Meta Muse Spark Technical Deep Dive: How Three-Dimensional Scaling Achieves 10x Compute Reduction
Meta's Muse Spark achieves 10x+ pre-training efficiency gains, targeting "Personal Superintelligence."
Meta disclosed technical details of its Muse Spark model, which achieves over 10x compute reduction compared to Llama 4 Maverick through overhauling its pre-training stack across model architecture, optimization algorithms, and data curation. The model systematically studies scaling properties across three dimensions—pre-training, reinforcement learning, and test-time inference—with the goal of building "Personal Superintelligence," marking a shift in the large model race from stacking compute to improving efficiency.
Meta recently disclosed the technical details of its latest model, Muse Spark. Built around the ambitious vision of "Personal Superintelligence," the company elaborated on the model's scaling properties across three dimensions: pre-training, reinforcement learning, and test-time inference. Most notably, Muse Spark achieves over an order of magnitude reduction in pre-training compute, demonstrating exceptional engineering capability.
Muse Spark Pre-training Efficiency: Over 10x Compute Savings Compared to Llama 4 Maverick
Over the past nine months, the Meta team has completely overhauled its pre-training technology stack across three core directions:
- Model architecture improvements: Optimized the underlying network structure design
- Optimization algorithm upgrades: Improved convergence efficiency during training
- Data curation optimization: More refined selection and organization of training data
The shared goal of these three improvements is: extracting more model capability from every unit of compute.
Notably, Data Curation has been increasingly proven by research to be a critical variable affecting model capability, rather than merely a supplementary measure. Early large model research tended toward "more data is better," but the success of Microsoft's Phi series broke this assumption—Phi-1 surpassed much larger competitors on coding tasks with fewer than 7B parameters and high-quality synthetic data. Core data curation techniques include perplexity-based quality filtering, MinHash LSH deduplication algorithms, domain ratio optimization, and using strong models to score data quality. High-quality data enables models to learn more from fewer tokens, directly reducing the total compute needed to reach target performance. Meta listing data curation as one of three pillars indicates they may have achieved a systematic breakthrough in data quality, rather than relying solely on architectural innovation.
To rigorously validate the effectiveness of the new approach, the team employed the classic Scaling Law methodology—first fitting scaling law curves on a series of small models, then comparing the training FLOPs (floating-point operations) required to reach specific performance levels.
Scaling Laws are a core theoretical tool in modern large model research, first systematically proposed by Kaplan et al. at OpenAI in 2020. The key finding is that model performance follows a power law relationship with parameter count, data volume, and compute. DeepMind's 2022 Chinchilla paper further refined this theory, pointing out that the industry generally suffered from "models too large, data too scarce" training imbalances, and proposed better formulas for parameter-to-data ratios. By comparing "FLOPs required to reach equivalent performance," one can eliminate interference from model size differences and directly measure improvements in training efficiency itself—a rigorous and widely recognized benchmarking method.
FLOPs (floating-point operations) is the standard unit for measuring deep learning training compute, typically approximated by the empirical formula "6 × parameter count × token count." Using FLOPs rather than "GPU hours" or "training time" as an efficiency metric is because it's hardware-agnostic, enabling fairer cross-generational and cross-vendor comparisons.
