Optimize Anything: One API to Unify Optimization of Code, Prompts, and Agent Architectures
Optimize Anything: One API to Unify Op…
A unified framework transforms diverse optimization problems into LLM-iterated text Artifact optimization, outperforming specialized tools.
UC Berkeley, Stanford, and collaborators propose Optimize Anything, a framework that unifies optimization problems across CUDA kernels, agent architectures, prompts, and more by treating them as text Artifact optimization. Users provide just three inputs — an initial Artifact, an evaluator, and an optional dataset — while the system iteratively improves candidates using auxiliary diagnostic information (analogous to gradients in numerical optimization) and Pareto frontier-based search strategies. Achieving SOTA across six domains including coding agents, ARC-AGI, cloud scheduling, AIME prompts, CUDA kernels, and circle packing, it demonstrates that "evaluation + feedback + LLM iteration" is a viable universal problem-solving paradigm.
Core Insight: Everything Can Be Optimized as Text
A joint team from UC Berkeley, Stanford, and other top institutions published a groundbreaking paper — Optimize Anything — proposing a universal text optimization framework. The core insight is surprisingly simple: many problems across different domains can essentially be transformed into optimization problems over text Artifacts.
Whether you're optimizing CUDA kernels, cloud scheduling policies, agent architectures, SVG images, or system prompts, the underlying logic is the same — serialize the target object into a string, evaluate its performance, and have a large language model propose improvements based on diagnostic feedback.
Previously, we've witnessed the potential of LLMs as optimizers: FunSearch can evolve Python functions to push mathematical boundaries, and AlphaEvolve can optimize code and even improve matrix multiplication bounds that stood for five to six years. But these tools only work for single types of tasks and can only handle one problem at a time. Optimize Anything aims to break all these barriers with a single unified API.
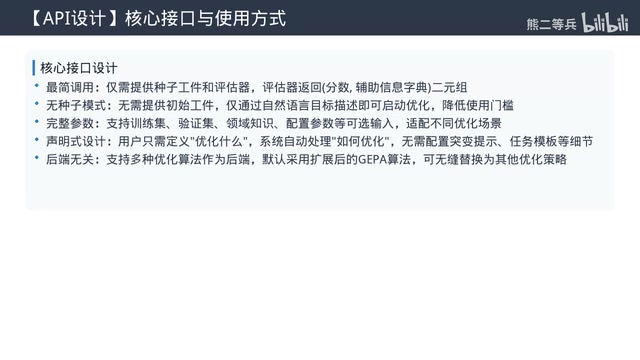
A Minimalist Declarative API: Three Inputs to Handle Everything
Based on this insight, the team designed an extremely concise declarative API. Users only need to provide three core inputs:
- An initial seed Artifact (or even none — the system can generate one from a natural language description)
- An evaluator that returns scores and optional diagnostic feedback
- An optional dataset
All the complex steps — prompt construction, reflection, candidate generation, selection, search strategies — are handled automatically by the system. This design is inspired by DSPy's "programming not prompting" principle, and its greatest advantage is that the same API call works whether you're optimizing LLM prompts, agent architectures, or images, with no need to modify the interface for different domains.
Particularly noteworthy is the seedless mode: in domains where it's difficult to provide an initial Artifact (such as 3D modeling), users don't even need to write an initial version — they just provide a natural language description of the goal, and the LLM generates the first candidate from scratch. This dramatically lowers the barrier to entry.
Unifying Three Optimization Modes
Optimize Anything unifies three optimization modes under the same interface, with switching determined entirely by whether a dataset and validation set are provided:
Single-Task Search
No dataset required — the candidate itself is the solution, and the evaluator scores it directly. This is the mode used by AlphaEvolve and OpenEvolve. For example, in circle packing problems, the Artifact is the packing algorithm, and the evaluator returns the packing score along with geometric diagnostic information.
