Hermes Self-Evolution Framework: An Open-Source Solution for Automated AI Agent Prompt Optimization
Hermes Self-Evolution Framework: An Op…
Hermes Agent automates AI prompt evolution using DSPy and GEPA genetic algorithms.
Hermes Agent is an open-source AI agent framework by NousResearch whose core innovation is a built-in learning loop that automatically extracts skills from execution experience and continuously optimizes them. It combines Stanford's DSPy declarative programming framework with the GEPA Genetic Pareto Evolution algorithm, achieving targeted prompt mutations through deep execution trace analysis while balancing multiple objectives via the Pareto frontier. The system features five layers of safety protection to keep evolution controllable, requires no GPU, and costs only $2–10 per optimization run.
What Is Hermes Agent?
An AI Agent that can modify its own prompts and automatically optimize its own skills — it sounds like science fiction, but NousResearch's open-source Hermes Agent has turned it into reality. The project has earned over 100,000 stars on GitHub, is fully open-sourced under the MIT license, and stands as one of the most complete Agent self-evolution solutions in the open-source community.
The core difference between Hermes Agent and ordinary Agents is that it has a built-in learning loop. After each task execution, the system automatically extracts lessons from both successes and failures, generating skill files. The next time it encounters a similar task, it draws on existing experience rather than starting from scratch.
To put it simply, an ordinary Agent is like an intern following a manual, while Hermes is like a seasoned professional who takes their own notes, reviews mistakes, and continuously updates their working methods. It supports a Model-Agnostic Architecture — an important trend in recent Agent framework design that decouples business logic from underlying models through a unified abstraction layer. The LLM market is fiercely competitive, with the capability gap between GPT-4, Claude 3.5, Gemini, and others narrowing rapidly, making vendor lock-in extremely risky. Different tasks also have vastly different model requirements — code generation might favor DeepSeek-Coder, while multilingual tasks might favor Qwen. Hermes achieves this through unified interface layers like LiteLLM, allowing it to connect to any API including GPT, Claude, LLaMA, and more. It supports self-hosted deployment to prevent data leakage and allows routing simpler subtasks to cheaper, smaller models for cost control. The current version is 0.14, and it's still iterating rapidly.
The Two Core Technologies Behind Self-Evolution
The Hermes Agent Self Evolution repository accomplishes something critical: making Agent skills evolve automatically rather than relying on manual authoring. Behind this is an elegant combination of two technologies.
DSPy: Turning Prompts into Programmable Objects
DSPy is a declarative programming framework developed by Stanford. Its full name is Declarative Self-improving Language Programs, released in 2023 by Stanford's NLP lab. The core idea is to treat prompts as programmable objects rather than manually tuned text strings.
The fundamental pain point of traditional prompt engineering is that prompts are fragile natural language strings — they can completely break when you switch model versions or task scenarios, and the optimization process is heavily dependent on human intuition. DSPy introduces abstraction layers called "Signatures" and "Modules" that transform prompt engineering into an optimizable problem. Developers only need to define inputs, outputs, and metrics, and DSPy's built-in optimizers (such as BootstrapFewShot and MIPROv2) automatically search for the optimal combination of few-shot examples and instruction wording. The entire process is analogous to backpropagation in neural networks, except the optimization targets are prompts rather than weights. This fundamentally changes the prompt engineering paradigm: from "humans tweaking by feel" to "systems searching automatically."
GEPA: Genetic Pareto Prompt Evolution Algorithm
GEPA (Genetic Pareto Prompt Evolution) is a method proposed in an ICLR 2026 Oral paper, and it differs fundamentally from traditional prompt optimization.