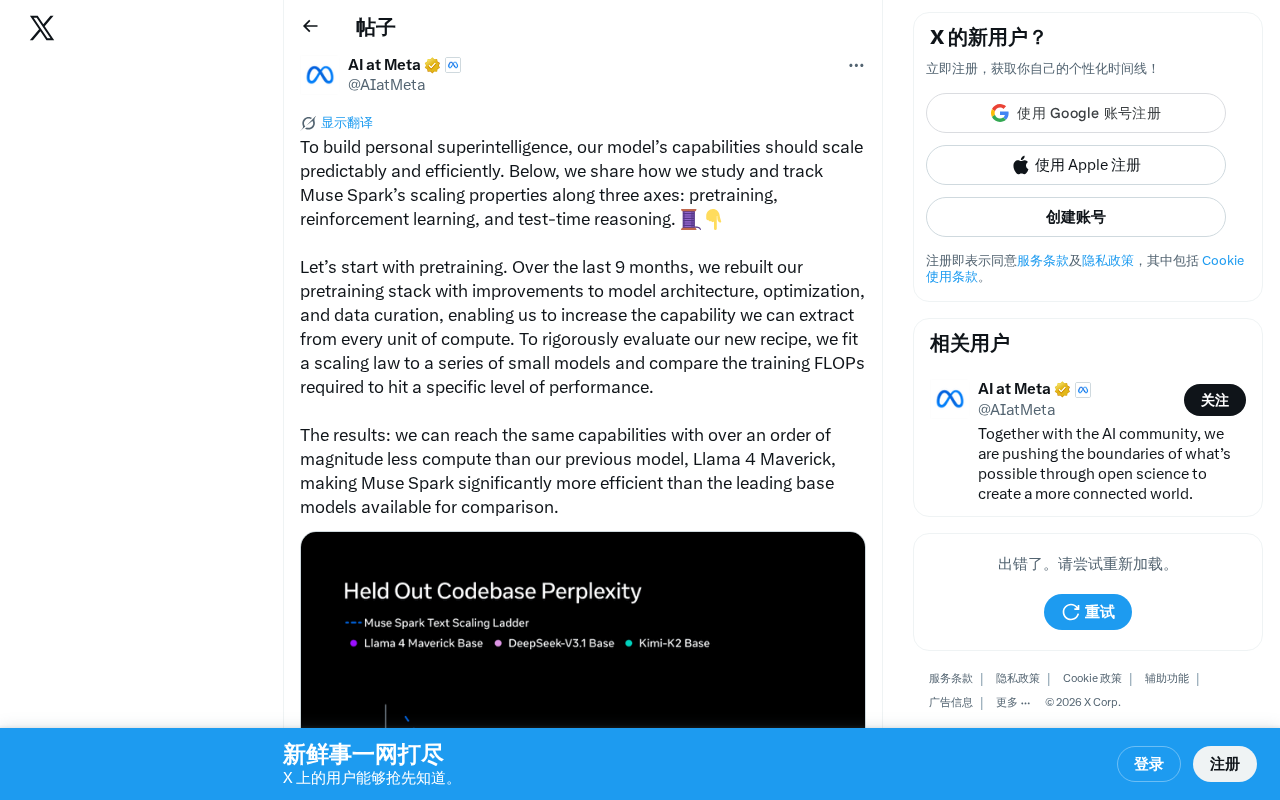
The results are quite striking: The compute required for Muse Spark to reach the same capability level is reduced by over an order of magnitude (more than 10x) compared to the previous generation model Llama 4 Maverick. This means that with the same compute budget, Muse Spark can achieve far superior capabilities compared to its predecessor, or equivalently, reaching the same performance requires only one-tenth of the training cost. Achieving over 10x compression at the FLOPs level typically requires synergistic improvements across architecture, optimizer, and data quality—a single factor alone rarely produces gains of this magnitude.
Meta also specifically noted that this efficiency is not only superior to their own previous generation but also "significantly better than comparable leading foundation models," implying their pre-training efficiency is now at the industry frontier.
Three-Dimensional Scaling Strategy: Muse Spark's Complete Capability Enhancement Framework
Meta has planned three scaling dimensions for Muse Spark, forming a comprehensive capability enhancement framework:
Pre-training Scaling: Establishing Foundational Capabilities
This is the source of the model's foundational capabilities. Through the aforementioned improvements in architecture, optimization, and data, Meta has demonstrated significant breakthroughs in this dimension. Improved pre-training efficiency means the team can train stronger base models with the same resources, or iterate rapidly at lower cost.
Reinforcement Learning Scaling: Fine-grained Capability Alignment
Using reinforcement learning to further align and enhance model capabilities after pre-training has become the standard paradigm in current large model development. The most representative form of Reinforcement Learning (RL) in large models is RLHF (Reinforcement Learning from Human Feedback), first deployed at scale by OpenAI in InstructGPT and ChatGPT: first collecting human preference annotations on model outputs to train a Reward Model that simulates human judgment; then optimizing the language model using algorithms like PPO (Proximal Policy Optimization) so its outputs receive higher reward scores. In recent years, models like DeepSeek-R1 have further explored pure RL training paths, proving that RL can not only align model behavior but also elicit emergent capabilities such as spontaneous chains of reasoning. Meta studying RL as an independent scaling dimension means they are systematically exploring the relationship between "how much capability gain results from investing more RL compute resources," potentially developing predictive formulas similar to those for the RL stage, indicating they have a systematic methodology for tracking and predicting capability growth in this phase.
