Open-Source Multi-Agent Intelligent Diagnostic System: Deep Dive into MCP + RAG + Skill Routing Architecture

Open-source multi-Agent diagnostic system integrating MCP, RAG, and Skill routing architecture
This open-source project, based on a modified OneCall framework, integrates MCP protocol, RAG retrieval augmentation, and Skill routing into a unified intelligent diagnostic system. Its core innovation is a two-stage "select Skill first, then invoke tools" strategy that dramatically reduces Token consumption through lightweight intent classification. The system supports real-time computer diagnostics, RAG multi-turn follow-ups, MCP real-time interaction, and knowledge base management, with a modular architecture that makes it easily extensible.
Project Overview
Recently, an open-source multi-Agent project based on a modified version of OneCall has attracted considerable attention. This project integrates three core capabilities — MCP (Model Context Protocol), RAG (Retrieval-Augmented Generation), and Skill (Skill Routing) — into a unified intelligent diagnostic system capable of performing real-time computer diagnostics, generating reports, and supporting multi-turn follow-up questions with web search.
MCP Protocol Background: MCP is a standardized protocol proposed and open-sourced by Anthropic in late 2024, designed to solve the "last mile" connection problem between large language models and external tools/data sources. Before MCP, every AI application needed custom integration code for different tools, resulting in extremely high maintenance costs. Drawing inspiration from LSP (Language Server Protocol), MCP defines a unified client-server communication specification that allows any MCP-compatible model to plug-and-play with file systems, databases, browsers, and other local or remote resources. Currently, mainstream AI products like Claude and Cursor have already adopted MCP support, and the ecosystem is expanding rapidly.
The project's biggest highlight is its modular architecture design — through the Skill routing mechanism, it first filters for the appropriate skill module, then calls the corresponding tools to execute tasks, dramatically reducing Token consumption and improving response efficiency.
Core Feature Demonstrations
Skill Routing and Intelligent Diagnostics
Skill routing is essentially the "intent dispatch layer" in a multi-Agent system, with its design inspired by the API gateway pattern in microservices architecture. In traditional ReAct (Reasoning + Acting) frameworks, the model needs to face the full set of tool descriptions at every reasoning step. When the number of tools exceeds 20, both Token consumption and the model's tool selection accuracy drop significantly — a phenomenon known as the "Tool Overload" problem. Skill routing introduces a lightweight intent classifier (which can be a rule engine, small model, or vector similarity matching) to first map user intent to a specific Skill domain, then expose only the tool subset within that domain to the main model, compressing the tool selection search space from O(N) to O(K), where K is much smaller than N.
After the system starts, users can input questions in the frontend interface, such as "Why is my computer so slow?", then click "Start Diagnosis". The system goes through the following process:
- Skill Selection: Automatically matches the most appropriate skill module based on question semantics
- Diagnostic Plan Generation: Formulates a retrieval and diagnostic plan based on the selected Skill
- Tool Invocation: Sequentially calls system tools for data collection according to the plan
- Report Generation: Aggregates all diagnostic data to generate a structured diagnostic report
The right panel displays elapsed time and the list of invoked tools in real-time, while the center area shows the live detection status. The final diagnostic report can precisely pinpoint issues — for example, in the demo it accurately identified that the largest resource consumer was a recently launched game.
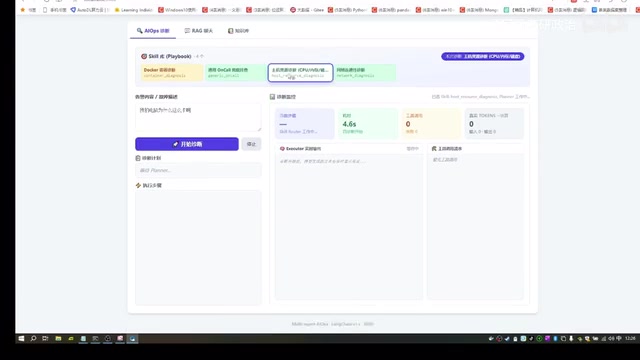
It's worth noting that the system includes a "General OneCall" fallback mechanism: when none of the predefined Skills can match the user's question, the system automatically degrades to general mode for processing, ensuring there's never a non-response situation.
