Matt Pocock's AI Coding Workflow: A Complete Methodology from Ideation to Delivery

Matt Pocock shares a systematic AI coding methodology: from requirement consensus to automated execution.
TypeScript educator Matt Pocock demonstrates a systematic AI-assisted coding workflow. He identifies two key LLM traits — a Smart Zone (~100K tokens) and memory resets — and designs a four-stage process: building human-AI consensus through Grill Me Q&A, generating PRD documents, decomposing tasks via Tracer Bullets vertical slicing, and letting AI auto-execute under TDD constraints. He also emphasizes that Deep Modules architecture is better suited for AI coding, and that classic software engineering practices are more important than ever in the AI era.
Matt Pocock is a well-known TypeScript educator who has recently shifted his focus to AI-assisted programming. In a two-hour live demonstration, he systematically showcased how to efficiently leverage AI for software development — from initial ideation to final code delivery. This article distills the core methodology and practical techniques he shared.
Two Key Characteristics of LLMs
Smart Zone vs. Dumb Zone
Matt begins by pointing out a core characteristic of LLMs: they have a "Smart Zone" and a "Dumb Zone." When you start a new conversation, the LLM is at its best. But as tokens accumulate in the context window, the model's performance gradually degrades.
He argues that even if a model claims to support a 1-million-token context window, the true Smart Zone is roughly within 100,000 tokens. Beyond that range, the model becomes increasingly unreliable when making complex decisions.
This phenomenon is known in academia as the "Lost in the Middle" problem. A 2023 Stanford study showed that when critical information is located in the middle of a long context, the model's retrieval accuracy drops significantly. This is related to how the attention mechanism works in the Transformer architecture — self-attention needs to compute relationships between all tokens, and as sequence length increases, computational complexity grows quadratically, causing a "dilution effect" in how the model distributes attention weights. Although vendors have mitigated this issue through techniques like sparse attention and sliding windows, in practice, the model's reasoning quality at the tail end of long contexts still falls short of short-context scenarios.
This means we need to design tasks small enough to keep the AI working within its Smart Zone.
Memento-Style Memory
The second characteristic of LLMs is that they're like the protagonist in the movie Memento — every time the context is cleared, they return to square one, forgetting everything that came before.
This leads to the concept of "Compaction": when a session has accumulated too much content, you can compress it into a concise summary and start a new session. Compaction is essentially a lossy compression strategy from information theory — in AI coding tools, this typically means having the model generate a structured summary of the current session, retaining key decisions, code changes, and outstanding items, then discarding the original verbose conversation history. Tools like Claude Code and Cursor have built-in mechanisms for this. The theoretical basis is that a large portion of conversation content is exploratory, repetitive, or has been superseded by subsequent decisions — the actual "effective information density" that needs to be retained is far lower than the raw token count.
Matt recommends monitoring the token usage of each session and suggests tools like AI Hero for tracking this metric.
The Four Stages of the Complete Workflow
Stage 1: Grill Me — Building Consensus Through Q&A
Matt developed a Custom Skill called "Grill Me," whose core philosophy comes from the concept of "design concepts" mentioned in Frederick P. Brooks' The Design of Design — team members need to establish a shared mental model.
Frederick P. Brooks is a towering figure in computer science history, renowned for leading the IBM System/360 project and writing The Mythical Man-Month. In his 2010 book The Design of Design, he proposed that the core of excellent design lies in team members sharing "Conceptual Integrity" — meaning all participants hold a consistent mental model of what the system should look like. Brooks argued that the root cause of design failure is often not a lack of technical ability, but divergent understandings of the problem and solution among team members. Matt extends this philosophy to human-AI collaboration: before having AI execute any task, you must first ensure that both human and AI share the same understanding of the goal.
Grill Me works by having the AI ask you questions one by one, deeply exploring your requirements and constraints. Instead of having the AI directly generate a plan, it builds consensus between both parties through Q&A. Matt emphasizes:
"I don't need an asset, I don't need a plan, I need to be on the same wavelength as the AI."
This process may involve 20 to 100 questions. It seems time-consuming, but it ensures accuracy in subsequent execution. This is a "human must be at the keyboard" step that cannot be automated.
