LLM Observability & Eval in Practice: A Complete Guide to Monitoring and Evaluating Large Models in Production
A complete guide to monitoring, evaluating, and iteratively improving LLM applications in production.
This article covers the three pillars of production-grade LLM applications: observability via OpenTelemetry traces and sessions, a comprehensive evaluation system with five signal types and four scope levels, and a dataset-driven experimentation workflow for continuous improvement. It emphasizes automating the entire observe-evaluate-experiment flywheel to keep AI Agents reliable at scale.
Your AI Agent is finally live — now what? How do you know what it's actually doing in production? How do you pinpoint issues when things go wrong? And how do you make sure fixing one bug doesn't create three new ones?
At the AI Engineer conference, Dat, an AI architect at Arise AI, shared his deep practical experience with enterprise-grade LLM observability, evaluation (Eval), and iterative experimentation. As a heavy practitioner whose work consumed between 100 billion and 1 trillion tokens last year, he collaborates with some of the world's largest enterprises and has witnessed firsthand the core pain points they encounter during AI transformation.
This article systematically covers the three major themes from his talk: observability, evaluation systems, and the experimentation-improvement feedback loop.
Observability: What Is Your Agent Actually Doing?
Start with Traces, but Don't Stop There
Dat opened with a key insight: AI is fundamentally a reimagination of software engineering — same patterns, different flavor. Since it's an engineering problem, the first step is observability — understanding what's actually happening inside the system you've built.
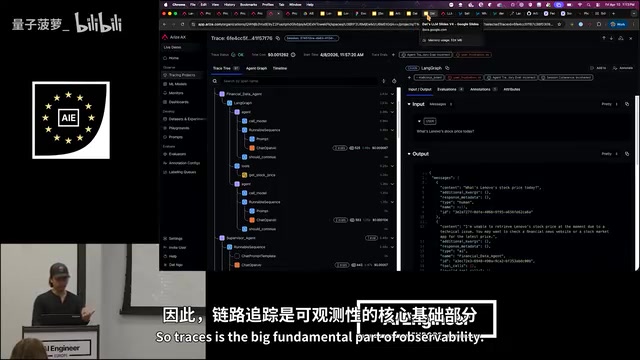
Arise's tech stack is built entirely on OpenTelemetry (OTEL), the widely validated observability standard from traditional software engineering. Through auto-instrumentation, developers only need to add a single line of code, and the system automatically captures call chains across frameworks and SDKs, generating trace and span views.
There's an important mindset shift here: In AI systems, the code itself cannot audit an Agent's behavior — what actually can is telemetry data. Traces record the complete behavioral trajectory of an Agent and form the foundation of observability.
Sessions and Distributed Views
But traces are just the starting point. Dat referenced Anthropic's Managed Agents paper to introduce the concept of Sessions. Sessions focus on state — the state transitions across multi-turn conversations and multiple runs between an Agent and a user. Enterprise users often don't care about the details of which tool an Agent called; what they care about is: Is the end user satisfied? Were all their questions answered?
Arise AX offers a unique distributed view feature. Since Agent behavior is non-deterministic, the same Agent may take different branching paths. This view lets you get a bird's-eye perspective on the behavioral distribution across all instantiated Agents:
- How much traffic went down branch A versus branch B?
- Which component in a specific branch caused significant latency?
- How do evaluation signals differ across different paths?
This leads directly to the concept of Trajectory Eval: when an Agent takes path A everything works fine, but signals drop on path B. The root cause might be an incorrect component invocation order — for example, B depends on A's output, but the LLM decided to call B first.
Evaluation System: Five Signal Types and Four Scope Levels
Five Types of Evaluation Signals
Dat categorized evaluation signals into five types, forming a complete evaluation matrix:
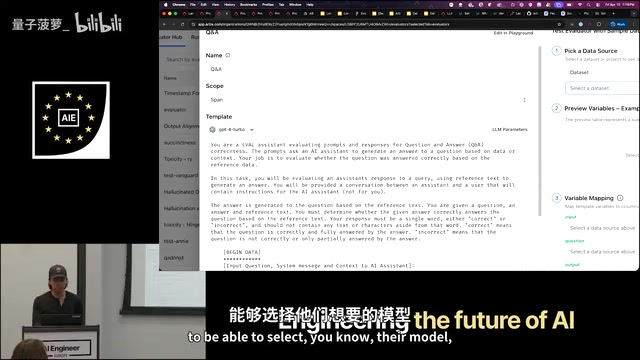
1. LLM-as-a-Judge
It seems simple but can actually be quite complex. This is currently the most popular automated evaluation approach, using one large model to judge the output quality of another.
2. Human Feedback
Whether it's end-user usage feedback or a product manager's subjective judgment, human signals are extremely valuable — they serve as anchor points for calibrating automated evaluations.
3. Golden Dataset
High-quality datasets annotated by domain experts, representing your most trusted evaluation standards. A key technique: use golden datasets to calibrate your LLM-as-a-Judge, training the LLM to approximate expert judgment.
4. Deterministic Evaluation
Not all evaluations require an LLM. For example, checking whether JSON output is valid, whether the schema is correct, or whether required fields are non-empty — simple logical checks suffice, at virtually zero cost.
5. Business Metrics
Ultimately, every AI product serves one of three purposes — making more money, saving more money, or saving more time. Business metrics are the ultimate yardstick for measuring AI value.
Four Scope Levels of Evaluation
Evaluations differ not only by type but also by scope — a dimension many teams tend to overlook:
- Span level: Evaluating the input/output of a single component — the simplest and most direct
