Palo Alto Networks Tests GPT-5.5: A Quantum Leap in Cybersecurity Workflow Efficiency

Palo Alto Networks validates GPT-5.5's transformative impact on cybersecurity workflow efficiency.
Palo Alto Networks shared its real-world experience with OpenAI's GPT-5.5, highlighting breakthroughs in breadth-of-thought reasoning, parallel tool calling, and vulnerability reporting. The model delivers near-final reports on the first pass, dramatically cutting analysis-to-delivery time. Combined with Codex, GPT-5.5 excels at detecting real threats in massive data, helping SOC teams combat alert fatigue and close the window of exposure against attackers.
Overview
Palo Alto Networks, a global leader in cybersecurity, recently shared its team's hands-on experience with OpenAI's latest model, GPT-5.5. Based on their feedback, GPT-5.5 demonstrates significant advantages in breadth-of-thought reasoning, parallel tool calling, and cybersecurity vulnerability reporting — tangibly transforming the daily efficiency of security teams.
Founded in 2005 and headquartered in Santa Clara, California, Palo Alto Networks is one of the world's largest independent cybersecurity companies. The company initially made its name with next-generation firewall (NGFW) technology, disrupting the traditional firewall market through application-layer traffic identification. It has since expanded into cloud security (Prisma Cloud), security operations (Cortex XDR/XSIAM), zero trust network access (ZTNA), and other domains, forming a three-platform strategy covering network security, cloud security, and security operations. As of fiscal year 2024, the company serves over 80,000 enterprise customers worldwide, including a large number of Fortune 500 companies and government agencies.
Notably, GPT-5.5 is OpenAI's next-generation large language model following the GPT-4 series. Unlike the o-series models (such as o1 and o3) that emphasize deep reasoning capabilities, GPT-5.5's design philosophy focuses more on "breadth of thought" — the ability to simultaneously consider more information dimensions and contextual cues when facing complex, multi-dimensional problems, rather than drilling deep along a single chain of reasoning. OpenAI positions it as a general-purpose model suited for complex workflow integration, complementing the o-series models that specialize in mathematical and programming reasoning.



Two Core Breakthroughs of GPT-5.5
Breadth of Thought and Token Efficiency Gains
The Palo Alto Networks team noted that GPT-5.5's most standout feature is its "breadth" capability. When facing open-ended questions, the model can consider more angles simultaneously, maintain attention to earlier context, and use multiple tools in parallel without losing its main thread of logic.
In the large language model space, "breadth of thought" and "deep reasoning" represent two different cognitive strategies. Deep reasoning (such as Chain-of-Thought reasoning) is similar to how humans solve math problems step by step — the model follows a single logical chain, drilling deeper layer by layer, making it well-suited for structured problems with clear answers. Breadth of thought, on the other hand, is more akin to the panoramic scanning ability of an experienced analyst facing a complex situation — simultaneously tracking multiple variables and threads, establishing connections across different information dimensions. In cybersecurity analysis, a single attack incident may involve network-layer anomalies, application-layer vulnerabilities, user behavior deviations, external threat intelligence, and many other dimensions. Breadth-of-thought capability prevents the model from overlooking critical signals by becoming overly focused on any single aspect.
This capability is especially critical for cybersecurity. Security analysis often requires simultaneous attention to multiple attack vectors, multi-layered system architectures, and various potential threats. Traditional linear analysis approaches can easily miss key information. GPT-5.5's parallel tool calling capability means it can query multiple data sources and execute multiple detection tasks simultaneously while maintaining analytical coherence.
Parallel tool calling refers to a large language model's ability to initiate multiple external tool or API call requests simultaneously during a single inference pass, rather than executing them sequentially one by one. In traditional function-calling patterns, a model typically needs to call Tool A first, wait for the result, then decide whether to call Tool B — a serial approach that significantly increases latency when multiple data sources need to be queried. Parallel tool calling allows the model to identify multiple independent tasks that can be executed simultaneously, issue all requests at once, and then synthesize all returned results for unified analysis. In cybersecurity scenarios, this means the model can simultaneously query threat intelligence databases, search vulnerability databases (such as the CVE database), analyze log data, and scan network configurations — compressing what would otherwise be a multi-minute serial process into just seconds.
The team particularly emphasized the model's token efficiency — accomplishing more comprehensive analysis with fewer computational resources. Tokens are the basic units by which large language models process text; typically one English word corresponds to 1–2 tokens, and one Chinese character corresponds to 1–2 tokens. Model usage costs are directly tied to the number of tokens consumed. Improved token efficiency means the model can complete tasks of equivalent quality using fewer tokens. For an enterprise like Palo Alto Networks that needs to deploy AI capabilities at scale, this has a dual significance: first, it directly reduces API call costs — in scenarios processing millions of security analysis requests daily, even a 10% per-request reduction in token consumption translates to substantial annualized cost savings; second, it reduces inference latency — fewer tokens mean faster response times, which can be a critical factor in security incident response where every second counts.
Vulnerability Reporting: From Multiple Iterations to First-Pass Delivery
The second major breakthrough is evident in cybersecurity vulnerability reporting workflows. Palo Alto Networks found that GPT-5.5's first-pass output is sufficiently detailed and easy to understand, fundamentally shortening the time from analysis to delivery.
A standard cybersecurity vulnerability report typically needs to include: a vulnerability overview, affected systems and versions, severity rating (usually using the CVSS scoring system), technical details and attack path analysis, proof-of-concept (PoC) code or reproduction steps, potential impact assessment, remediation recommendations and mitigation measures, and more. In traditional workflows, security analysts need to gather information from multiple sources, manually compile it into a structured report, then go through peer review and multiple rounds of revision before final delivery. This process typically takes hours or even days.