Multi-Task Search
Requires a batch of related tasks as a dataset — insights gained from solving one task can help solve others. This is a mode that none of the previous LLM evolution frameworks supported. For example, in CUDA kernel generation scenarios, each task is a PyTorch operation to accelerate, and multi-task mode can discover optimization patterns that transfer across problems.
Generalization Mode
Requires both a training set and a validation set — the optimized Artifact must perform well on unseen examples. Previously, only GEPA's prompt optimization used this mode; now it's extended to arbitrary text Artifacts.
The key distinction: multi-task search outputs N specialized Artifacts, while generalization mode outputs a single globally universal Artifact.
Experiments Across Six Domains: Comprehensive SOTA
The paper validates results across six completely different core domains, achieving or surpassing the performance of specialized tools in each.
Coding Agent Skill Optimization (Generalization Mode)
Optimizes natural language usage instructions and best practices for specific codebases. The optimized skills boosted Claude Code's pass rate from 79.3% to 98.3%, and Sonnet 4.5 from 94.88% to 100%, with solve time reduced by 47%. More importantly, skills discovered for one model transfer directly to another, proving that generalization mode can learn model-agnostic repository knowledge.
ARC-AGI Agent Architecture Optimization (Generalization Mode)
Starting from a simple 10-line initial agent, the system iteratively designed a complex 300+ line system with 4 components and comprehensive fallback mechanisms. Test accuracy improved from 32.5% to 89.5% — a 57 percentage point improvement, nearly tripling the original performance.
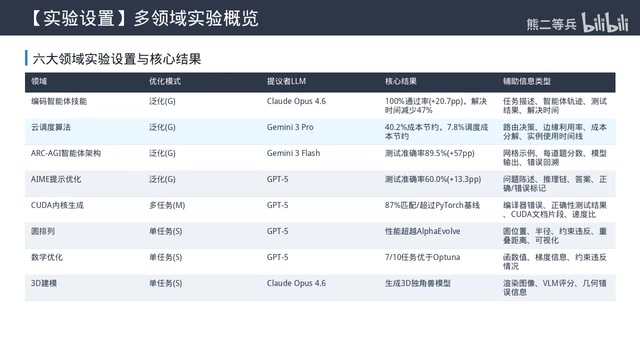
The optimized architecture implements a 4-stage pipeline: pattern analysis to induce rules → code generation and verification → multi-round debugging → structured degradation. The system independently discovered architectural patterns that typically require manual engineering iterations.
Cloud Scheduling Algorithm Optimization (Generalization Mode)
The CloudCast routing strategy saved 40.12% in costs compared to shortest-path algorithms; the ComputeBlade scheduling strategy saved 700% in costs. Both results achieved first place on the AD2S leaderboard.
AIME Prompt Optimization (Generalization Mode)
Optimizing GPT-4o-mini's system prompt for AIME math problems, test accuracy improved from 46.67% to 60.0%, surpassing MIProv2's 51.33%.
CUDA Kernel Generation (Multi-Task Search)
Generating high-performance CUDA kernels for 31 PyTorch operations, 87.7% of generated kernels matched or exceeded the PyTorch baseline, 48% achieved over 10% speedup, and 25% achieved over 25% speedup.
Circle Packing Problem (Single-Task Search)
The final solution outperformed AlphaEvolve's published results.
