memU Memory Framework Explained: Unifying Multi-Modal Agent Memory with a File System
memU Memory Framework Explained: Unify…
memU organizes AI Agent memory as a file system for hierarchical persistent memory management.
memU is an Agent Memory framework whose core innovation maps memory to a file system structure (folders=categories, files=entries, symbolic links=associations). It employs a three-layer semantic abstraction architecture from Conversation Layer → Item Layer → Category Layer, implements active memory through dual-loop collaboration between Agent Loop and memU Loop, and provides both RAG and LLM-based retrieval modes. The article also discusses challenges facing the Agent Memory field including inconsistent evaluation standards and method homogeneity, as well as future directions like knowledge internalization.
The Debate Over Agent Memory's Future Direction
Agent Memory refers to the technology ecosystem that provides AI agents with persistent memory capabilities across sessions. Traditional large language models are inherently stateless—once a conversation ends, the context information vanishes. To address this problem, researchers and engineers have developed various external memory systems that enable agents to "remember" user preferences, interaction history, and domain knowledge. This field has rapidly evolved in recent years with the launch of ChatGPT's Memory feature and the rise of various Agent frameworks, becoming critical infrastructure for building personalized AI assistants.
Before diving into the memU project, it's worth discussing the current development landscape of Agent Memory. Based on community discussions and voting data, the future direction of Memory technology roughly splits into several paths:
- Reinforcement Learning & Knowledge Internalization: Received the most support and is considered the ultimate goal of Memory. Since large language models are essentially parameterized weight files, why can't memories be directly internalized into the model? This is similar to the end-to-end approach in autonomous driving. The idea of internalizing memory into model parameters essentially involves dynamically updating model weights through Continual Learning or online reinforcement learning as interaction experience accumulates. This fundamentally differs from mainstream external memory systems—the former encodes knowledge in neural network weights, while the latter relies on external storage and retrieval. The core challenge of knowledge internalization is "Catastrophic Forgetting"—models tend to overwrite old knowledge when learning new information, a problem that remains unsolved in the continual learning field.
- Bionic & Brain-Inspired: A neuroscience and cognitive science-inspired approach that complements the computer science route.
- Hierarchical Transfer & Scoring: The current mainstream approach, including short-term/medium-term/long-term memory, L1/L2/L3 hierarchies, etc.
- Knowledge Graphs & Multi-Modal: A relatively new exploration direction.
A notable practical issue is that nearly all Memory frameworks revolve around CRUD (Create, Read, Update, Delete) operations. CRUD is a classic operational paradigm from the database domain, representing four basic data operations, which correspond to memory creation, reading, updating, and deletion in Memory frameworks. These frameworks perform vector retrieval through embeddings—converting text into high-dimensional vectors and finding semantically similar memory entries by computing metrics like cosine similarity—with highly homogeneous methods. Benchmark datasets like Locomo have been "gamed to death," with different frameworks using different judgment prompts (prompts that instruct LLMs to determine whether answers are correct), making scores incomparable. This "aesthetic fatigue" is driving the community to seek new breakthroughs.
memU's Core Design: Memory as a File System
The core innovation of the memU project lies in organizing memory as a file system. As a core abstraction of operating systems, file systems have decades of development history with extremely strong universality and comprehensibility. The idea of mapping memory to a file system essentially borrows a mental model of information organization that humans are already familiar with. This design philosophy aligns with the recent trend of Harness concept engineering—whether it's Claude Code reading and writing Markdown, or various CLI tools and Agent frameworks, file systems are becoming a universal paradigm for information organization.
File System Organization Structure
memU's memory storage adopts the following hierarchy:
- Folders = Categories: Automatically organized topic folders, such as
preferences/,relationships/,knowledge/,context/ - Files = Memory Entries: Each Markdown file stores extracted facts, preferences, skills, etc.
- Symbolic Links = Associated Memories: Symbolic Links are special files in Unix/Linux systems that point to another file or directory, similar to shortcuts. memU uses this mechanism to express relationships between memories, allowing the same memory entry to be referenced under multiple categories without duplicate storage.
