Marvell: The Hidden Giant Behind AI Infrastructure — Four Technical Aces Explained
How Marvell became AI infrastructure's indispensable hidden giant through four key technologies.
Marvell is positioning itself as the critical "road builder" of AI infrastructure by addressing the communication wall and memory wall that plague large-scale GPU deployments. Through UALink switch chips, CXL memory pooling, custom ASIC foundry services, and silicon photonics, Marvell has created a business model with deep moats — high switching costs, win-win positioning regardless of who dominates AI, and multi-year revenue pipelines locked in with the world's largest cloud providers.
While 99% of investors are still fixated on NVIDIA's GPU shipment numbers, top Wall Street funds have quietly shifted their positions toward another critical node in the AI supply chain — Marvell. This company, with decades of expertise in networking interconnects and custom chips, is becoming the indispensable "road builder" of AI infrastructure.
The Real Bottleneck for Large AI Models: It's Not Compute — It's Connectivity
The Communication Wall and Memory Wall: Overlooked Efficiency Black Holes
To understand Marvell's value, you first need to understand the physical bottlenecks facing today's large AI models. In the world of supercomputers, compute power doesn't scale linearly — a single GPU has a compute power of 1, but 100 GPUs connected together might only deliver 80, and when scaling to tens of thousands of GPUs, overall efficiency can plummet below 40%. More than half of the compute power is consumed by data transfer and waiting — this is what the industry calls the "communication wall."
Running parallel to the communication wall is the "memory wall." AI computation is extremely dependent on high-speed HBM memory, but this memory is expensive, capacity-constrained, and there's a physical limit to how much HBM can be soldered onto a single GPU. As model parameter counts double every few months, GPUs are forced to read data from external standard memory, with a speed gap comparable to a bullet train versus a crawl. A joke circulating among engineers — "the compute is slacking off while the electricity bill is skyrocketing" — perfectly captures this dilemma.
What's Really Keeping Tech Giants Up at Night
Google, Microsoft, Meta, Amazon AWS, and other tech giants aren't losing sleep over failing to secure NVIDIA cards anymore — they're agonizing over the inability to efficiently stitch together the cards they've already secured. Whoever solves this problem can save these giants tens of billions of dollars in electricity and procurement budgets. And Marvell has positioned itself precisely at this most painful pressure point.
Marvell's Four Technical Aces
Ace #1: UALink Switch Chips — The Core of an Anti-Monopoly Alliance
NVIDIA's true killer advantage isn't just the GPU itself — it's their proprietary NVLink interconnect technology. This technology enables NVIDIA GPUs to exchange data at astonishing speeds, but the rules are extremely restrictive: NVLink only serves NVIDIA's own GPUs, and customers must purchase the entire networking equipment bundle, locked tightly into the ecosystem.
The long-frustrated giants have finally joined forces to fight back. Google, Microsoft, Meta, Amazon AWS, AMD, and others have jointly launched UALink, an open-source, open industry standard aimed at establishing a connectivity technology that matches NVLink's performance but works across the entire industry. And within this alliance, the company actually responsible for manufacturing the chips is Marvell.
Marvell acquired Alphawave Semi (formerly XCOM Technology) for $5.4 billion — the company furthest ahead in next-generation high-speed interconnect technology — seamlessly integrating their technology into the UALink chip product line. This means: any tech giant that wants to break free from NVIDIA's bundling will inevitably need Marvell's UALink switch chips at the foundational level. Marvell has essentially built a highway outside NVIDIA's siege that every player must travel, and positioned itself as the exclusive toll booth.
Ace #2: CXL Chips — A Lifeline for Data Center Memory Famine
Marvell's Structura CXL chip addresses the memory wall problem. In plain terms, it equips the entire data center with a super shared memory pool.
Previously, each server's memory operated in isolation, creating an absurd situation: neighboring general-purpose servers had massive amounts of idle memory while AI servers were bursting at the seams. The Structura CXL chip transcends physical server boundaries, weaving thousands of standard DDR4/DDR5 memory modules across the data center into a communal "reservoir" via networking — when AI GPUs need more memory, they simply "draw water" at extremely high speeds with ultra-low latency.