RAG Chat and Multi-Turn Follow-ups
RAG was formally proposed by the Meta AI research team in 2020 in the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Its core idea is to combine "parametric knowledge" (knowledge stored in model weights) with "non-parametric knowledge" (documents in external vector databases), dynamically retrieving relevant passages to inject into context during inference. This breaks through the limitation of model training data cutoff dates and significantly reduces hallucination rates. A typical RAG pipeline includes: document chunking → Embedding vectorization → storage in vector database → similarity retrieval at query time → injecting matched passages into the Prompt.
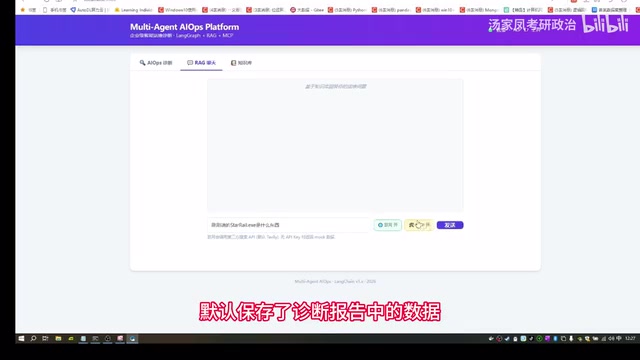
After the diagnostic report is generated, users can switch to RAG Chat Mode for further follow-up questions. This mode is cleverly designed:
- Data from the diagnostic report is automatically saved via Redis cache, serving as the RAG context knowledge base
- User follow-up questions are retrieval-enhanced based on report content, yielding more precise answers
- Supports enabling web search to find supplementary materials related to the report online (search scope is limited to content covered in the report)
Redis's Role in Multi-Turn Conversations: Redis, as an in-memory key-value database, serves as "short-term memory" in AI conversation systems. Compared to the naive approach of stuffing all conversation history into the Prompt, Redis caching offers three major advantages: first, read/write latency is at the microsecond level, so it won't become a response bottleneck; second, it supports TTL (Time-To-Live) settings for automatic cleanup of expired sessions, preventing memory leaks; third, it natively supports distributed deployment, allowing multiple Agent nodes to share the same context state. This project serializes diagnostic reports into Redis, and during RAG retrieval, structured data is pulled directly from cache as the knowledge source. This ensures context coherence across multi-turn follow-ups while avoiding the computational waste of re-executing the diagnostic process.
This "diagnose first, then follow up" interaction pattern ensures context coherence while avoiding the resource waste of re-executing a full diagnosis for every follow-up question.
MCP Interface Real-Time Diagnostics
The system also supports interactive diagnostics with the computer directly through the MCP interface. When users enable the MCP toggle in the chat interface, the system can invoke local tools in real-time via the MCP protocol to obtain current system status. MCP uses standard JSON-RPC 2.0 as its underlying communication format, with tool input/output schemas described through JSON Schema specifications. This allows models to dynamically discover and invoke newly registered tools at runtime without retraining or modifying prompt templates.
In the demo, after closing the game and running diagnostics again through MCP, the system reflects the latest system state in real-time, with the interface clearly displaying the names of tools being called and execution progress.
Knowledge Base Management
File Upload and Vectorization
The system includes a built-in knowledge base upload feature, allowing users to upload custom documents. The upload process involves the following key points:
- Upload requires password verification (currently stored in plaintext, can be changed to encrypted storage later)
- After upload, the system vectorizes document content through Qwen's Embedding model
- Uploaded knowledge is stored as Markdown files, and source information is displayed during RAG Q&A
Embedding Vectorization and Qwen Model: Embedding is the technique of mapping text into high-dimensional dense vectors, where semantically similar texts are closer in vector space — this is the mathematical foundation of RAG retrieval. Alibaba Cloud's Qwen series provides dedicated text-embedding models that support precise vectorization of Chinese semantics, performing excellently on MTEB Chinese benchmarks. Vectorized document chunks are typically stored in vector databases like Faiss, Milvus, or Chroma, with retrieval using cosine similarity or inner product calculations to find the most relevant Top-K passages. This project converts uploaded documents to Markdown before vectorization, preserving document structure information to improve semantic retrieval accuracy, while displaying source filenames in answers to enhance result interpretability.