GPT-5.5 can produce a report that approaches delivery standards on its very first generation, covering all the above elements with clear and accurate language. This means the analyst's role shifts from "report writer" to "report reviewer," freeing them to invest more energy in high-value judgment and decision-making rather than repetitive documentation work — potentially multiplying productivity several times over.
How GPT-5.5 Achieves "Needle in a Haystack" Threat Detection
Palo Alto Networks also mentioned that GPT-5.5, when paired with Codex, is remarkably effective at "finding the needle in the haystack." This metaphor has a concrete meaning in cybersecurity: identifying genuine security threats within massive volumes of logs, network traffic, and system events.
Codex is OpenAI's AI agent product designed for software engineering, capable of autonomously executing code writing, testing, debugging, and other tasks in a cloud sandbox environment. In cybersecurity scenarios, Codex's capabilities extend to automated vulnerability scanning script development, malicious code sample analysis, security policy configuration validation, log parsing script generation, and more. When GPT-5.5 and Codex work together, GPT-5.5 handles high-level threat analysis and judgment while Codex executes specific technical verification and code-level operations. Together, they form a complete closed loop from "analytical assessment" to "technical verification." This combination is especially powerful when processing massive security datasets — GPT-5.5's breadth-of-thought capability helps pinpoint suspicious targets, while Codex conducts in-depth technical verification of those targets through automated scripts.
High false positive rates have long been a core challenge for Security Operations Centers (SOCs). A SOC is the central hub of an enterprise's cybersecurity defense, typically staffed by security analysts working 24/7 shifts to monitor, detect, analyze, and respond to security incidents. According to industry research, a mid-sized enterprise's SOC may receive thousands to tens of thousands of security alerts daily, yet the real threats requiring human intervention typically account for less than 5%. This extremely high false positive rate leads to severe "alert fatigue" — analysts gradually lower their vigilance amid the flood of false positives, potentially missing genuine attack signals. Reports from research firms like Gartner show that alert fatigue is one of the leading causes of delayed security incident response. If GPT-5.5 can more precisely extract real threat signals from the noise, it would not only improve detection efficiency but fundamentally alleviate the staffing pressure and burnout experienced by SOC teams, dramatically enhancing security teams' response efficiency and overall defense posture.
Profound Implications for the Cybersecurity Industry
The Palo Alto Networks case demonstrates that GPT-5.5's improvements are not merely reflected in benchmark scores but are producing measurable efficiency gains in real enterprise workflows. This substantial reduction in "analysis-to-delivery" time could mean the critical time difference between completing defensive deployments before attackers exploit vulnerabilities — a matter of paramount importance for the cybersecurity industry, which demands rapid response.
In cybersecurity, the time between a vulnerability's discovery and attackers beginning large-scale exploitation is known as the "Window of Exposure." According to statistics from security research firms like Mandiant, the time from public disclosure of zero-day vulnerabilities to mass exploitation has shrunk from weeks to days or even hours in recent years. This means security teams must complete the entire process of vulnerability assessment, impact analysis, patch testing, and defense deployment within an extremely short timeframe — any delay at any stage could leave the enterprise exposed to attack risk. GPT-5.5's compression of vulnerability reporting from "multiple iterations" to "first-pass delivery," combined with the analytical acceleration from parallel tool calling, directly shortens the defender's response time, helping security teams gain precious advantages in this race against attackers.
As a noteworthy detail, Palo Alto Networks — a top-tier security vendor with annual revenue exceeding $6 billion — provides an important reference point for other enterprise AI applications through its endorsement of GPT-5.5. When a model's breadth of thought, parallel tool usage, and first-pass output quality reach a certain level, AI is no longer just an auxiliary tool — it becomes an indispensable core component of the workflow.
Key Takeaways
Related articles
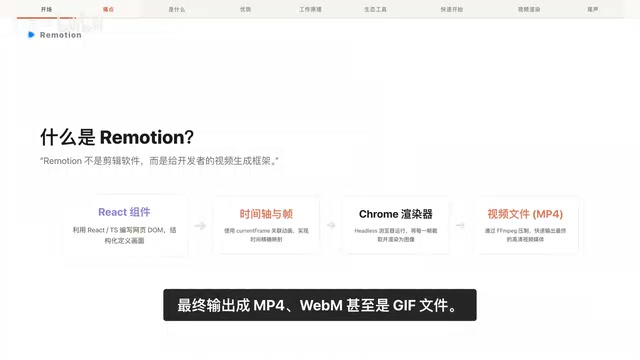
Remotion: The Open-Source Framework for Code-Driven Video Production with React
Deep dive into Remotion, the open-source framework for writing videos with React components. Covers core principles, use cases, comparison with traditional editors, and quick start guide.
Nex N2 Pro Real-World Testing: Top 5 on Official Benchmarks, Only 12th in Independent Tests
Deep-dive testing of Nex N2 Pro open-source Agent model comparing official benchmarks vs independent results. The 397B parameter model shows decent frontend generation but ranks 12th independently, not top 5 as claimed.
Claude Code Workflow in Practice: From Requirement Grilling to AFK Agent Auto-Coding
A detailed walkthrough of building real features with Claude Code: Grill Me requirement interrogation, auto-generated PRDs, AFK agent coding, and QA iteration loops with DDD and TDD strategies.