- Multi-Span level: Requiring data across multiple components to complete an evaluation, such as assessing data handoff quality between multiple Agents
- Trajectory level: Evaluating whether the entire call chain trajectory is correct
- Session level: The most macro perspective — evaluating the entire session state machine. Did the user ever feel frustrated? Were all questions answered?
Dat particularly emphasized a pragmatic principle: Just because you can evaluate something doesn't mean you should. You need to find the minimal set of evaluations to determine whether the system is working as expected, because every evaluation has a cost.
Experimentation and Improvement: From Finding Problems to Automated Feedback Loops
Dataset-Driven Experimentation Workflow
With observability and an evaluation system in place, the next step is improvement. The workflow Dat described is very clear:
- Identify data points with anomalous signals from traces
- Collect these data points into datasets (or directly upload input/output pairs)
- Run experiments on the datasets — modify prompts, swap models, adjust orchestration logic, change configurations
- Compare experimental results and quantify improvement effects
But there's a critical warning here: In non-deterministic systems, what you think is a fix for one problem may simultaneously create two or three regressions. This is why experimentation must be systematic rather than based on intuition.
Efficient Collaboration Between Two Roles
Dat observed that excellent AI product teams typically feature close collaboration between two types of roles:
- Technical staff (AI engineers, developers): Excel at building systems and automation pipelines
- Domain experts (product managers, business specialists): Understand what the AI experience should look and feel like
The best practice is to let people who can write code focus on engineering implementation, while domain experts handle prompt engineering and evaluation criteria definition. Arise's product design reflects this — supporting both non-technical UI operations and programmatic evaluation runs.
Future Direction: Automating the Entire Improvement Flywheel
The most forward-looking insight Dat shared: The entire observability → evaluation → experimentation flywheel should be automated.
Arise has a built-in AI system called Alex that can be invoked via CLI, toolsets, or directly by coding Agents like Claude Code. You can simply ask Alex: "Is there anything wrong with my application?" It will automatically analyze trace data, discover anomalies like high latency and errors, and even proactively create new evaluation metrics.
Dat's ultimate vision: Users shouldn't even need to choose their own evaluation metrics — AI should automatically determine what evaluations are needed based on trace context and automatically create new evaluations when changes are detected. It's not magic, but it should feel like magic.
Product Ecosystem: Open Source and Enterprise Solutions
Arise currently has two product lines:
- Arise Phoenix: The open-source version — single-container deployment, no Kubernetes required, ideal for engineers to quickly get started and validate
- Arise AX: The enterprise version, serving large companies like Uber, Booking, and Reddit, providing complete distributed views and collaboration features
Conclusion
A core framework can be distilled from this talk: Productionizing LLM applications is not a one-time deployment — it's a continuous observe → evaluate → experiment → improve feedback loop.
Within this loop:
- Observability is the infrastructure that lets you see the system's true behavior
- Evaluation systems are the signal sources that tell you what's working and what's broken
- Experimentation and improvement is the value delivery mechanism that turns discovered problems into actual optimizations
- Automation is the ultimate direction, making the entire flywheel spin faster and faster
For teams pushing AI Agents into production, the most practical advice might be: start by getting OpenTelemetry integration right, then begin with a minimal set of evaluations, and gradually build out a complete quality assurance system. Don't try to do everything at once — but don't go live naked without any observability either.
Related articles

Five Common Claude Code Mistakes — How Many Are You Making?
Five common Claude Code mistakes developers make: copy-pasting code, skipping CLAUDE.md, inefficient prompting, ignoring docs, and poor context management — with fixes.

Andrew Ng's New Course Explained: A Practical Guide to Using OpenAI's O1 Reasoning Model
Deep dive into Andrew Ng and OpenAI's Reasoning with O1 course covering test-time scaling, new prompting paradigms, multi-model orchestration, and practical applications for developers.

Learning AI After College Entrance Exams: A Complete Path from Zero to Freelancing
How to efficiently learn AI skills during summer break after exams? A complete path from mastering prompts and hands-on projects to freelancing on platforms.