- Mount Points = External Resources: Mount Points are mechanisms for attaching external storage devices or resources to the file system tree. memU borrows this concept to implement references to raw resources like conversations, documents, and images, ensuring everything is "traceable."
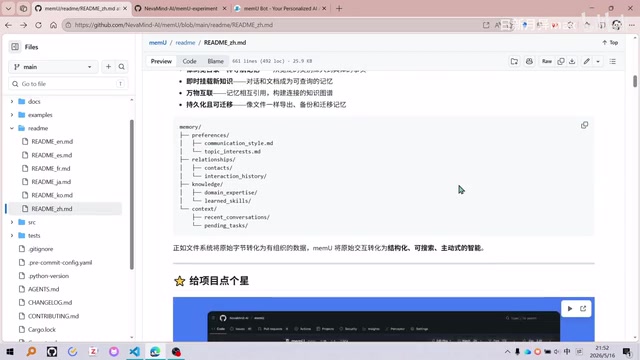
This design brings several practical benefits: browsing directories allows navigating memories, drilling down from broad categories to specific facts; memories exist as files, naturally supporting export, backup, and migration; new knowledge becomes queryable memory through mounting, ensuring traceability.
Three-Layer Memory Abstraction Architecture
memU designs a three-level abstraction from raw data to high-level semantics:
Layer 1: Conversation Layer (Resource Layer)—Stores raw data from user-Agent conversations, including user questions, Agent responses, and multi-modal information. This is the lowest level of native data.
Layer 2: Item Layer—Extracts factual memories from conversations, transforming raw dialogue into structured entries through large models. Entries cover various types including episodic memory, semantic memory, perceptual memory, procedural memory, etc.
Layer 3: Category Layer—Further organizes entries into summary-level overviews, generating semantic files at a higher abstraction level. For example, consolidating all profile-related entries into multiple Markdown files under the profile/ folder.
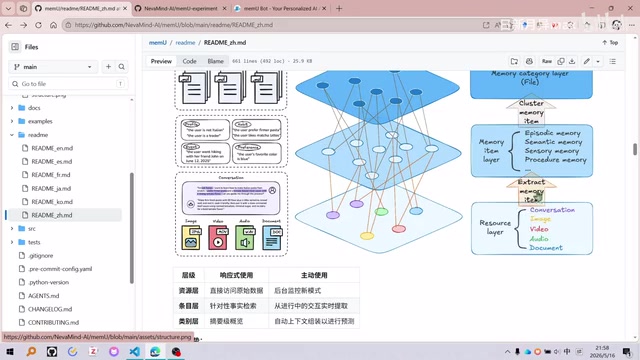
This achieves a progressive semantic abstraction process from conversation → entry → file, which is the key distinguishing feature of memU from other Memory frameworks.
How Active Memory Works
The two major advantages memU emphasizes are active agent and reduced token cost. Its working principle involves two parallel loops:
Dual-Loop Collaboration Mechanism
Agent Loop (Main Loop): Users send requests through platforms like Feishu (Lark), the Agent receives input, plans execution, and returns responses, forming a standard conversation loop.
memU Loop (Memory Loop): The memU software runs independently as a real-time plugin, performing the following operations:
- Monitoring: Real-time tracking of user inputs and outputs, observing Agent behavior, recording conversation trajectories
- Storage & Retrieval: Implementing memory updates and injection through memory functions
- Extraction: Extracting skills and knowledge from the Agent's reasoning and tool calls, updating user profiles
- Prediction & Suggestions: Predicting user intent based on returned results, executing proactive tasks, and providing suggestions to the Agent Loop
The key point is that memU injects memories into the Feishu bot, enabling it to "remember" previously stored information. memU is essentially an independently running memory plugin that forms a collaborative relationship with the main Agent.
Code Architecture Analysis
memU's code structure is clean, with core implementation concentrated in the src/memu/ directory.