Even more elegant: this technology allows giants to repurpose memory from servers retired in previous years. For mega-spenders with annual hardware budgets in the tens of billions of dollars, this isn't just an ordinary chip — it's a life-extension surgery for their wallets. Moreover, Structura was designed from the ground up to be deeply customized according to Google's and Meta's underlying architectures, binding these major customers' lifelines to Marvell early on.
Aces #3 and #4: Custom ASIC Chips + Proprietary Memory Architecture
Google has TPU, Amazon has Trainium, Meta has MTIA — giants are all "designing their own chips," but what outsiders don't realize is: these companies typically only handle the top-level algorithm logic and high-level architecture. Turning designs into actual circuits, orchestrating billions of transistor connections, and ensuring memory and compute cores don't bottleneck — this "detailed dirty work" is beyond their capabilities.
In the U.S. stock market, only two companies are qualified to take on these "premium supercar foundry orders": the leader Broadcom, and the runner-up Marvell. As AI demand explodes, Broadcom alone can't absorb all the capacity, and major companies don't want to be monopolized by a single supplier — opening Marvell's golden window. Currently, Marvell has signed multi-year deep collaboration agreements with the world's top cloud providers, deeply participating in the R&D and mass production of next-generation custom AI chips.
Three Pillars of Marvell's Business Model: Why the Moat Is Exceptionally Deep
Unlike NVIDIA's high-risk model of "designing products and selling them to customers," Marvell's business model can be distilled into eight words: deep customization, long-term lock-in.
Pillar One: Extremely high switching costs. What Marvell sells to major companies isn't plug-and-play standard components — it's custom solutions welded into the foundational skeleton of data centers. The entire facility's operating system, underlying code, power distribution, and cooling are all built around this hardware. Switching means starting from scratch and rewriting tens of millions of lines of code — a cost so prohibitive it's demoralizing.
Pillar Two: A win-win positioning that profits rain or shine. If a tech giant's in-house chip succeeds, Marvell — as the primary foundry partner and memory architecture supplier — gets flooded with orders. If the in-house effort falters and the giant continues purchasing massive quantities of NVIDIA GPUs, the communication wall becomes more severe, making them even more dependent on Marvell's UALink switch chips and silicon photonic modules. Regardless of who wins the AI war, Marvell is the third party that always profits.
Pillar Three: Ultra-long revenue pipelines. Custom projects typically take 2-3 years from inception to mass production. Once a contract is signed, there's clear, massive revenue for the next 3-5 years. This "grain in the barn, peace in the heart" model is a luxury in the highly volatile tech industry.
The Hidden Play: Silicon Photonics and the Materials Science Chess Game
Marvell quietly completed an acquisition that mainstream media overlooked but sent shockwaves through the tech community — Swiss startup Polariton Technologies. This deal targets the ultimate direction of next-generation communications: replacing electrons with light.
As data transmission speeds push toward 200G and 400G, traditional copper wiring faces two irreconcilable walls: signal attenuation and heat generation. Polariton's Pockels modulator technology can shrink optical modulators by 2-3 orders of magnitude (to just 10-15 micrometers), slash power consumption by 100x, boost transmission speeds by over 10x, and can be co-packaged directly with chips like LEGO blocks.
But there's a subtle supply chain chess game hidden here: the Pockels modulator's core performance depends on a special organic electro-optic polymer material, whose exclusive global patent is held by another low-profile company, LightWave Logic. Marvell acquired the hardware team and structural patents, but must procure this specialty material long-term for mass production. As a far-sighted tech company, Marvell is also privately engaging alternative suppliers (such as NLM Photonics) and will most likely introduce a second supplier to ensure supply chain security and suppress procurement costs.
Risks and Challenges Facing Marvell
No company is perfect, and Marvell faces a triple challenge:
- Technology iteration risk: Silicon photonics and CXL still have significant engineering hurdles to overcome between the lab and million-unit-scale mass production
- Pressure from being squeezed between giants: Peers like Broadcom are watching closely, and major companies' in-house strategies could shift at any time
- Valuation dynamics: As more institutional capital flows in, market expectations get pushed higher, and any production delays or technical flaws could trigger sharp short-term volatility
But taking a longer view, Marvell's story reveals a deeper trend: AI competition has permeated downward from the algorithm layer, through the chip layer, all the way to semiconductor materials and the physics layer. Next time you see a major company bringing online a super cluster of tens of thousands of GPUs, it's worth asking: with all those cards connected together, have the roads between them been properly built? And who's building those roads?