Test-Time Inference Scaling: Unleashing Stronger Intelligence On Demand
This has been one of the hottest directions in the industry over the past year. Test-Time Compute Scaling ignited industry discussion with the release of OpenAI's o1 series models. The core idea is: investing more computational resources during inference, letting the model "think longer," thereby improving performance on complex tasks without updating model weights. Specific implementation paths include: Chain-of-Thought prompting that has models reason step-by-step rather than outputting answers directly; Best-of-N sampling that generates multiple candidate answers and selects the best; Monte Carlo Tree Search (MCTS) for systematic exploration of the reasoning space; and Process Reward Models that score intermediate reasoning steps to guide search direction. DeepMind's research has shown that test-time compute and training-time compute are interchangeable on certain tasks—meaning "spending 10x more compute at inference" can sometimes be equivalent to "spending several times more compute during training." Meta incorporating this into their scaling framework indicates that Muse Spark likely possesses strong inference-time compute capabilities, particularly effective for complex tasks in mathematics, programming, and scientific reasoning.
What Meta's "Personal Superintelligence" Vision Means
Meta positions Muse Spark's goal as "Personal Superintelligence"—a framing worth noting. It suggests Meta's AI strategy goes beyond building general-purpose large models to constructing super-powerful AI assistants that deeply serve individual users. This aligns perfectly with Meta's massive social platform user base—if every user could have a "superintelligence"-level AI companion, the commercial potential is enormous.
From a technical roadmap perspective, the three-dimensional scaling framework also reflects Meta's pragmatic approach: pre-training provides foundational capabilities, RL achieves fine-grained alignment, and test-time inference releases stronger intelligence on demand during actual use. This layered, progressive design ensures efficiency while leaving room for continuous capability improvement.
Implications of Muse Spark for the AI Industry
Efficiency matters more than scale. The Muse Spark case once again proves that in the large model race, simply throwing more compute is no longer the optimal solution. Through synergistic improvements in architectural innovation, optimization advances, and data engineering, it's possible to "do more with less." This cannot be overlooked for the sustainable development of the entire industry—as training costs continue to decline, the pace of AI adoption will accelerate further.
Meta releasing Muse Spark as a closed-source high-efficiency model alongside the open-source Llama series also reflects its dual-track AI strategy accelerating forward.
Key Takeaways
- Muse Spark requires over an order of magnitude less compute than Llama 4 Maverick to reach the same capability level
- Meta overhauled its pre-training technology stack over the past 9 months, covering three major improvements: model architecture, optimization algorithms, and data curation
- Muse Spark systematically studies scaling properties across three dimensions: pre-training, reinforcement learning, and test-time inference
- Meta positions Muse Spark as "Personal Superintelligence," targeting deep service for individual users
- The pre-training efficiency breakthrough signals the large model race is shifting from "stacking compute" to "improving efficiency"
Related articles
New Species Discovered in New York's C…
New Species Discovered in New York's Central Park? Inside the Urban Insect Hunting Project
Scientists set up insect traps in NYC's Central Park and Prospect Park to discover unknown species. With 90% of Earth's species still unnamed, urban biodiversity research is becoming a new trend in ecology.
The Full Story of the Higgs Boson Disc…
The Full Story of the Higgs Boson Discovery: An Insider's Account of the 'God Particle'
A Fermilab physicist's insider account of the Higgs boson discovery: the transatlantic race with CERN, behind-the-scenes details of the 2012 announcement, 14 years of verification, and the true origin of the 'God Particle' name.
 Research
ResearchSciMDR: How a 7B Small Model Rivals GPT-5 in Scientific Reasoning
Yale and other institutions introduce SciMDR, a two-stage data synthesis pipeline enabling a 7B model to match GPT-5 level performance in scientific literature comprehension.