Stage 2: Generating the PRD (Product Requirements Document)
After building consensus through the Grill Me session, Matt uses another skill to transform the conversation into a Product Requirements Document (PRD). The PRD includes:
- Problem statement and solution
- User Stories
- Implementation decisions
- Testing decisions
- Module breakdown
The key point: Matt doesn't carefully read the generated PRD. His logic is — since he has already established consensus with the LLM through Grill Me, and LLMs excel at converting consensus into written text, he just needs to trust the process.
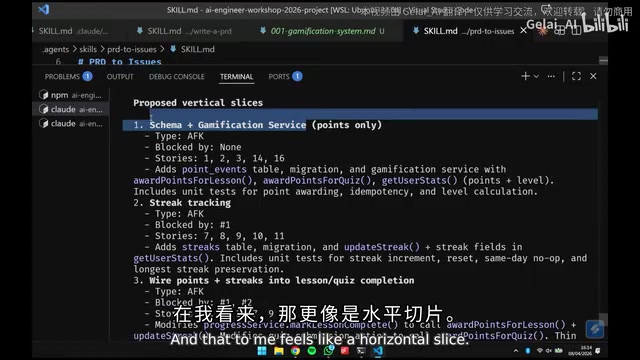
Stage 3: Kanban Board and Tracer Bullets (Vertical Slicing)
After the PRD is generated, Matt breaks it down into task cards on a Kanban Board. Here he introduces a key concept — Tracer Bullets, originating from Andrew Hunt and David Thomas' classic book The Pragmatic Programmer.
In the military, tracer bullets are luminous rounds that allow shooters to see the trajectory in real time and adjust their aim. In software engineering, this metaphor refers to quickly building a minimal working path that cuts through all layers of the system — a complete chain from the user interface to the database. Unlike prototypes, Tracer Bullet code is real, production-quality code that's meant to be kept — just with minimal functionality. The core value of this approach is exposing integration risks and errors in architectural assumptions as early as possible.
Traditional AI tends toward horizontal coding: complete all database work first, then all API work, and finally the frontend. The problem with this approach is that you can't verify whether the entire system works until the last layer is finished.
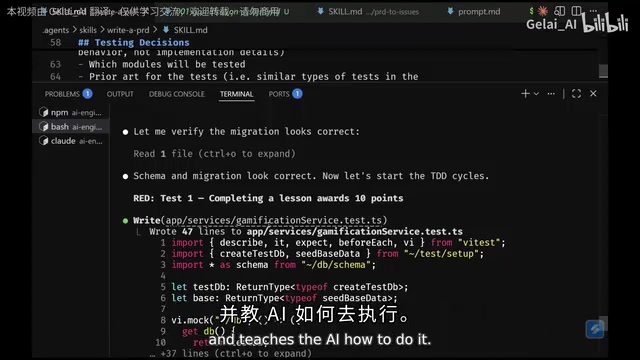
The correct approach is vertical slicing: each task should cut through all layers (database → API → frontend), so you get end-to-end feedback as soon as the first task is complete.
Stage 4: AFK Automated Execution and QA Review
Matt refers to the actual coding as "AFK" (Away From Keyboard) tasks — this is the only step where AI can work independently. He built a looping script called "Ralph" that lets Claude Code automatically execute tasks inside a Docker sandbox.
Execution flow:
- Fetch the next task from the Kanban Board
- Code using TDD (Test-Driven Development)
- Run feedback loops (type checking, tests)
- Generate a commit
Test-Driven Development (TDD) was systematically formalized by Kent Beck in 2003. Its core cycle is "Red-Green-Refactor": first write a failing test, then write the minimum code to make the test pass, and finally refactor the code. In the AI coding context, TDD takes on new strategic significance — tests serve as "validators" and "constraints" for AI code generation. When AI is coding autonomously in a Docker sandbox, pre-written test suites provide objective, automatable quality feedback signals, enabling the AI to independently determine whether the code meets requirements without real-time human intervention. This essentially transforms software quality from subjective judgment into a computable boolean value.
Afterward, humans conduct a QA review — this is the critical moment for injecting personal judgment into the system.
