Multi-Model Unified Orchestration Framework: Runtime Dynamic Switching Across Eight AI Services in Practice
A unified framework for runtime dynamic switching across eight AI text and voice services.
This article analyzes a runtime AI chatbot integrator that unifies eight AI services — including OpenAI, Claude, DeepSeek, Gemini, and Grok for text, plus 11Labs, Google TTS, and Azure Speech for voice — into a single orchestration framework. It covers the adapter pattern architecture, streaming TTS for reduced perceived latency, multi-model performance comparisons, and practical guidance on API key management, cost monitoring, and data compliance.
Overview: One Integrator to Orchestrate Eight AI Services
In AI application development, developers often need to interface with multiple large language models and voice services simultaneously. Text models like OpenAI, Claude, DeepSeek, Gemini, and Grok each have their strengths, while services like 11Labs, Google TTS, and Azure Speech each offer unique capabilities in speech synthesis. How to flexibly switch between these services at runtime while ensuring low latency and high-quality output is an engineering challenge worth exploring in depth.
A recently emerged "Runtime AI Chatbot Integrator" demo project showcases how to unify all eight AI services into a single framework, enabling dynamic switching and real-time voice generation. This article analyzes the project from three dimensions: architecture design, latency testing, and practical application value.



Core Architecture: Design Philosophy Behind Runtime Dynamic Switching
Unified Interface Abstraction Layer
The integrator's core design philosophy is to build a unified abstraction layer on top of multiple AI services. Whether the underlying call goes to OpenAI's GPT series, Anthropic's Claude, or domestic models like DeepSeek, the upper-layer application code requires no modifications. This design pattern is known as the "Adapter Pattern" in software engineering — it encapsulates the differences between various APIs within their respective adapters while exposing a consistent interface externally.
The Adapter Pattern is one of the structural patterns in the GoF design patterns, with the core idea of converting one class's interface into another interface that clients expect. In the context of AI service integration, this means mapping completely different request/response formats — OpenAI's Chat Completions API, Anthropic's Messages API, Google's GenerativeAI API — into a standardized internal interface. This approach is also known as the "Anti-Corruption Layer" in cloud-native architecture, originating from Domain-Driven Design (DDD) concepts, aimed at preventing the complexity and instability of external systems from infiltrating core business logic. In practice, each adapter typically needs to handle differences in authentication methods (Bearer Token vs API Key vs OAuth), streaming response protocols (SSE vs WebSocket vs gRPC stream), and token counting approaches.
The advantages of this architecture include:
- Flexibility: Dynamically select the most suitable model at runtime based on task type, cost budget, or response speed requirements
- Fault tolerance: Automatically switch to fallback services when a particular service experiences failures
- Extensibility: Adding new AI services only requires writing the corresponding adapter without modifying core logic
Multi-Engine Support for Speech Synthesis
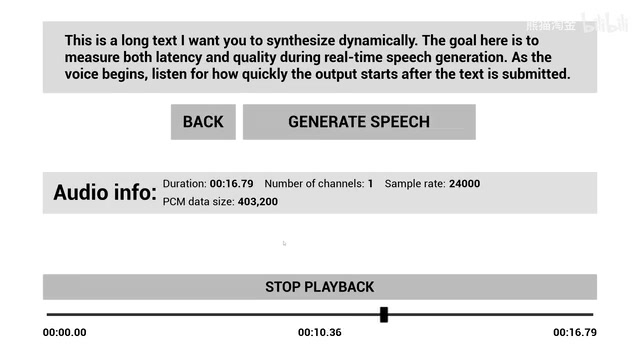
On the speech synthesis side, the project integrates three major services simultaneously: 11Labs, Google TTS, and Azure Speech. The demo pays particular attention to a critical metric — Time to First Byte (TTFB) — the time interval between text submission and the start of audio playback.
Time to First Byte in speech synthesis contexts differs from traditional web performance metrics. In the TTS context, it refers to the time between when the API receives text input and when it returns the first playable audio data chunk. This metric is critical because natural pauses in human conversation typically range from 200-500 milliseconds — if TTS TTFB exceeds this threshold, users will noticeably perceive the unnatural feeling of "the machine is thinking." Modern TTS services typically employ chunked synthesis strategies: splitting long text into sentences or semantic units, synthesizing the first segment and returning it immediately, while subsequent segments are generated in parallel during playback. This pipeline-style processing ensures that even when total synthesis time is long, the perceived latency is only the generation time of the first audio chunk.
The demo uses a relatively long test text for dynamic synthesis, aiming to measure both latency and quality dimensions simultaneously. In real-time voice generation scenarios, user experience largely depends on how quickly voice output begins. If latency is too high, the natural fluency of conversation breaks down.
Balancing Latency and Quality: Multi-Model Testing Analysis
Text Model Response Comparison
Different large language models exhibit significant differences in response speed:
- OpenAI GPT Series: With mature infrastructure, it typically provides stable low-latency responses. Its globally distributed deployment and inference optimization techniques (such as speculative decoding and KV cache optimization) give it significant advantages in latency stability
- Claude: Anthropic uses Constitutional AI training methods, excelling in long-text understanding and generation with support for 200K token ultra-long context windows, though first-token latency may be slightly higher
- DeepSeek: Using a Mixture of Experts (MoE) architecture, it significantly reduces inference costs while maintaining high performance, offering clear cost advantages in Chinese-language scenarios as a representative domestic model
- Gemini: Google natively supports multimodal input (text, image, audio, video), providing differentiated advantages in scenarios requiring cross-modal understanding
- Grok: xAI's product, deeply integrated with X platform real-time data, with unique positioning in real-time information retrieval and time-sensitive content
The integrator's value lies in allowing developers to choose the optimal solution for different scenarios rather than being locked into a single service provider.