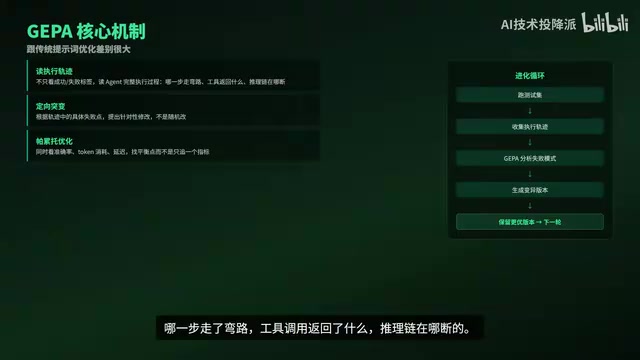
Genetic Algorithms are heuristic search methods that simulate biological evolution, comprising three core operators: selection, crossover, and mutation. Applying genetic algorithms to prompt optimization wasn't pioneered by GEPA — earlier work like EvoPrompt (2023) had already validated this direction. However, earlier methods used relatively random mutation strategies, akin to performing "blind text replacements" on prompts. GEPA's key innovation lies in deeply binding mutation operations to Agent Execution Traces.
Execution traces are structured logs in Agent systems that record the complete reasoning and action process, typically including: chain-of-thought reasoning steps, tool call requests and return results, intermediate state variables, and final outputs. Since the popularization of the ReAct (Reasoning + Acting) framework, execution traces have become the core diagnostic tool for understanding Agent behavior. Traditional prompt optimization only looks at whether the final output is right or wrong — equivalent to only checking exam scores without reviewing the answer process. GEPA's deep trace analysis is more like "grading each question individually" — it can precisely pinpoint at which step the Agent started going off track, which tool call returned misleading information, and where the reasoning chain exhibited logical leaps.
GEPA's uniqueness is reflected in three aspects:
- Deep Execution Trace Reading: Rather than just looking at success/failure labels, it analyzes the Agent's complete execution process — which step took a detour, what tool calls returned, and where the reasoning chain broke down.
- Targeted Modifications: It proposes modification suggestions based on specific failure points in the traces rather than random mutations, giving each generation of mutations a clear improvement intent and dramatically improving search efficiency.
- Multi-Objective Balanced Optimization: It introduces the concept of Pareto Optimality — a concept originating from economist Vilfredo Pareto, describing a state where "no single objective can be further improved without degrading another." In AI systems, improving accuracy typically means more token consumption, while compressing tokens may sacrifice reasoning quality. GEPA maintains a set of candidate prompts that each excel under different objective trade-offs (the Pareto frontier), simultaneously considering accuracy, token consumption, latency, and other metrics. This allows developers to flexibly choose based on actual deployment constraints rather than being forced to accept a single "optimal solution."
The Complete Self-Evolution Workflow
The entire evolution process is a continuous loop: existing skills → run test suite → collect execution traces → GEPA analyzes failure patterns → generate mutated versions → benchmark comparison → retain superior versions → enter next round.
Two Practical Steps
Step 1: Prepare evaluation data. There are two sources to choose from:
- Synthetic: Test cases automatically generated by an LLM, suitable for quickly getting started and validating the workflow
- Session: Real task-result pairs extracted from actual Hermes runtime logs, higher quality
It's recommended to first run through the workflow with Synthetic data, then switch to Session data for fine-grained optimization.
Step 2: Run the evolution command. Execute python -m evolution_skills evolve_skill, specifying the skill name, number of iteration rounds, and evaluation data source. Each iteration automatically completes the full pipeline of benchmarking, analysis, mutation, comparison, and retention.
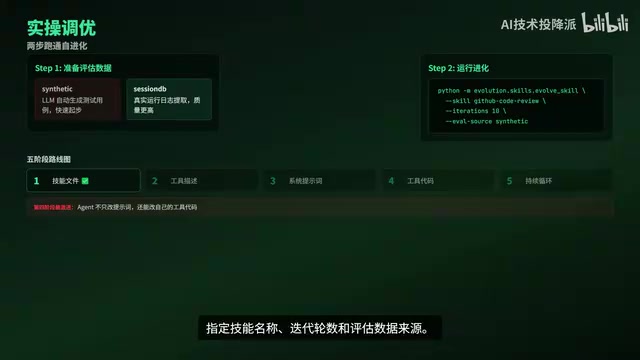
Five Progressive Development Stages
The repository outlines a clear evolution roadmap:
| Stage | Optimization Target | Status |
|---|---|---|
| Stage 1 | Skill files | ✅ Completed |
| Stage 2 | Tool descriptions | In development |
| Stage 3 | System prompts | In development |
| Stage 4 | Tool code | In development |
| Stage 5 | Continuous automated loop | In development |
Stage 4 is the most ambitious — the Agent doesn't just modify its own prompts but can also rewrite its own tool code, representing true self-evolution in every sense.