Core Modules
App Directory—The most critical service layer:
service.py: Core service entry point, also the main file for cloud deploymentmemorize.py: Memory storage implementation (~1000+ lines), responsible for extracting conversation data into entries, then organizing them into files through conflict resolutionretrieve.py: Memory retrieval implementation (~1000+ lines), providing two retrieval methodscrud.py: CRUD operations implementation for memories
Two Retrieval Modes
RAG-Based Retrieval: RAG (Retrieval-Augmented Generation) is one of the most mainstream knowledge enhancement techniques in current AI applications. Its core approach is to retrieve relevant content from an external knowledge base before generating an answer, then feed both the retrieved results and the user's question into the large model. In memU, RAG retrieval is fast, directly searching through embeddings in the knowledge base and concatenating results, suitable for latency-sensitive scenarios.
LLM-Based Retrieval: Deeper reasoning that includes intent prediction, query rewriting, query evolution, and other steps, ultimately merging retrieved memories with the query (merge context) before handing it to the Agent for answering. This approach compensates for pure vector retrieval's potential to miss memories that require reasoning to associate, through intent understanding, but at the cost of higher latency and token consumption. The two modes provide a clear trade-off between speed and accuracy.
Prompts Directory
This is another directory worth careful study. A Memory system's core capabilities largely depend on prompt design quality. memU organizes prompts as JSON strings, categorized by function, such as retrieve/ containing sub-modules like reranker and rewrite.
Configuration Requirements
Like most Memory frameworks, memU requires two basic configurations:
- LLM API: For memory extraction, storage, and reasoning operations
- Embedding API: For vectorized retrieval
The project supports virtual environment management through UV, depends on the Rust runtime, and supports four integration methods: Telegram, Discord, Slack, and Feishu (Lark).
Performance & Limitations
memU achieves 92% accuracy on the Locomo test, covering single-hop, multi-hop, open-domain, and temporal scenarios. Locomo (Long-Context Conversation Memory) is a benchmark dataset specifically designed to evaluate conversational memory systems, containing multi-turn conversation records spanning months, covering task types including single-hop reasoning (finding answers directly from memory), multi-hop reasoning (requiring association of multiple memories), open-domain QA, and temporal understanding. However, as community discussions point out, current evaluation benchmarks themselves have limitations—different frameworks use different judgment prompts, making absolute score values incomparable. This "evaluation contamination" phenomenon is prevalent in the NLP evaluation field.
From a practical application perspective, beyond token costs, memory storage and retrieval time costs are equally critical. Overly complex frameworks may introduce latency in retrieval and CRUD operations that no longer meets practical application requirements. memU simplifies this problem to some extent through its file system approach, but performance under large-scale memory scenarios still needs validation.
The core challenge facing the Memory field currently isn't the complexity of framework design, but how to find the balance between simplicity, practicality, and memory quality. memU's file system approach offers an interesting perspective—transforming the memory problem into a file management problem, which may reduce system complexity while maintaining sufficient flexibility.
Key Takeaways
- memU organizes memory as a file system structure, implementing hierarchical memory management through folders=categories, files=entries, and symbolic links=associations
- Adopts a three-layer abstraction architecture: Conversation Layer (raw data) → Item Layer (structured extraction) → Category Layer (semantic files), achieving progressive semantic abstraction
- Implements active memory through the dual-loop collaboration mechanism of Agent Loop and memU Loop, with memU running as an independent plugin for real-time monitoring, storage, retrieval, and memory injection
- Provides two memory retrieval modes: RAG-based (fast) and LLM-based (deep reasoning), offering a choice between speed and accuracy
- The Agent Memory field faces challenges of inconsistent evaluation standards and highly homogeneous methods (CRUD + embedding), with reinforcement learning and knowledge internalization considered the future direction
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesDemystifying Transformer: A Word-Continuation Function, Deconstructed
Understand Transformer through the lens of word continuation. Breaking down language generation into Embedding, Transformer Block, and Probability output modules for intuitive understanding.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.