Multi-Agent Automated Coding Framework: A Deep Dive into Zero-Intervention Project Delivery
Multi-Agent Automated Coding Framework…
Multi-AI Agent collaboration framework: file-driven state machine enables fully automated coding pipeline
This article presents a multi-Agent automated coding framework that splits AI instances by context boundaries into roles like Designer, Coder, and Validator. Using files as state machines, a scheduler for orchestration, and strict prompts for constraints, it achieves a fully automated pipeline from requirement decomposition to code delivery. Using only Gemini 2.5 as a single model, it completed a full AI Werewolf game project in 3.5 hours with zero human intervention, validating the feasibility of engineering-driven multi-AI orchestration.
Introduction: AI Teams Writing Code Autonomously Is No Longer Just a Concept
A complete AI Werewolf game project—including a WebSocket server, game engine, AI player integration, and visualization interface—was collaboratively built by 4 AI Agents in 3.5 hours with zero human intervention. What's even more surprising is that the entire process used only Gemini 2.5 as the single model, without relying on Claude Opus, GPT-5, or any other premium models.
The core idea behind this framework isn't complicated: use files as a state machine, a scheduler for orchestration, and strict prompts for constraints, enabling multiple AI instances to collaborate like a human team with clear division of labor. Let's dive deep into its design principles and implementation details.
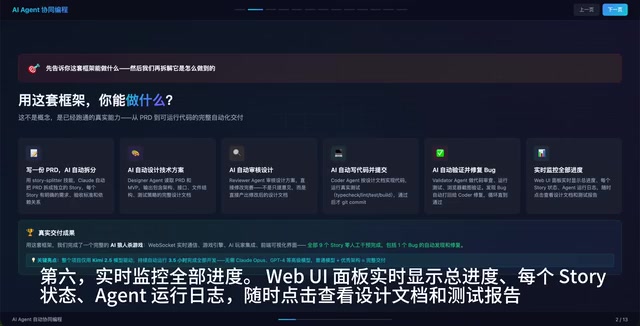
Six Core Capabilities: A Fully Automated Pipeline from Requirements to Delivery
This multi-Agent coding framework covers the complete software development lifecycle, with each stage handled by a dedicated Agent. It's worth noting that "Agent" here doesn't refer to some special program—it's simply an LLM call instance carrying a dedicated system prompt and independent context window. This aligns closely with the microservices architecture philosophy where each service does one thing well.
First, automatic requirement decomposition. You only need to write a PRD (Product Requirements Document), and the AI uses the Story Sweeper skill to automatically break the PRD into independent Stories. The term "Story" here comes from the "User Story" concept in Agile methodology, typically following the format "As a [role], I want [feature], so that [value]," accompanied by clear Acceptance Criteria. The process of automatically decomposing a PRD into Stories essentially simulates an Agile team's Backlog Refinement meeting, enabling the AI system to manage tasks at the same granularity familiar to engineering teams. Each Story includes clear requirement descriptions, acceptance criteria, and dependencies.
Second, automatic technical design. The Designer Agent reads the PRD and MVP reference code, then outputs a complete design document covering architecture design, interface definitions, file structure, and testing strategy.
Third, automatic design review and revision. The Reviewer Agent doesn't simply provide feedback—it directly reviews the design and outputs a revised design document (Design V2).
Fourth, automatic coding and commits. The Coder Agent implements code according to the design document, runs real Type Check, Lint, Test, and Build processes, and only executes a Git Commit after everything passes.
Fifth, automatic verification and bug fixing. The Validator Agent performs code review, runs tests, and even takes browser screenshots for verification. When bugs are found, it automatically sends the work back to the Coder for fixes, looping until everything passes.
Sixth, real-time progress monitoring. A WebUI panel displays overall progress, the status of each Story, and Agent runtime logs in real time, with the ability to click through to view design documents and test reports.
Core Design: Why Multi-Agent Is Essential
The Fatal Flaws of Single-Agent Approaches
Many people's first reaction is: why not just use one Claude to handle everything? There's a key insight here—Claude's official documentation explicitly states that multi-agent decomposition should be based on context boundaries, not on human social roles.
