LangGraph + MCP: A Practical Guide to Building Enterprise-Grade ChatBI Data Analysis Agents
Technical breakdown of building a ChatBI data analysis agent using LangGraph + multi-MCP architecture.
This article systematically introduces the architecture design and technical evolution of ChatBI (natural language interactive business intelligence). Addressing the limitations of fixed dashboards and the efficiency bottlenecks of three-tier collaboration in traditional data analysis, it proposes building a data analysis Agent using LangGraph + multi-MCP architecture to achieve end-to-end automation from natural language to analytical results. The architecture evolves from centralized MCP to a LangGraph decentralized approach, solving stability and scalability issues, while emphasizing the importance of defining capability boundaries and designing human-AI collaboration fallback mechanisms.
What is ChatBI? Why Do Enterprises Need It?
ChatBI — a business intelligence analysis system based on natural language interaction — is one of the most promising applications of LLM-powered agents in enterprise data analytics. Users simply describe their needs in natural language — for example, "Show me the sales trend of towels during last year's Double Eleven" — and the system automatically handles data querying, analytical computation, and even machine learning modeling, ultimately returning results in the form of charts, reports, or a concise summary.
This article is based on a technical sharing session by a UCLA Mathematics master's graduate with eight years of AI industry experience. It systematically covers how to build a ChatBI data analysis Agent from scratch using LangGraph + a multi-MCP architecture, including architectural design philosophy, technology selection comparisons, and the evolution from centralized to decentralized approaches.

Pain Points of Traditional Data Analysis Workflows
Limitations of Fixed Dashboards
Dashboards commonly used in enterprises are visually appealing and intuitive, but they suffer from several fundamental problems:
- Static content: The metrics and dimensions displayed are predefined. Every time a new data column needs to be added, it requires scheduling work with data analysts and product managers.
- Poor interactivity: They cannot dynamically adapt to personalized needs. Even simple ad-hoc requests like "hide the order ID column" or "calculate the average completion time" cannot be fulfilled.
- Unsuitable for low-frequency needs: Many analysis requirements are one-off (e.g., comparing this year's and last year's Double Eleven sales). Investing multi-person collaborative development for such needs is extremely wasteful.
Efficiency Bottlenecks of the Three-Tier Collaboration Structure
Traditional enterprise data analysis typically follows a three-tier structure: Requester → Data Analyst → Machine Learning Engineer.
After the requester (operations staff, executives, etc.) raises a need, the data analyst extracts data from databases and performs basic statistics. If complex predictive requirements are involved, the work is further handed off to machine learning engineers for modeling.
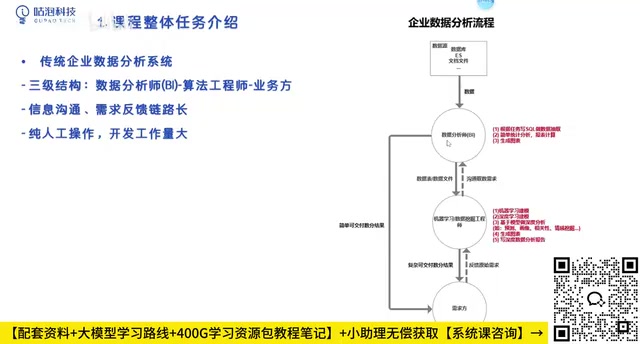
The core problems with this workflow are:
- Requesters often can't articulate their needs completely the first time, and repeated revisions cause the entire pipeline to be re-executed multiple times.
- The same analysis passes through multiple hands, resulting in extremely high communication and time costs.
- Low-frequency ad-hoc needs get mixed with high-frequency fixed requirements, leading to irrational resource allocation.
ChatBI System Architecture Design
End-to-End Flow: From Natural Language to Analysis Results
The core design philosophy of a ChatBI system is: users only need to express their needs in natural language, and the system autonomously completes the entire data analysis pipeline. The workflow can be summarized into the following key stages:
- Semantic understanding and business routing: The system first performs intent recognition on user input — is it casual conversation, chart generation, or data analysis? Different intents are routed to different agents for processing.
- NL2SQL data retrieval: For data analysis needs, the system automatically converts natural language into SQL query statements to extract required data from databases. NL2SQL (Natural Language to SQL) is one of ChatBI's core capabilities. Early approaches relied on rule matching and template filling with limited accuracy; the LLM era has brought a qualitative leap in accuracy, but challenges remain with multi-table joins, ambiguous business terminology, etc. In engineering practice, techniques like Schema injection (feeding database table structures to the model), few-shot examples, and execution result validation are typically combined to improve reliability.
- Intelligent decision-making: After obtaining data, the system autonomously determines whether to directly generate statistical results or proceed with machine learning modeling (e.g., sales forecasting).
- NL2Pattern modeling: For predictive requirements, the system automatically builds time series and other models based on historical data to generate forecasts.
- Intelligent summary output: Results are finally returned to the user in the form of charts, reports, or concise answers.
The elegance of this architecture lies in its high extensibility — the semantic understanding module itself acts as a router. You can integrate a RAG module for domain knowledge Q&A at any time, or connect other functional agents, without being limited to data analysis alone.
RAG Technical Note: RAG (Retrieval-Augmented Generation) is a technical architecture that combines external knowledge bases with large language models. Its core approach is: before the model generates an answer, it first retrieves context snippets relevant to the question from a vector database or document store, then feeds these snippets along with the question into the model. This enables the model to answer specialized questions beyond its training data. In ChatBI scenarios, a RAG module can handle enterprise-internal business terminology explanations, metric definition queries, and other knowledge Q&A needs, complementing data analysis capabilities to form a complete enterprise knowledge service loop.