Two Core Mechanisms Explained
Auxiliary Information: The "Gradient" of Text Optimization
Traditional numerical optimization compresses all diagnostic context into a single scalar. Optimize Anything elevates auxiliary information to a first-class citizen of the evaluator contract, supporting multiple types of diagnostic feedback:
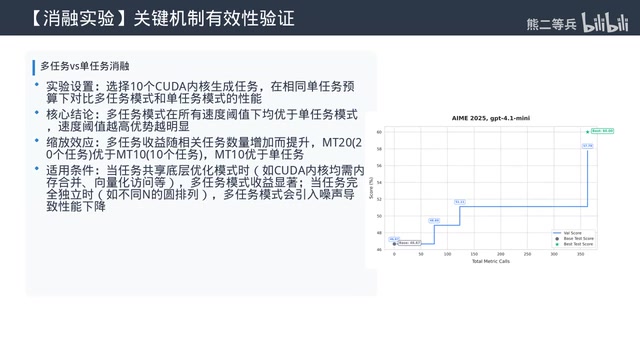
- Textual: compiler errors, runtime exceptions, performance profiling summaries
- Structured data: per-test-case results, multi-objective sub-scores, execution traces
- Visual: rendered SVGs, 3D model screenshots, chart visualizations
Auxiliary information is to text optimization what gradients are to numerical optimization — gradients tell the optimizer which direction to move, while auxiliary information tells the LLM proposer why a candidate failed and how to fix it. Ablation experiments show that convergence with auxiliary information is 4 to 6 times faster than with score-only feedback.
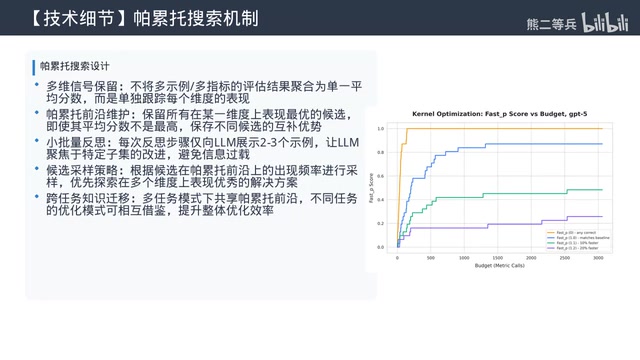
Pareto Frontier-Based Search Strategy
A naive approach would compress multiple evaluation signals into a single average score and always select the top-ranked candidate, easily leading to stagnation. Optimize Anything takes a more sophisticated approach:
- Track scores for each task/metric independently, maintaining a Pareto frontier
- Any candidate that performs best in some dimension is retained
- Each reflection step shows the proposer only a small batch of 2-3 examples for targeted improvement
- The frontier accumulates complementary strengths from different candidates across iterations
This mechanism also supports multi-task search — strategies discovered for one problem can automatically transfer to other problems through the shared Pareto frontier.
Significance and Outlook
The significance of Optimize Anything goes beyond being a useful tool — it demonstrates that the "evaluation + feedback + LLM iteration" pattern can serve as a universal problem-solving paradigm, breaking down the siloed landscape of domain-specific optimization tools. Whether you're a programmer, researcher, or user with limited coding experience, you can describe optimization goals in natural language through this universal interface and let the system help achieve high-quality results.
From a broader perspective, this work reveals an important trend: as LLM capabilities continue to improve, an increasing number of engineering optimization problems will be redefined as closed loops of "text generation + automated evaluation." In the future, this framework can be extended with more optimization backends and cover more domains, becoming the universal optimization infrastructure of the AI era.
Related articles
New Species Discovered in New York's C…
New Species Discovered in New York's Central Park? Inside the Urban Insect Hunting Project
Scientists set up insect traps in NYC's Central Park and Prospect Park to discover unknown species. With 90% of Earth's species still unnamed, urban biodiversity research is becoming a new trend in ecology.
The Full Story of the Higgs Boson Disc…
The Full Story of the Higgs Boson Discovery: An Insider's Account of the 'God Particle'
A Fermilab physicist's insider account of the Higgs boson discovery: the transatlantic race with CERN, behind-the-scenes details of the 2012 announcement, 14 years of verification, and the true origin of the 'God Particle' name.
 Research
ResearchSciMDR: How a 7B Small Model Rivals GPT-5 in Scientific Reasoning
Yale and other institutions introduce SciMDR, a two-stage data synthesis pipeline enabling a 7B model to match GPT-5 level performance in scientific literature comprehension.