Understanding this requires first grasping the fundamental limitations of the context window. The context window is the maximum number of tokens a large language model can process at once. Even models like Gemini 2.5 with million-token contexts face "attention dilution" in long, complex tasks—as context grows, the model's attention to earlier information significantly decreases, leading to output quality degradation and inconsistencies. This is the fundamental bottleneck preventing a single Agent from handling complete software projects, not a limitation of compute power or intelligence.
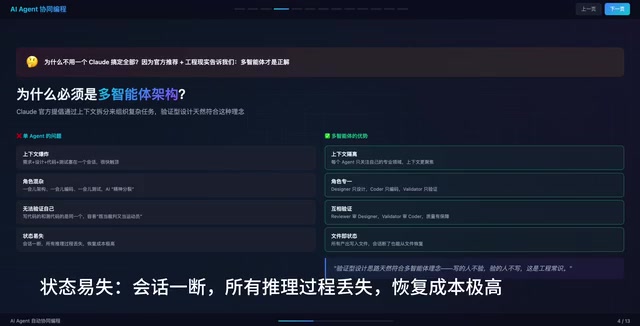
Single-Agent approaches face four major problems:
- Context explosion: Requirements, design, code, and tests all crammed into one session quickly hit the ceiling
- Role confusion: Switching between architecture, coding, and testing causes the AI to become "schizophrenic"
- Inability to self-verify: The same Agent writing and testing code is both referee and player
- State loss: When a session breaks, all reasoning processes are lost, with extremely high recovery costs
Core Advantages of Multi-Agent Collaboration
Multi-Agent Systems (MAS) originated in the field of distributed artificial intelligence, with the core idea of decomposing complex tasks among multiple autonomous agents for collaborative completion. In the era of large language models, this concept has been reinterpreted: each Agent has a dedicated system prompt, independent context window, and tool-calling permissions, with clear responsibility boundaries that prevent mutual interference.
Multi-agent architecture naturally solves the above problems: Context isolation ensures each Agent focuses only on its professional domain, keeping context lean and efficient; Role specialization ensures Designers only design, Coders only code, and Validators only verify; Mutual verification forms a quality assurance loop; Files as state means all outputs are written to files, enabling recovery even after session interruptions.
This design philosophy of "those who write don't verify, those who verify don't write" is essentially common sense in software engineering.
State Machine and Communication: File-Driven Collaboration
The Complete Lifecycle of a Story
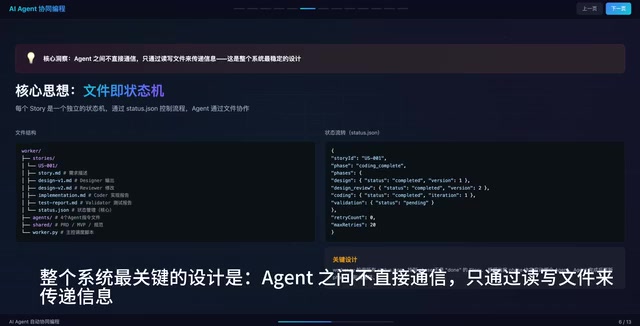
The most critical design decision in the entire system is: Agents don't communicate directly—they pass information only by reading and writing files. This file state machine design has a classic counterpart in distributed systems—the "Blackboard System" architectural pattern. In a blackboard system, various expert modules collaborate by reading from and writing to a shared "blackboard" data structure, rather than calling each other directly. Using the file system as state storage, compared to in-memory queues or direct API calls, offers maximum observability and persistence: every intermediate state is saved as a human-readable Markdown file, state isn't lost after process crashes, and it's easy to debug, audit, and resume from breakpoints.
The complete flow of a Story is as follows:
- Story created → Enters the pending queue
- Designer reads Story + PRD + MVP → Outputs
design_v1.md - Reviewer reviews
design_v1.md→ Directly modifies and outputsdesign_v2.md - Coder reads
design_v2.md→ Implements code, outputsimplementation.md - Validator reads
implementation.md→ Tests and verifies, outputstest_report.md
Automatic Rollback on Validation Failure
This is the most valuable part of the entire system—errors can be automatically discovered, recorded, and fixed. This mechanism is conceptually aligned with "Quality Gates" in CI/CD pipelines: in traditional CI/CD, code commits trigger automated tests, and failures block merging. This framework internalizes that mechanism as an inter-Agent collaboration protocol. The Validator acts as an automated Code Reviewer and QA Engineer, and its output test_report.md is similar to a GitHub Actions failure log, providing precise fix guidance for the Coder.
