Open-Source Models Keep Throwing Errors in Your Code? The Problem Might Be the Framework
Commander Code optimizes the framework layer to unlock open-source models' true coding potential.
Open-source models like DeepSeek and Kimi are powerful but often fail in coding agents — not because of model limitations, but due to framework incompatibilities. Commander Code addresses this with cache routing optimization that cuts latency to under 1 second, automatic tool call repair, and a continuous learning system called Taste that adapts to your coding style. Internal benchmarks show DeepSeek V4 Pro beating Claude Opus on tool-heavy tasks, proving that the right framework can make open-source models truly competitive for real-world software development.
It's Not That Open-Source Models Can't Code — The Framework Hasn't Caught Up
DeepSeek, Kimi, Gemini, Qwen, MiniMax… These open-source and domestically developed large language models are becoming both powerful and affordable. But when developers use them in coding agents, they frequently run into tool call failures, code editing errors, and other issues — leading them to conclude: "Open-source models just aren't good enough."
But that might not be the truth. The problem often isn't the model itself — it's the framework that hosts it.
A coding agent is far more than just the model — it also includes file management, tool calling, terminal operations, caching strategies, context handling, and error recovery mechanisms. Together, these components form what's known as the "framework layer": file system read/write management requires the model to understand project structure and make precise file modifications; tool calling protocols need to correctly parse model outputs into actual operations; terminal command execution handles running tests and building projects; and context window management must select the most relevant code snippets within a limited token budget. When the framework isn't optimized for a specific model, output quality suffers significantly — even when the model itself is perfectly capable.
The tool we're looking at today, Commander Code (Coder), is a coding framework specifically optimized for open-source models. Its core philosophy: help DeepSeek, Kimi, and similar models perform closer to their true coding potential.
Design Philosophy Differences Among Mainstream AI Coding Frameworks
Today's leading AI coding tools each have different priorities:
- Cursor's cloud-based code experience is built around Claude
- Codex is built around the GPT series
- OpenCode provides broad model access
- Commander Code is specifically optimized for open-source models
The root cause of these differences is that there's no unified industry standard for LLM tool calling (Function Calling / Tool Use). Claude uses Anthropic's tool_use format, the GPT series uses OpenAI's function_calling protocol, and open-source models like DeepSeek and Qwen each have their own tool calling implementations. The differences manifest across multiple dimensions: JSON Schema formats for parameters, handling of parallel multi-tool calls, chunking strategies for tool calls in streaming output, and error state return formats. When you use DeepSeek in a framework optimized for Claude, incompatibility issues can arise at any of these points. Commander Code's approach is to redesign these components from the ground up, ensuring that open-source model outputs are correctly parsed and executed.
Key Technical Optimizations: Cache Routing and Tool Call Repair
According to Commander Code's engineering blog, they've done deep optimization in two critical areas:
Cache Routing Optimization
In traditional approaches, open-source models need to reload context from scratch with each conversation turn, with first-token latency typically at 6–8 seconds. The root cause of this latency relates to the KV Cache (Key-Value Cache) mechanism in LLM inference. In the Transformer architecture, generating each new token requires attention computation over all previous tokens, and KV Cache avoids redundant computation by caching previously computed key-value pairs. In multi-turn conversation scenarios, if the content from previous turns (the "conversation prefix") hasn't changed, the KV Cache can theoretically be reused directly. But in real-world API services, due to load balancing and instance scheduling, requests may be routed to different GPU nodes, causing cache invalidation.
Commander Code optimized the cache routing mechanism to ensure that requests from the same session are routed to the same inference node holding the hot cache, allowing the model to retain "hot conversation prefixes" across turns. This brings first-token latency for cached turns down to under 1 second. For programming tasks that require frequent iteration, this improvement is very noticeable — a developer might go through dozens of conversation turns in a single coding session, and saving 5–7 seconds per turn means a significant boost in overall efficiency.
Automatic Tool Call Repair
When a model outputs an incorrect tool call (e.g., wrong parameter format, incorrect file path), Commander Code doesn't let a single bad call derail the entire task. Instead, it includes an automatic repair mechanism. The model weights haven't changed, but the framework stops wasting the model's compute — that's the key insight. Framework-level auto-repair may include strategies such as: fault-tolerant parsing of incomplete JSON output, fuzzy matching and auto-correction of file paths, and automatic retries with error context appended when tool calls fail.
According to their internal evaluation data (note: these are official internal results, not independent benchmarks):
- DeepSeek V4 Pro beat Claude Opus, winning 6 out of 10 times on high-difficulty tool-dependent tasks, scoring 4.7 vs. the opponent's lower score
- Kimi K2 achieved a 5 out of 10 win rate, nearly reaching parity
Live Demo: Coding Performance in a Real Project
The video author didn't test with an empty Hello World project — instead, they chose an existing web application with components, API routes, and tests.
The test task was a real feature request: Add a save filters feature to the issues page, with specific requirements including:
- Follow existing component patterns
- Persist filter criteria locally
- Add tests where the existing test structure supports them
- Run relevant checks
- Don't introduce new UI libraries or modify unrelated files
Using DeepSeek V4 Pro as the core model, the model worked continuously through the loop — reading the repository, finding the issues page, making a plan, editing files, running tests, and fixing failed checks. The final diff comparison showed that the model reused existing patterns, made accurately scoped changes, delivered working functionality, and passed all tests.
This is more convincing than benchmark screenshots — an affordable open-source model completed real work in a real codebase.
