prompt engineering emerged after the release of GPT-3 in 2020. Researchers discovered that the same model could perform dramatically differently under different prompts, giving rise to a discipline dedicated to studying how to "communicate with AI." Early classic techniques included Few-shot Learning, Chain-of-Thought (CoT) prompting, and role-play setups. However, as task complexity increased, the limitations of relying solely on prompts became increasingly apparent — it is essentially a "one-shot" input optimization that lacks systematic management of the entire interaction process. This is precisely why Context Engineering and Harness Engineering emerged.
Technical Background: Core Mechanisms of Context Engineering
Context Engineering is a systematic upgrade from prompt engineering. The core working mechanism of large language models is prediction based on the context window — GPT-4 supports 128K tokens, and the Claude 3 series reaches up to 200K tokens. The core task of context engineering is to maximize information density and relevance within the limited context window. Specific techniques include: RAG (Retrieval-Augmented Generation) for dynamically injecting relevant documents, Memory Compression for retaining key historical information, and structured System Prompt design. This stage marks the transition of AI applications from "single conversations" to "sustained task execution."
The Core Philosophy of Harness Engineering
Why Do We Need Harness Engineering?
A common pain point when using AI Agents for development today is that Agents tend to "go off track" during code generation. They might generate content you don't need at all, or deviate significantly from the intended direction. This isn't a problem of insufficient model capability — it's a lack of systematic engineering constraints.
Harness Engineering was created to solve exactly this problem. Its core idea is: by building a complete "harnessing" system, AI Agents work within clearly defined boundaries while possessing self-verification and error-correction capabilities.
Common Agent Failure Modes
Before diving into the specific practices of Harness Engineering, it's essential to understand why Agents fail.
Technical Background: AI Agent Architecture and the Compounding Error Problem
An AI Agent is an AI system capable of autonomously planning, executing multi-step tasks, and interacting with external environments. Its technical architecture typically includes four core components: a perception module (receiving input), a planning module (LLM-based task decomposition), a memory module (short-term working memory and long-term knowledge storage), and an action module (calling tools, executing code, accessing APIs, etc.). The ReAct (Reasoning + Acting) framework, proposed by Google in 2022, is currently the most mainstream Agent implementation paradigm. The "directional drift" problem in Agents stems technically from the autoregressive generation nature of LLMs — each output step depends on previous outputs, and errors accumulate exponentially with the number of steps. This is known in academia as the "Compounding Error Problem" and is the core challenge that Harness Engineering's three-layer architecture aims to solve.
Common failure modes include:
- Directional Drift: The Agent gradually deviates from expected goals during task execution
- Context Loss: The Agent forgets key constraints during long conversations or complex tasks
- Over-generation: Producing large amounts of unnecessary code or content, increasing maintenance costs
- Error Accumulation: Small errors in earlier steps get amplified in subsequent steps
These failure modes are extremely common in real projects and are the fundamental reason many developers have a love-hate relationship with AI coding tools.
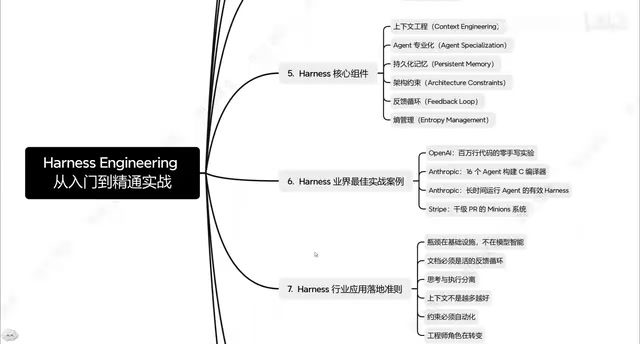
The Three-Layer Architecture of Harness Engineering
Based on systematic analysis, implementing Harness Engineering can be divided into three key layers. This three-layer architecture is its most practically valuable framework design.
Information Layer: Helping the Agent "Understand" the Project
The first layer is the Information Layer, with the core goal of giving the Agent a comprehensive understanding of the project. This isn't just about dumping code to the AI — it's about systematically providing project architecture, tech stack, business logic, coding standards, and other critical information.
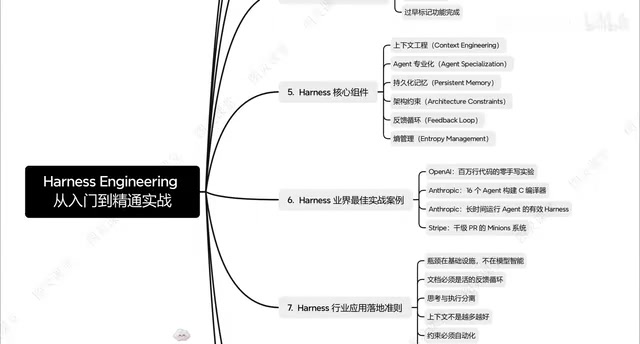
The quality of the Information Layer directly determines the efficiency and accuracy of subsequent development. A good Information Layer should include:
- Overall project architecture documentation
- Technology selection rationale and constraints
- Structure and dependency relationships of existing code
- Core concept definitions in the business domain
Constraint Layer: Preventing the Agent from "Making Mistakes"
The second layer is the Constraint Layer — the key differentiator between Harness Engineering and traditional AI coding approaches. The Constraint Layer limits the Agent's behavioral scope through explicit rules and boundaries, preventing it from "going off track" during generation.
