Minimax M3 vs DeepSeek V4 Hands-On Test: Who Builds a Better Dino Run Game?

Same prompt, two models: Minimax M3 outshines DeepSeek V4 in a Dino Run game test thanks to native multimodality.
A Bilibili creator tested Minimax M3 and DeepSeek V4 Pro by having both generate a Dino Run game from the same prompt. While DeepSeek produced a functional game, Minimax M3 delivered significantly more polished visuals thanks to its native multimodal architecture. Further tests with chess game screenshot replication confirmed M3's edge in combining code generation with visual asset creation, showcasing the shift toward Agent-based multimodal AI programming.
The Chinese AI model scene has been heating up again recently — Minimax released its new M3 model, claiming top-3 global performance with 1M context support and native multimodality. On the other side, DeepSeek V4 Pro has also been drawing significant attention in developer circles. Between these two top-tier Chinese AI models, which one has stronger code generation capabilities? A Bilibili creator used the exact same prompt to have both models build a "Dino Run" game, and the results were surprisingly different.
From 2024 to 2025, the Chinese LLM landscape went through a shift from the "hundred-model war" to consolidation around a few leaders. DeepSeek rose rapidly through its open-source strategy and extreme cost-efficiency (the training cost of its V3 series was a fraction of comparable models), with innovations like its MoE (Mixture of Experts) architecture and Multi-head Latent Attention drawing global attention. Minimax took a differentiated path — from early voice synthesis (Hailuo AI) to today's native multimodal large model — consistently emphasizing multimodal fusion capabilities. Additionally, Alibaba's Qwen, ByteDance's Doubao, Baidu's ERNIE Bot, and others continue iterating in their respective areas of strength. The focus of competition has shifted from pure benchmark scores to comprehensive real-world performance — spanning code generation, multimodal understanding, Agent capabilities, inference speed, and cost control.
Test Setup: Same Prompt, Minimax M3 vs DeepSeek V4 Head-to-Head
The testing approach was straightforward: prepare a prompt for a Dino Run-style game, feed it simultaneously to Minimax M3 and DeepSeek V4 Pro, and compare their performance across code generation, game visuals, and playability.

On the Minimax side, the Minimax Code platform was used with the M3 model selected. After receiving the prompt, the model automatically breaks down the task, lists a detailed execution plan, completes each step sequentially, and finally packages the entire game code as output. DeepSeek V4 Pro followed a similar workflow — paste the same prompt, select the model, hit run, and wait a few minutes for results.
Both models completed the task within minutes, with no significant difference in speed. The real difference showed up in the quality of the final generated games.
Game Output Comparison: A Clear Gap in Visual Quality
Let's start with the Dino Run game generated by Minimax M3. The first impression upon opening it was — the visuals are remarkably polished. Scenes and characters were generated through AI art, with visual quality far exceeding typical code-generated games. Even more impressive, the game supports randomly generated maps, significantly boosting replayability.
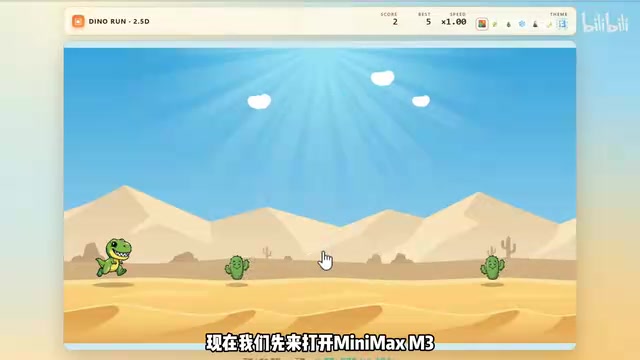
Now for DeepSeek V4 Pro's creation. Overall, the game runs properly and is fully playable, with some sound effects included — basic functionality is solid. But when placed side by side with M3's output, the visual polish falls noticeably short.
The core reason for this gap lies in their architectural differences. Minimax M3 has native multimodal capabilities — vision and text are processed within the same parameter space. This means that when generating a game, it can not only write code but also simultaneously invoke image generation capabilities to enhance game assets. While DeepSeek V4 Pro has strong coding abilities, it hasn't yet reached the same depth in multimodal fusion.
Native Multimodal refers to an architectural design philosophy that contrasts with "pipeline multimodal" approaches. Traditional multimodal models typically use a modular stitching approach — first using a visual encoder (like CLIP or ViT) to convert images into feature vectors, then feeding those vectors into a language model for processing, with information bottlenecks between modules. Native multimodal, on the other hand, jointly trains text, image, audio, and other modalities within a unified parameter space from the training stage, giving the model cross-modal understanding and generation capabilities at a fundamental level. The advantage of this architecture is smoother information flow between modalities — the model can truly "understand" the relationship between image content and code logic, rather than merely translating image descriptions into text before processing. Google's Gemini series represents this approach, and Minimax M3 follows a similar technical path.
Advanced Test: Replicating a Chess Game from Screenshots to Verify Multimodal Understanding
To further validate M3's multimodal understanding capabilities, the creator conducted a more challenging test — using several screenshots of a chess game to have M3 directly replicate a playable Chinese chess game.

The first version already had basic chess functionality working properly — piece movements and rule validation were all correct. But the visuals were rough; as the creator put it, "it looked like an unfinished apartment."
This is where M3's native multimodal capabilities came into play. By having the model generate a polished chessboard image as reference material and then re-rendering the game interface, the final result was much more refined.