Taste: A Personalized Coding System Based on Continuous Reinforcement Learning
One noteworthy feature in Commander Code is called Taste — a continuous reinforcement learning system:
- It learns from your accept, reject, and edit signals in every interaction
- It gradually understands your coding preferences and conventions
- Future sessions automatically follow your style — no need to write rules or maintain prompts
It's worth noting that Taste's "continuous reinforcement learning" is fundamentally different from RLHF (Reinforcement Learning from Human Feedback) used during model training. RLHF happens during the model training phase, using large amounts of labeled data to train a reward model, then optimizing model weights with algorithms like PPO — it's an offline, global process. Taste's learning happens at inference time. It doesn't modify model weights; instead, it records user behavioral signals, builds a personalized preference profile, and injects it as context into prompts for subsequent requests. This approach is closer to a combination of In-Context Learning and Retrieval-Augmented Generation (RAG) — the system retrieves user historical preferences and provides them as additional context to the model, achieving personalized output without changing model parameters.
For example, if you habitually call existing utility functions, only use a specific testing framework, or avoid unnecessary components, Taste learns from these signals. Press Ctrl+T to view preference settings, which are written to a local Taste folder.
Even more interesting, Taste supports publishing and sharing:
- Run
npx taste-lintto validate a Taste package - Run
npx taste-pushwith a package name and Public flag to publish - Others can pull your preference configuration via
npx taste-pull
This means teams can share coding standards, and new members can quickly align with project style. This mechanism essentially makes implicit coding knowledge (personal habits, team conventions) explicit as distributable configuration packages, solving the "style consistency" problem that traditional code style documentation struggles to cover.
Quick Overview of Other Core Features
Commander Code also offers a range of practical features:
- Model command: Freely switch between DeepSeek, Kimi, Gemini, Qwen, MiniMax, Claude, and GPT — compare different models within the same workflow
- CM Mode: The agent inspects and proposes changes before editing — ideal for high-risk refactoring
- Atlas Mode: Run one-shot terminal requests via CMD+P
- Checkpoints & Rollback: CMD+K creates checkpoints; double-tap S or run Rewind to restore code and conversation
- PR Review: Pull review context into the session; the model checks diffs, handles feedback, and fills in missing tests
- MCP Integration: Connect external tools and documentation. MCP (Model Context Protocol) is an open protocol standard proposed by Anthropic in late 2024, designed to establish a unified communication interface between AI models and external tools/data sources. Before MCP, every AI application needed custom integration code for each external tool, creating M×N complexity. MCP reduces this to M+N through a standardized client-server architecture, making it easy for developers to connect database queries, API documentation retrieval, project management tools, and other external services
- IDE Integration: Share VS Code files and selections
Regarding privacy, Commander Code states it does not use code for training or store code snippets, and you can enforce zero-data-retention routing via the command line.
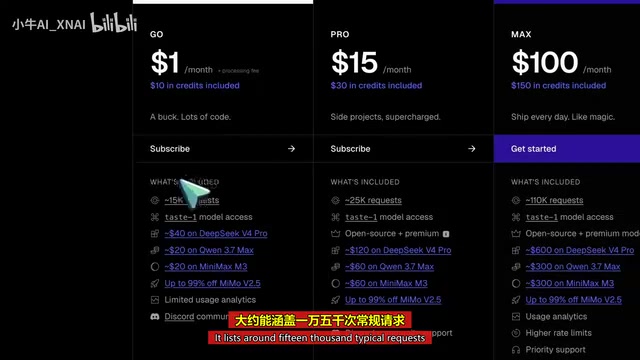
Pricing and Quick Start
The barrier to entry is low: $1 per month plus processing fees, with $10 in open-source model credits — enough to cover roughly 15,000 standard requests. Higher-tier plans include $15 (with $30 in credits), $100 (with $150 in credits), and $200 (with $300 in credits).
Installation is straightforward: make sure Node is installed, then run npm install -g coder, verify with coder version, authorize with coder login, navigate to your project folder, and run coder to get started.
Conclusion: The Model Matters, But So Does the Framework
When DeepSeek, Kimi, Gemini, and Qwen are already powerful enough, paying premium prices for closed-source models for every small feature and bug fix may no longer be necessary. But the prerequisite is having a framework that lets these models truly perform to their potential.
What makes Commander Code compelling isn't that it supports more models — it's that it's becoming a coding agent framework that genuinely enables open-source models to handle real software development work. The complete loop designed around the model — cache routing, tool repair, continuous learning, checkpoint recovery — is what transforms open-source models from "usable" to "actually good."
From a broader perspective, this reflects an important trend in AI engineering: as foundation model capabilities converge, the competitive focus is shifting from "whose model is stronger" to "whose systems engineering is better." The model is the engine, but the framework is the entire car — no matter how powerful the engine, if the chassis, transmission, and suspension can't keep up, the driving experience won't be great. Commander Code's practice demonstrates that with carefully designed framework-level optimizations, open-source models can absolutely match or even surpass closed-source models in real-world programming tasks.
If you're skeptical about open-source models' coding capabilities, try spending $1: pick a real project, run a real task with an open-source model, check the diffs, run the tests, look at the cost — and then decide for yourself.
Related articles

A Gen-Z Woman Making $1.5M/Month: Deconstructing the Growth Methodology Behind AI Apps
Gen-Z indie dev Nicole built 4 hit AI apps earning $1.5M/mo. Deep dive into her industrialized UGC engine, traffic testing system, and minimalist tech stack.
Replit's AI Loops Workflow Explained: Multi-Agent Collaboration Replaces Prompt Engineering
Deep dive into Replit's AI Loops workflow: how orchestrators, parallel agents, and Computer Use Verifiers build automated closed-loop systems through multi-agent collaboration.
Claude Code + Skills: A Practical Guide to AI-Powered Test Case Generation
Learn how to use Claude Code + Skills to auto-generate enterprise-grade test cases. Covers AI Agent vs LLM differences, the four core capabilities, and the complete workflow from requirements to test cases.