Five-Layer Safety Protection Mechanism
The biggest risk of automated evolution is "iterating yourself into a broken state." Hermes addresses this with a five-layer protection mechanism:
- Full test suite pass required before retaining any mutated result
- Prompt size limits to prevent unbounded growth
- Cache mechanism protection to prevent breaking existing cache logic
- Core intent locking to prevent changing a skill's fundamental objective
- Human review gates — evolution results are submitted as PRs and only merged after manual review

This mechanism ensures the self-evolution process maintains both autonomy and controllability. Notably, the "core intent locking" layer philosophically corresponds to the "goal stability" problem in AI alignment — preventing Goal Drift during the optimization process, where the system distorts the original task intent in order to score higher on evaluation metrics.
Cost and Practicality Analysis
In terms of cost, Hermes' self-evolution approach is quite accessible:
- No GPU required — all evolution operations are completed through API calls
- Each optimization run costs approximately $2–10, depending on the number of iterations and evaluation scale
- Cost optimization strategy: Use smaller models to run the evolution process itself, use the target model for evaluation — keeping overall costs manageable
This cost structure is viable precisely because of the model-agnostic architecture's flexible routing capability. The evolution iteration itself is computationally intensive but has relatively low model capability requirements, so it can be handled by cheaper models. Final evaluation uses the target deployment model to ensure the optimization results are genuinely effective.
The Essence: An Engineering Implementation of Darwinian Evolution
Hermes' self-evolution is essentially an engineering implementation of Darwinian evolution:
- Mutation: GEPA reads execution traces and proposes targeted modifications
- Selection: Test suite benchmarks eliminate inferior solutions
- Heredity: Successful mutations become the foundation for the next generation
Each skill evolves independently without interfering with others. Compared to traditional prompt engineering — where a person sits there repeatedly modifying, checking results, and modifying again, often guided by intuition and experience — Hermes fully automates this process. Moreover, modifications are based not on gut feeling but on real execution trace data.
The profound significance of this paradigm shift is that it transforms prompt engineering from a "craft" dependent on individual experience into a repeatable, measurable, and automatable engineering process. As Stage 4 (tool code self-evolution) and Stage 5 (continuous automated loop) are implemented, Agent systems may be able to continuously expand their own capability boundaries without human intervention.
For teams currently working on Agent development, Hermes provides a clear path from "manual tuning" to "automated evolution." Although it's still in its early stages (v0.14), its architectural design and safety mechanisms are already quite mature and well worth following and experimenting with.
Key Takeaways
- Hermes Agent is an open-source AI agent framework by NousResearch with a built-in learning loop that automatically extracts skills from execution experience and continuously optimizes them
- The core technology combines Stanford's DSPy declarative programming framework with the GEPA (Genetic Pareto Prompt Evolution) algorithm from an ICLR 2026 Oral paper
- GEPA achieves targeted prompt mutation optimization by deeply analyzing complete Agent execution traces rather than simple success/failure labels, balancing accuracy, token consumption, latency, and other objectives via the Pareto frontier
- The system features a five-layer safety protection mechanism including test suite validation, size limits, cache protection, intent locking, and human review to ensure the evolution process remains controllable
- The overall solution requires no GPU, costs approximately $2–10 per optimization run, and its model-agnostic architecture supports flexible cost routing strategies — making it one of the most complete Agent self-evolution solutions in the open-source community
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesDemystifying Transformer: A Word-Continuation Function, Deconstructed
Understand Transformer through the lens of word continuation. Breaking down language generation into Embedding, Transformer Block, and Probability output modules for intuitive understanding.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.