Code Architecture: Why Deep Modules Matter for AI Programming
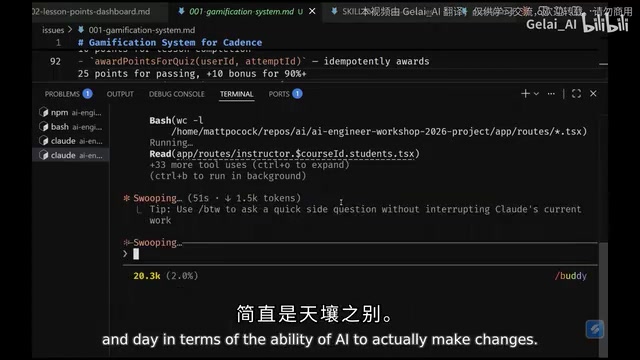
Matt references concepts from John Ousterhout's A Philosophy of Software Design (published in 2018), emphasizing the importance of Deep Modules for AI programming.
Ousterhout argues that a module's "depth" equals the ratio of its functional complexity to its interface complexity. A deep module exposes a simple interface externally while encapsulating a large amount of complex logic internally — Unix's file I/O system is a classic example, encapsulating file systems, caching, permission management, and other complex implementations through just a few calls like open/read/write/close. Conversely, shallow modules (like the common getter/setter classes in Java) have interface complexity nearly equal to implementation complexity, adding cognitive burden to the system without providing real abstraction value. Ousterhout's perspective stood in stark contrast to the then-popular dogma of "small classes, small methods."
Specifically in the AI programming context:
- Shallow Modules: Many small files, complex dependencies, hard to test, poor AI performance
- Deep Modules: Fewer large modules, simple interfaces, rich internal implementations, easy to test
Deep module architecture enables AI to:
- Understand complete context within a single module
- Write meaningful tests
- Achieve better feedback loops
Matt developed an "Improve Codebase Architecture" skill that can scan existing codebases and identify opportunities to consolidate into deep modules.
Code Review and Team Collaboration Strategies
Matt acknowledges that as AI generates more code, the code review workload does increase. His strategies include:
- Using the Opus model for code review (requires higher intelligence)
- Using the Sonnet model for code implementation (better cost-effectiveness)
- Injecting coding standards into the reviewer's prompt
- Propagating standards through "push" rather than "pull"
Anthropic's Claude model family is divided into tiers by capability: Opus is the most powerful reasoning model, excelling at complex analysis and judgment; Sonnet is a mid-tier model that balances speed and quality; Haiku is the fastest and most lightweight option. Matt's strategy of assigning code review to Opus and code implementation to Sonnet reflects an important engineering economics principle: different tasks require different levels of intelligence. Code implementation is a relatively deterministic task (constrained by tests), while code review requires understanding design intent, identifying potential issues, and evaluating maintainability — all higher-order cognitive activities. This tiered usage strategy maximizes overall output quality while controlling costs.
For team collaboration, he emphasizes that the entire process from ideation to PRD should be a team activity — only the execution stage can be delegated to AI.
Core Philosophy: Classic Software Engineering Practices Are Even More Important in the AI Era
Matt repeatedly emphasizes one point: AI is not an entirely new paradigm — good software engineering practices remain effective in the AI era. Whether it's TDD, vertical slicing, modular design, or incremental delivery, these classic methodologies become even more important in AI-assisted programming.
His recommended classic books include: The Pragmatic Programmer, Refactoring, A Philosophy of Software Design, and The Design of Design. This time-tested software engineering wisdom is the key to making AI programming truly efficient.
Key Takeaways
- LLMs have a Smart Zone (~100K tokens) and a Dumb Zone; tasks must be designed to stay within the Smart Zone
- The Grill Me skill builds human-AI consensus through iterative questioning — a prerequisite for high-quality output
- The Tracer Bullets vertical slicing method breaks down tasks to ensure end-to-end feedback with every iteration
- Deep Modules architecture (fewer large modules + simple interfaces) is better suited for AI programming and testing than Shallow Modules
- The complete workflow: Grill Me for consensus → Generate PRD → Kanban task breakdown → AFK automated execution → Human QA review
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.