This process demonstrates an important workflow: first use AI to build the functional framework, then use multimodal capabilities to polish the visual experience. This integrated "code + design" capability is something pure text models struggle to achieve.
Analysis: Three Core Advantages of Minimax M3
Based on this hands-on test, Minimax M3's competitiveness is primarily reflected in three areas:
Native Multimodal Fusion
Visual understanding and text generation are processed within the same parameter space — not simple module stitching. This gives it a natural advantage when handling tasks involving images (such as screenshot replication and game asset generation). You can upload a video for it to understand and organize into a document, or use a screenshot to have it replicate a website or game.
Coding Agent Capabilities
It doesn't just generate code snippets — M3 has complete problem decomposition and task planning abilities. When facing complex requirements, it first analyzes the task structure, creates an execution plan, then implements step by step. This Agent-style workflow makes it more stable when handling complete projects.
Coding Agent represents an important evolution of LLMs from "code completion tools" to "autonomous programming assistants." Early code generation models (like Codex and CodeLlama) mainly excelled at completing code snippets based on comments or context but often struggled with complex engineering-level tasks. The core breakthrough of Coding Agents lies in introducing mechanisms like task Planning, Tool Use, and Reflection. After receiving a complex requirement, the model first decomposes the task into multiple sub-steps, creates an execution plan, then implements each sub-task sequentially while checking for errors and auto-fixing along the way. This approach borrows from project management principles in software engineering, enabling AI to handle complete projects involving multiple files and modules. Current representative products include Anthropic's Claude Code, OpenAI's Codex CLI, and AI coding IDEs like Cursor.
Ultra-Long Context Support
The 1M token context window is top-tier among Chinese AI models. For scenarios like game development that require extensive code and resource descriptions, long context means the model can maintain a complete understanding of the entire project within a single conversation, without losing critical information due to context truncation.
The Context Window refers to the maximum number of tokens a large language model can process in a single inference pass. Early GPT-3.5 only supported 4K tokens — roughly 3,000 Chinese characters — causing information truncation with even moderately long documents. With advances in technologies like RoPE positional encoding extension, Ring Attention, and sparse attention, context windows have been continuously expanded. 1M tokens is approximately equivalent to 750,000 Chinese characters or a medium-length novel, meaning the model can fully read and understand the entire contents of a large code repository in a single conversation. For game development scenarios, a complete small game project might contain thousands of lines of code, resource description files, configuration files, and more — long context ensures the model won't produce contradictory output because it "forgot" earlier code. However, it's worth noting that the "effective utilization rate" of the context window (i.e., the model's ability to accurately retrieve and correlate information within long texts) is equally important — raw window length alone doesn't equal actual usability.
A Fair Perspective: DeepSeek V4 Pro Is Far from Weak
To be fair, the game generated by DeepSeek V4 Pro in this test was functionally complete and fully playable — the code quality itself was solid. The gap between the two was primarily in multimodal asset generation, not in pure programming ability.
If your needs involve pure code development, algorithm implementation, backend logic, or other scenarios that don't involve visual assets, DeepSeek V4 Pro remains an extremely strong choice. But if you need a "one-stop" full-stack development experience — from code to design in one go — then Minimax M3's multimodal fusion does provide a more complete solution.
Conclusion: Multimodal AI Coding Is Changing Game Development
Competition among Chinese AI models has evolved from single-dimension text capabilities to a comprehensive battle encompassing multimodal fusion and Agent-style workflows. In this Dino Run game showdown, Minimax M3 demonstrated impressive overall strength through its combination of native multimodality and Coding Agent capabilities. For developers looking to rapidly build small games or replicate web applications using AI, these multimodal coding models are turning "build a game in 5 minutes" from a gimmick into reality.
From a broader perspective, AI coding tools are evolving through three stages: The first stage was code completion (like early GitHub Copilot), where AI could only complete a few lines at the cursor position. The second stage was conversational code generation (like ChatGPT and Claude), where users describe requirements in natural language and AI generates complete code segments. The third stage — which we're now entering — is the era of Agent-based multimodal programming, where AI can not only write code but also understand design mockups, generate visual assets, and autonomously debug and iterate. This comparison between Minimax M3 and DeepSeek V4 Pro perfectly illustrates the critical transition point from the second to the third stage — pure text-based coding capabilities have largely matured, and multimodal fusion with Agent-style workflows are becoming the next competitive frontier.
Related articles

What Is Google WebMCP? A Deep Dive into the New Standard for AI Agents to Directly Invoke Web Functionality
A deep dive into Google WebMCP (Web Model Context Protocol): how it works, its technical implementation, and use cases. Learn how WebMCP lets AI Agents directly invoke web tools.
AI Can't Kill Old-School Programming: Why Fundamentals Are Still a Developer's Moat
Vibe Coding is trending, but can it replace solid fundamentals? A deep analysis of why core principles, systems thinking, and knowledge frameworks remain a developer's moat in the AI era.
ZeroStack: An In-Depth Look at the Rust-Based Minimalist Coding Agent That Uses Only 16MB of RAM
In-depth review of ZeroStack, a Rust-based coding agent using only 16MB RAM. Analyzing its file I/O, multi-model support, permission controls, and ideal use cases.