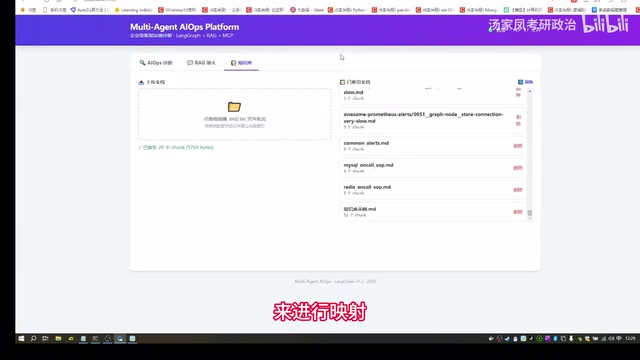
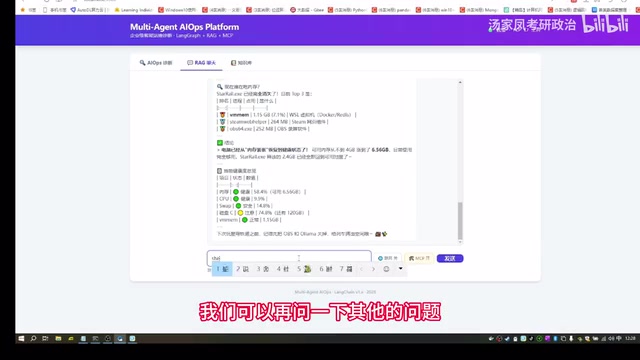
Retrieval Hits and Source Tracing
During RAG Q&A, the system displays retrieval hit rates and parameters, allowing users to clearly see which knowledge base documents were cited in the answer. This "citation tracing" design is an important feature of enterprise-grade RAG systems — it helps users judge answer credibility and facilitates quick identification and correction when knowledge base content is inaccurate. The system also supports deletion management of uploaded knowledge base data to keep the knowledge base clean.
Architecture Advantage Analysis
Token Consumption Optimization Strategy
The most noteworthy architectural design of this project is its "select Skill first, then invoke tools" two-stage strategy. Traditional multi-Agent systems often send all tool descriptions to the LLM at once, resulting in massive Token consumption. Taking GPT-4o as an example, each tool's JSON Schema description averages 200-500 Tokens. When a system integrates 50 tools, the tool description portion alone consumes 10,000 to 25,000 Tokens, severely compressing the context window available for actual reasoning. This project uses the Skill routing layer to perform lightweight intent classification first, then loads the tool set under the corresponding Skill. Based on the demo results, Token consumption is remarkably low.
Modular Design and Extensibility
The entire system is highly modular with clear responsibilities at each layer:
- Skill Layer: Supports custom addition of new skill modules for flexible diagnostic capability expansion
- RAG Layer: Supports custom knowledge base upload and management to enhance Q&A quality
- MCP Layer: Connects various external tools through standard protocols for real-time interaction
- Cache Layer: Redis provides efficient context management to ensure multi-turn conversation coherence
This layered architecture aligns closely with the "Separation of Concerns" principle in software engineering — each layer only needs to focus on its core responsibility, communicating between layers through well-defined interfaces, so that upgrading or replacing a single module won't affect overall system stability.
Conclusion
This open-source project demonstrates a practical approach to organically combining multi-Agent, MCP, RAG, and Skill routing. Its core value lies in achieving precise tool invocation matching through the Skill routing mechanism, combined with RAG's context enhancement and MCP's real-time interaction capabilities, building a feature-complete and resource-efficient intelligent diagnostic system.
For developers looking to learn multi-Agent system architecture design, this project offers valuable insights in Token optimization, module decoupling, and interaction experience. From a broader perspective, this project also represents an important trend in current AI engineering: rather than pursuing a single super-model to solve all problems, it uses carefully designed routing and orchestration mechanisms to let specialized small modules each handle their own responsibilities, finding the optimal balance between cost and capability.
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.