The answer to that question may be the key to understanding the next phase of AI investment logic.
Related articles
Developing Figma Plugins with Codex: A Zero-Code Guide for Designers
Learn how to build Figma plugins with OpenAI Codex — no coding required. Covers project setup, quota management, Plan Mode, hands-on development, and publishing tips for designers.

Codex APP In-Depth Review: Head-to-Head Comparison with Claude Code and Tool Selection Guide
In-depth comparison of Codex APP vs Claude Code across pricing, stability, and capabilities. Codex for frontend, Claude Code for backend, plus selection guide for all three AI coding tools.
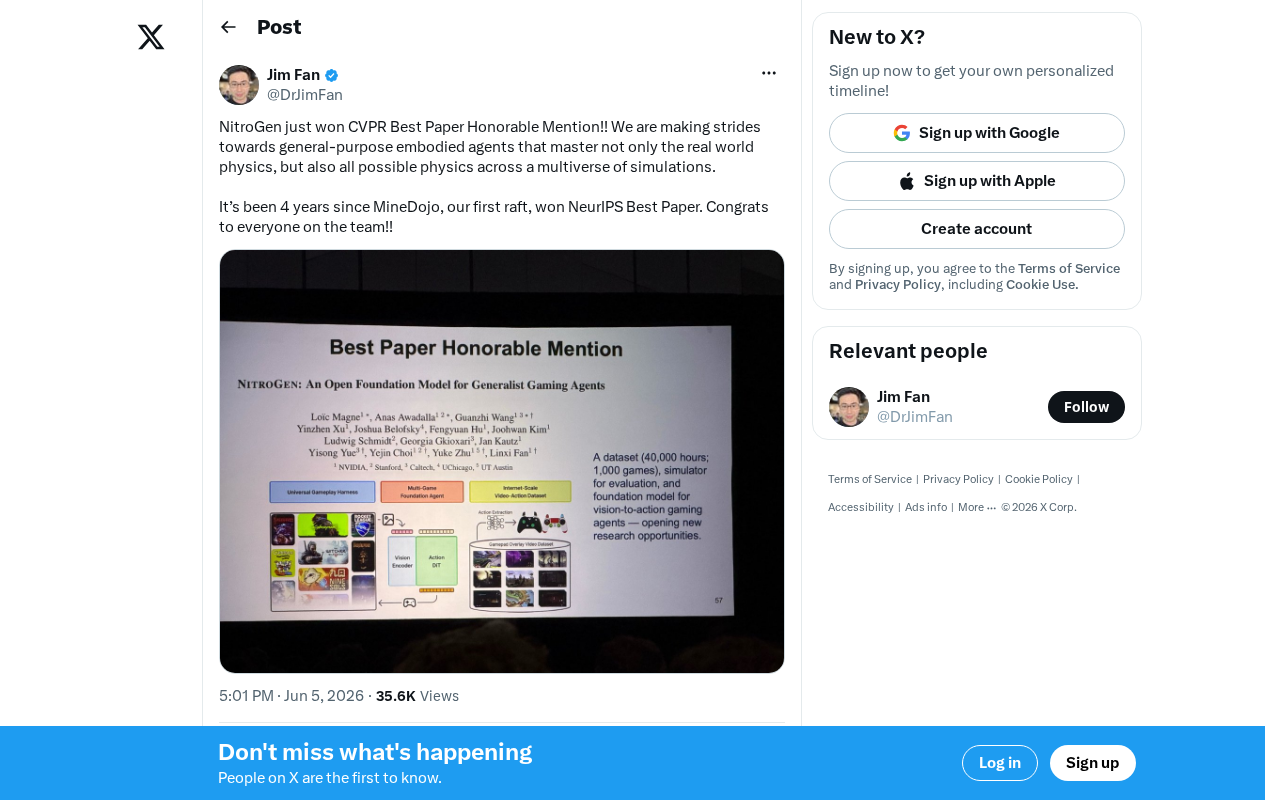
NitroGen Receives CVPR Best Paper Honorable Mention: A New Breakthrough for General-Purpose Embodied Agents
NitroGen wins CVPR Best Paper Honorable Mention for building general-purpose embodied agents across multi-physics worlds. Explore the four-year journey from MineDojo to NitroGen.