Streaming Speech Synthesis Reduces Perceived Latency
Streaming TTS, prominently demonstrated in the project, is the key technology for reducing perceived latency. Traditional approaches require waiting for the entire text to be fully synthesized before playback, while streaming processing allows simultaneous synthesis and playback, dramatically reducing user wait time.
Streaming speech synthesis implementation relies on several key technical components. First is the text segmentation strategy: the system needs to split input text into the smallest independently synthesizable units while preserving semantic integrity — segments that are too short cause prosody breaks, while segments that are too long increase first-segment latency. Second is audio encoding format selection: streaming scenarios typically use formats supporting frame-level decoding like Opus or MP3, rather than WAV format which requires a complete file header. Third is buffer management: the client needs to maintain a playback buffer to ensure playback continuity during network jitter. In cascaded LLM+TTS scenarios, there's an additional optimization opportunity — piping the LLM's streaming token output directly to TTS input, achieving "synthesize speech while generating text" dual-streaming processing, which can reduce end-to-end latency to near pure LLM response latency levels.
11Labs typically leads in voice naturalness, but its API latency may be higher than Azure Speech Service. Google TTS has advantages in multilingual support. The integrator allows developers to flexibly choose between these services based on specific needs.
Practical Application Scenarios and Development Recommendations
Applicable Scenarios
This type of multi-model integration solution is particularly suitable for:
- Intelligent customer service systems: Dynamically select models based on question complexity — use lightweight models for simple questions to reduce costs, and high-end models for complex questions to ensure quality
- Multilingual voice assistants: Use the TTS engine best suited for each language
- A/B testing platforms: Compare actual performance of different models in production environments
Issues Developers Should Watch For
When implementing in practice, developers should pay attention to the following:
-
API key management: Interfacing with eight services simultaneously means managing a large number of authentication credentials — using a key management service is recommended. Industry best practices include using dedicated Key Management Services (KMS) such as HashiCorp Vault, AWS Secrets Manager, or Azure Key Vault for centralized storage, automatic rotation, and access auditing. At the application level, avoid hardcoding API keys or storing them in environment variables (especially in containerized deployment scenarios), instead dynamically retrieving them from KMS at runtime. Each AI service's API key should follow the principle of least privilege, using independent key sets for different environments (development, testing, production), and setting usage limits to prevent abuse after key leakage.
-
Cost monitoring: Different services have vastly different billing models, requiring a unified usage monitoring system. For example, OpenAI charges separately for input/output tokens, 11Labs charges by character count, and Azure Speech charges by audio duration — these heterogeneous billing dimensions need to be normalized into a unified cost metric.
-
Error handling: Each service has different error codes and retry strategies, requiring unified handling at the adapter layer. Common strategies include exponential backoff retry, Circuit Breaker pattern, and graceful degradation to fallback services.
-
Data compliance: Different service providers have different data processing policies, requiring special attention when handling sensitive data. For example, some services may use user input for model training, while certain industry regulations (such as GDPR, China's Data Security Law) impose strict restrictions on cross-border data transfer — service selection requires evaluating data residency locations and processing terms.
Conclusion
The Runtime AI Chatbot Integrator represents a pragmatic engineering approach: rather than betting on a single AI service provider, build a flexible multi-model orchestration framework. As competition in the AI services market intensifies, each provider's areas of strength and pricing strategies are changing rapidly — having such an integration layer provides developers with maximum flexibility and bargaining power.
From a broader perspective, this multi-model integration architecture also reflects the trend toward commoditization of the AI infrastructure layer. When underlying model capabilities become homogenized, the real competitive advantage shifts to the Orchestration Layer — how to intelligently select, combine, and schedule these model services to meet specific business needs with optimal cost efficiency.
For development teams building AI applications, this project provides an excellent reference architecture. Even without using the project directly, its design principles — unified abstraction, runtime switching, streaming processing — are worth incorporating into your own projects.
Key Takeaways
Related articles
NestJS + LangChain: A Practical Guide for Frontend Engineers Transitioning to AI Full-Stack Architecture
How can frontend engineers transition to AI full-stack? This guide covers NestJS + LangChain, TypeScript fundamentals, AI Agent development, local model deployment, and cross-language architecture skills.
Building a Complete Mini Program with Codex: A Full-Process Walkthrough from Zero to Launch
A detailed walkthrough of building a complete WeChat Mini Program from scratch using OpenAI Codex, covering seven image tool features, membership system, WeChat Pay integration, and AI-assisted development strategies.
OpenAI Codex Deep Dive: The AI Develop…
OpenAI Codex Deep Dive: The AI Development Tool That Makes Programming Feel Like Flying
Deep dive into how OpenAI Codex redefines programming. From real developer feedback to the Time to Fly project, analyzing Codex's strengths in code generation, context understanding, and the AI coding tool competitive landscape.