Capability Boundaries: ChatBI Is Not Omnipotent
You might not have noticed, but the presenter specifically emphasized the capability boundary issue of ChatBI. Currently, truly effective ChatBI products are rare on the market, indicating that such products indeed face significant challenges. The correct approach is:
- Clearly define which scenarios are suitable for ChatBI (e.g., standardized statistical queries, trend analysis)
- Identify which scenarios are difficult to handle (e.g., extremely complex multi-table join analyses)
- For difficult scenarios, route to human analysts to achieve human-AI collaboration
Evolution from Centralized MCP to LangGraph Decentralized Architecture
Phase One: Centralized Multi-MCP Architecture
The course first introduces a simple implementation approach: using a large language model as the central dispatcher, implementing a data analysis agent through multiple MCPs (Model Context Protocol).
MCP Protocol Background: MCP is an open standard protocol proposed by Anthropic in late 2024, designed to unify the interaction between large language models and external tools and data sources. Previously, every AI application needed custom integration code for different tools, resulting in extremely high maintenance costs. Through a standardized client-server architecture, MCP enables models to invoke databases, file systems, APIs, and other external resources in a unified manner — similar to how the USB interface unified the hardware ecosystem — dramatically lowering the barrier to tool integration.
The advantages of this approach are simple setup and minimal code, but it has obvious drawbacks:
- Instability: When the number of tools increases, the LLM as a single dispatch center easily becomes overwhelmed.
- Poor scalability: All decisions depend on a single central node, making it difficult to flexibly extend new capabilities.
- Chaotic tool invocation: With too many tools, the model may select the wrong tool or invoke them in the wrong order.
Phase Two: LangGraph Decentralized Architecture
To address the problems of centralized architecture, the course introduces LangGraph — an enterprise-grade agent orchestration framework.
LangGraph Technical Background: LangGraph is an agent orchestration framework developed by the LangChain team, based on a directed graph (DAG and cyclic graph) computation model, specifically designed for building complex multi-agent workflows. Unlike traditional chain-based invocations, LangGraph allows cycles and conditional branches within workflows, which is crucial for AI Agents that need iterative refinement and self-correction. Its core abstractions include Nodes, Edges, and State — state flows between nodes and is persisted, giving the entire system memory capabilities and checkpoint-resume characteristics, making it highly suitable for enterprise-grade complex data analysis scenarios.
The core advantages of LangGraph include:
- Graph-based orchestration: Defines agent workflows as directed graphs, where each node is an independent agent or processing unit.
- Decentralized scheduling: No longer relies on a single LLM for all decisions; instead, each node handles its own responsibilities.
- Unlimited extensibility: New nodes and edges can be added to the graph at any time, incorporating new capabilities without affecting existing workflows.
- Improved stability: Each node only needs to focus on its own task, reducing the risk of single points of failure.
Serial and Parallel MCP Invocation Strategies
At the MCP usage level, the course explains two invocation patterns in detail:
- Serial invocation: Tools execute sequentially one after another, suitable for task chains with dependencies.
- Parallel invocation: Multiple tools execute simultaneously, suitable for independent data retrieval tasks, significantly improving efficiency.
Combining these two patterns with LangGraph allows flexible application across different nodes in the graph, achieving both efficient and stable agent scheduling.
ChatBI Core Technology Stack Overview
The entire ChatBI system's technology stack can be summarized into the following core modules:
| Module | Technology | Purpose |
|---|---|---|
| Agent Orchestration | LangGraph | Defines workflow graph structure, manages state transitions between nodes |
| Tool Invocation | MCP / Function Calling | Connects external tools like database queries and chart generation |
| Data Querying | NL2SQL | Converts natural language into SQL statements |
| Data Modeling | NL2Pattern | Automatically builds machine learning prediction models |
| Semantic Understanding | LLM | Intent recognition and business routing |
Conclusion: How ChatBI Reshapes Enterprise Data Analysis
ChatBI represents a paradigm shift in enterprise data analysis from "people searching for data" to "data finding people." Through the LangGraph + multi-MCP architecture combination, we can build a data analysis agent that is both stable and flexible:
- For regular users: Simply describe needs in natural language without mastering SQL or data analysis skills.
- For data analysts: Delegate repetitive data extraction and tabulation work to the system, focusing on more valuable insights.
- For enterprises: Dramatically reduce the labor costs of low-frequency ad-hoc needs and improve the efficiency of data-driven decision-making.
Of course, ChatBI is not omnipotent. In actual deployment, clearly defining its capability boundaries and designing proper human-AI collaboration fallback mechanisms are the keys to making such systems truly deliver value. As LLM capabilities continue to improve and the tool ecosystem matures, ChatBI is poised to become standard infrastructure for enterprise data analysis.
Key Takeaways
- ChatBI replaces the traditional three-tier data analysis workflow through natural language interaction, dramatically reducing communication costs and labor waste.
- The centralized multi-MCP architecture is simple to implement but suffers from instability and poor scalability; LangGraph's decentralized architecture effectively addresses these issues.
- The system's core pipeline is: Semantic Understanding → Business Routing → NL2SQL Data Retrieval → Intelligent Decision-Making → NL2Pattern Modeling → Intelligent Summary Output.
- Combining MCP's serial and parallel invocation patterns with LangGraph's graph structure enables flexible and efficient agent scheduling.
- Clearly defining ChatBI's capability boundaries and designing human-AI collaboration fallback mechanisms are critical for successful deployment.
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.