The specific flow is:
- When the Validator finds a bug, it rolls back the Story status from "Coding Complete" to "Coding"
- Retry Count increments by 1, recording the number of attempts
- A detailed
test_report.mdis written, including failure reasons - The Coder reads the test report, locates the issue, and fixes the code
- After fixing, it re-enters Validator verification
This closed loop ensures code quality without any human intervention.
How the Scheduler Works
The main controller (Worker) polls state files to decide which Agent to launch:
- Scans all Story statuses, finding Stories whose Phase isn't "Done"
- Launches the corresponding Agent based on the current Phase
- After the Agent completes, it updates the Phase, forming a closed loop
Every Agent has mandatory pre-checks on startup: reading the Worker State to confirm the current Agent matches, verifying the Phase is correct, and checking that all required input files exist—missing any one causes a halt.
The Critical Role of MVP: Giving AI a Reference Anchor
Why is providing MVP (Minimum Viable Product) code essential? Because AI needs reference implementations to reduce hallucinations. Design without an MVP is building castles in the air.
This design has deep cognitive science foundations. When large language models generate code without concrete references, they tend to produce "hallucinations" such as random technology stack choices and inconsistent interface styles. Providing MVP code establishes a constraint space for the model, compressing infinite possible solutions into a subset consistent with the existing codebase's style. This is highly similar to the principle of Few-Shot Prompting: guiding model output to match expected formats and styles through concrete examples, rather than relying on the model's free improvisation. From a cognitive science perspective, this is a positive application of the "Anchoring Effect."
The MVP isn't the final product—it's demonstration code for the Agents, like legacy project code that new employees review during onboarding. The MVP is placed in a shared directory and referenced by all Agents. This design dramatically improves the accuracy and consistency of AI output.
Real-World Results: Visual Monitoring and Automated Delivery
After launching the Worker, the system automatically opens a WebUI monitoring panel with three core features:
- Progress ring: Real-time completion percentage for an intuitive overview of overall progress
- Story list: Each Story's current phase and file outputs at a glance
- Work logs: Real-time scrolling display of Worker and Agent runtime logs
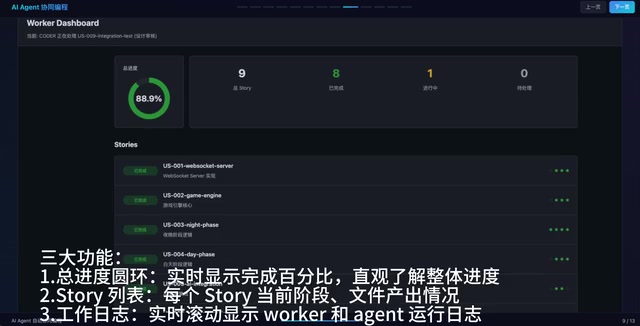
From the actual runtime screenshots, you can see that most of the 9 Stories are complete, with the Coder processing the final Story. Clicking any Story reveals the complete output chain from requirements to testing, with every step fully traceable.
The delivered AI Werewolf game supports a standard 9-player game (3 Werewolves, Seer, Witch, Hunter, 3 Villagers), with 9 independent AI Agents autonomously reasoning, speaking, and voting. Game state is pushed in real-time via WebSocket, and the frontend visualizes the complete game progression.
Conclusion: Three Steps to Launch Your AI Development Team
This multi-Agent automated coding framework has an extremely low barrier to entry:
- Decompose the PRD into Stories
- Launch the Worker
- Open the monitoring panel
Then you can go grab a coffee.
The core insight of this approach is: Don't try to make one AI do everything—instead, use engineering thinking to orchestrate multiple AI instances. Files as state machine, scheduler for orchestration, strict prompts for constraints—these three elements combined enable even inexpensive models to produce high-quality complete projects. The engineering logic behind this is consistent with distributed systems design, Agile methodology, and CI/CD pipelines—the only difference is that the executors have changed from human engineers to AI Agents. This isn't just a technical solution; it's a software engineering paradigm for the AI era.
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.