OpenHuman In-Depth Review: Innovation Highlights and Privacy Concerns of a 15,000-Star Desktop AI Assistant
OpenHuman offers innovative UX design but its "local-first" privacy claims don't hold up under scrutiny.
OpenHuman is a 15K-star desktop AI assistant from a Dubai indie developer featuring anthropomorphic interaction, transparent editable memory trees, and 118 integrations. However, its "local-first" privacy claims are misleading—OAuth tokens and LLM calls all route through their backend. While its Tauri+Rust architecture and transparent memory UX offer valuable lessons for AI practitioners, centralized permission risks and early-stage instability make it a project to watch rather than adopt.
A Viral Open-Source Project from a Dubai Indie Developer
A solo developer from Dubai made over 800 code commits in three months to build a desktop AI assistant called OpenHuman. The project quickly amassed 15,000 stars on GitHub and hit #1 on the Product Hunt daily chart. But here's the interesting part: the founder's two self-posted threads on Hacker News received a combined total of just five points, with virtually no discussion.
Product Hunt and Hacker News represent two fundamentally different evaluation systems within the tech ecosystem. Product Hunt's user base consists primarily of product managers, entrepreneurs, and early adopters who focus more on visual presentation, user experience, and commercial potential—and whose voting behavior is more susceptible to social amplification. Hacker News, on the other hand, is dominated by engineers and technical decision-makers, with a community culture that emphasizes technical depth and critical thinking, and a natural resistance to marketing polish. When a product goes viral on Product Hunt but gets a cold reception on Hacker News, it typically means it excels at "perceived value" but hasn't yet earned "technical credibility."
This contrast perfectly reflects a reality in today's AI product landscape: there's a massive temperature gap between the tech community's skepticism and the broader market's enthusiasm.



OpenHuman's Core Design: Giving AI a Face
Anthropomorphic Interaction Experience
OpenHuman's most eye-catching design choice is giving AI a face—a yellow creature lives on your desktop, moves, talks, and can chat with you out loud. Even more boldly, it can join your Google Meet calls as a "real participant," listening in and taking notes throughout. This is a first among desktop AI assistants of its kind.
The synthetic voice plus lip sync technical approach transforms this yellow creature from a cold dialog box into a desktop companion with genuine "presence." This technology has matured significantly in recent years thanks to advances in deep learning—traditional approaches relied on phoneme-to-viseme mapping tables, while modern solutions like Wav2Lip can predict facial keypoint movements directly from audio waveforms. Research from the MIT Media Lab shows that AI agents with facial expressions significantly boost users' emotional engagement and information retention, which is why more AI products are shifting from pure text interfaces to embodied interaction. OpenHuman's choice to implement this on the desktop means either performing real-time local inference or using a compromise approach with pre-rendered animation frames.
Data Integration and Transparent Memory Tree
OpenHuman's operating mechanism has three layers:
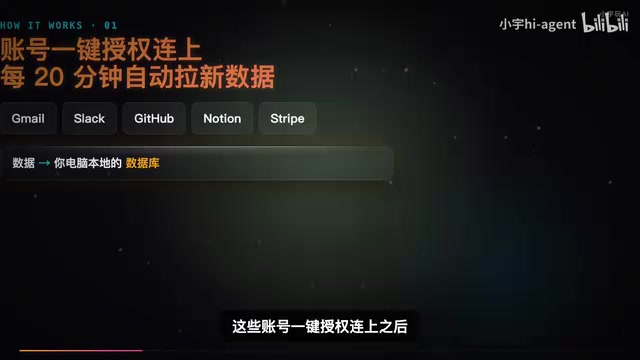
- Data Ingestion: One-click authorization for Gmail, Slack, GitHub, Notion, and other accounts, with automatic data pulls to the local database every 20 minutes
- Data Processing: All data is compressed into plain text segments, each no longer than 3,000 tokens, with three levels of summaries organized by data source, person/project, and date
- Transparent Memory: The memory tree isn't a black box—all chunked data lands in a local Markdown folder that users can open directly to see exactly what the AI knows about them, with the ability to edit or delete anything
A quick explanation of tokens and why they matter: tokens are the basic units that large language models use to process text. In English, each word corresponds to roughly 1–1.5 tokens; in Chinese, each character is about 1.5–2 tokens. Current mainstream models like GPT-4o have a context window of 128K tokens, while Claude offers 200K tokens—but longer contexts mean higher API costs and slower response times. Therefore, keeping each data segment within 3,000 tokens, combined with a hierarchical summary retrieval strategy, is an engineering choice that balances cost and effectiveness.
This "openable, editable" memory design is far more transparent than the memory features in typical AI assistants. While it's not expensive to replicate, it's genuinely a killer UX design choice.
Marketing Claims That Need Debunking
The "Local-First" Privacy Promise Doesn't Hold Up
OpenHuman heavily promotes being "local-first" and "privacy-controllable," but the only things that are truly local are the database and the Markdown folder. The critical issues:
- Authorization tokens are stored on their backend
- All LLM calls go through their backend
- Even web searches go through their backend proxy
The core risk here lies in where OAuth tokens are stored. OAuth 2.0 is the standard protocol for authorization between internet services. When a user authorizes OpenHuman to access Gmail, Google issues an Access Token (short-lived) and a Refresh Token (long-lived). Whoever holds the Refresh Token can continuously obtain new Access Tokens without the user's knowledge, maintaining long-term access to user data. If tokens are stored locally on the user's device, even if the development team's servers are breached, user data remains safe. But if tokens are stored on the developer's backend—as OpenHuman currently does—a single data breach could affect all users.