Technical Background: The Constraint Layer's Roots in Defensive Programming
The Constraint Layer philosophy of Harness Engineering is highly aligned with "Defensive Programming" in traditional software engineering. The core idea of defensive programming is to assume that any input could be erroneous and to pre-handle various exceptions in the code. In the AI Agent context, the Constraint Layer plays a role similar to Type Systems and Design by Contract — the former prevents illegal operations at compile time, while the latter regulates function behavior through preconditions, postconditions, and invariants. Rule files like
.cursorrulesandCLAUDE.mdessentially encode these constraints in natural language, allowing the AI to "internalize" boundary conditions before execution rather than correcting errors after the fact, fundamentally reducing the probability of compounding errors.
Designing the Constraint Layer requires answering several core questions:
- Which files can the Agent modify, and which are off-limits?
- What are the mandatory requirements for code style and architectural patterns?
- Which operations require human confirmation before execution?
- How should the Agent handle uncertainty?
The essence of this layer is finding the optimal balance between AI freedom and controllability. Too loose, and the Agent easily goes out of control; too tight, and you limit AI's creativity and efficiency.
Automation Layer: Enabling Agent "Self-Verification"
The third layer is the Automation Layer, responsible for automatically verifying code quality after development, discovering issues, and making corrections. This layer combines traditional software engineering CI/CD concepts with AI Agent capabilities to form a complete quality feedback loop.
Technical Background: Deep Integration of CI/CD and AI Automated Verification
Traditional CI/CD pipelines (such as GitHub Actions, Jenkins, GitLab CI) automate code building, testing, and deployment. In the Harness Engineering framework, AI Agents are embedded into this pipeline, taking on more intelligent roles: not only executing predefined test scripts but also analyzing root causes of test failures, generating fix suggestions, and even automatically submitting fix PRs. This aligns with the philosophy of "AIOps" (AI for IT Operations). It's worth noting that Harness itself is also a well-known DevOps platform company whose products focus on software delivery automation — this naming coincidence reflects the deep conceptual connection between Harness Engineering and engineering delivery systems.
The Automation Layer typically includes:
- Automated test execution and result analysis
- Code quality checks and standards validation
- Error detection and automated fix suggestions
- Regression testing and impact scope assessment
Industry Best Practices: From OpenAI to Anthropic
Notably, the philosophy of Harness Engineering is not merely theoretical. Leading AI companies like OpenAI and Anthropic have already widely applied similar engineering methods in their internal practices.
Technical Background: Engineering Practice Details from Leading AI Companies
Anthropic's "Constitutional AI" (CAI) methodology requires models to follow a clear set of principles when generating content, which is highly consistent with the Constraint Layer design philosophy. OpenAI extensively uses Sandbox Isolation and the principle of least privilege in their internal practices with Codex and GPT-4 Code Interpreter, ensuring code execution doesn't produce unexpected side effects. Additionally, Anthropic's published "Model Spec" document specifies detailed behavioral guidelines for Claude when facing uncertainty — this directly echoes the Constraint Layer design of "how the Agent should handle uncertainty" in Harness Engineering. Both emphasize that explicit rules are superior to implicit expectations, prioritizing controllability as the first principle of system design.
The core ideas from these best practices can be distilled into several key principles:
- Progressive Trust: Start with small tasks and gradually expand the Agent's permission scope
- Explicit Constraints Over Implicit Expectations: All rules should be clearly written out rather than relying on the Agent's "common sense"
- Verification-Driven Development: Every operation should have a corresponding verification mechanism
- Human-AI Collaboration, Not Replacement: The Agent is a tool that enhances developer capabilities, not a replacement
AI Coding Tool Selection Strategy
At different stages of Harness Engineering, appropriate AI coding tools need to be selected. Current mainstream tools each have their own focus:
- Information Layer Construction: Tools that can deeply understand codebases are ideal, such as IDE-integrated solutions like Cursor and Windsurf
- Constraint Layer Design: Tools that support rule files (such as
.cursorrules,CLAUDE.md, etc.) are needed - Automated Verification: Traditional CI/CD tools can be combined with AI Agent auto-fix capabilities
The key isn't choosing the "best" tool — it's using the right tool at the right stage.
Key Checklist for Practical Implementation
To truly implement Harness Engineering in your projects, focus on these core items:
- Project Documentation Preparation: Complete architecture docs, technical specifications, business descriptions
- Constraint Rule Definition: Clear coding standards, file permissions, operational boundaries
- Verification Mechanism Setup: Automated testing, code review, quality gates
- Iterative Optimization Process: Continuously adjust constraints and the Information Layer based on actual results
- Team Collaboration Standards: Unified Harness configuration management and version control
Summary and Outlook
Harness Engineering represents an important direction in AI engineering practice. Its core value lies not in any specific tool or technology, but in providing a systematic methodology that helps developers maintain control over code quality and project direction while enjoying AI productivity gains.
As AI model capabilities continue to improve, the importance of Harness Engineering will only grow. Because the more powerful the model, the more critical the engineering ability to "harness" it becomes — like a faster horse that needs better reins and a more skilled rider. From Prompt Engineering to Context Engineering to Harness Engineering, behind each paradigm shift is the developer community's collective deepening of understanding on the core question of "how to collaborate with AI."
For developers who want to stay competitive in the AI era, mastering Harness Engineering is not just a technical skill — it's an upgrade in engineering thinking.
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.