In other words, the permission keys to your connected Gmail, Slack, GitHub, and Stripe accounts are all in the hands of a startup team that's only three months old. For users who care about data security, this is a risk that cannot be ignored.
Visible "Borrowed" Technical Implementation
Digging into the code and documentation reveals several notable issues:
- Claims 118 integrations, but they're actually built on Composio, a third-party platform—explicitly stated in source code comments
- The so-called "compression feature that saves 80% of tokens" is acknowledged in their own documentation as being ported from someone else's GitHub project, with third-party testing showing 70% savings at best
- Two sync failures occurred during five days of testing
Regarding Composio: it's an open-source platform specifically designed to provide third-party tool integrations for AI Agents. It wraps the APIs of hundreds of SaaS services—Gmail, Slack, GitHub, Notion, etc.—into standardized tool-calling interfaces, so developers don't need to individually handle each platform's OAuth authentication flow and API specifications. This "integration-as-a-service" model dramatically lowers the development barrier but introduces an additional dependency layer—if Composio experiences downtime or changes its API, applications that depend on it will be affected. The fact that OpenHuman's 118 integrations are actually built on Composio indicates that its core competitive advantage isn't in integration capability itself, but in the interaction design and memory management layer above it.
As for token compression technology, common approaches include summary compression (using a smaller model to generate summaries of long texts), semantic deduplication (removing redundant information), and hierarchical retrieval (loading relevant segments only when needed). If the claimed 80% compression rate were accurate, it would mean context that originally required 100K tokens could be compressed to under 20K tokens, dramatically reducing API costs. But the third-party test result of 70% at best suggests that in real-world scenarios, information-dense text (such as code or data tables) is difficult to compress to ideal ratios.
These aren't fatal flaws, but the gap between claims and reality warrants caution.
Takeaways for AI Practitioners
Technical Architecture Worth Studying
For engineers, OpenHuman's Tauri + Rust + embedded core architecture is an excellent reference for building desktop AI products.
Tauri is a next-generation cross-platform desktop application framework that released version 1.0 in 2022 and is a direct competitor to Electron. Electron was developed by GitHub, and well-known applications like VS Code, Slack desktop, and Discord are built on it—but its fatal weakness is resource consumption. Every Electron app embeds a complete Chromium browser engine, meaning even a simple application can consume over 200MB of memory. Tauri uses the operating system's native WebView to render the frontend interface, with backend logic written in Rust, resulting in installation packages typically 1/10 the size of Electron's, with significantly lower memory usage. For desktop AI assistants that need to run persistently in the background, being lightweight is especially important—users won't accept an "assistant" that consumes 1GB of memory. Rust, meanwhile, delivers performance close to C/C++ while eliminating memory safety issues at compile time through its ownership system, making it well-suited for handling sensitive data.
Product Design Worth Emulating
For AI product entrepreneurs, the design philosophy of "making memory something you can open and inspect" is extremely valuable. In an era where user trust in AI is generally low, transparency is the shortest path to building trust.
But Now Isn't the Time to Jump In
Overall, OpenHuman is a sample worth tracking, not a production tool worth adopting right now. The centralized permission risk, sync stability issues, and the team's early stage all mean it still needs time to prove itself.
Outlook for the Desktop AI Assistant Space
The desktop AI assistant space is entering a critical year ahead. From the OpenHuman case, several trends emerge:
- Anthropomorphic interaction will become an important dimension for differentiated competition
- Local data sovereignty is a core user demand, but genuinely achieving it is extremely difficult
- Transparent memory may become an industry standard
- Indie developers still have opportunities to leverage exceptional product design to move markets
But OpenHuman itself may not be the ultimate winner. In this rapidly iterating space, a three-month head start can vanish in an instant. The real deciding factor will be who can find the optimal balance between privacy security and feature richness.
Key Takeaways
Related articles
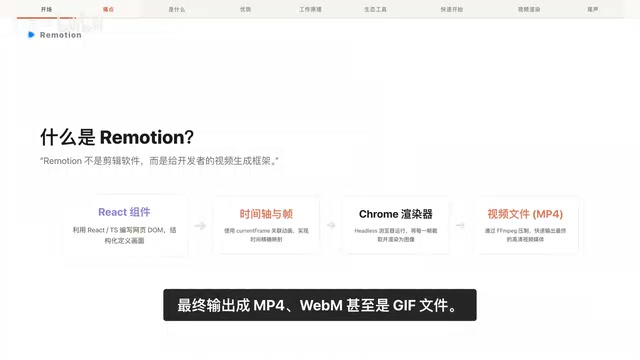
Remotion: The Open-Source Framework for Code-Driven Video Production with React
Deep dive into Remotion, the open-source framework for writing videos with React components. Covers core principles, use cases, comparison with traditional editors, and quick start guide.
Nex N2 Pro Real-World Testing: Top 5 on Official Benchmarks, Only 12th in Independent Tests
Deep-dive testing of Nex N2 Pro open-source Agent model comparing official benchmarks vs independent results. The 397B parameter model shows decent frontend generation but ranks 12th independently, not top 5 as claimed.
Claude Code Workflow in Practice: From Requirement Grilling to AFK Agent Auto-Coding
A detailed walkthrough of building real features with Claude Code: Grill Me requirement interrogation, auto-generated PRDs, AFK agent coding, and QA iteration loops with DDD and TDD strategies.