pnpm Monorepo Full-Stack AI Engineering in Practice: Building a Multimodal Conversation System
pnpm Monorepo Full-Stack AI Engineerin…
A full-stack architecture for building multimodal local AI chat systems using pnpm Monorepo.
This article analyzes a pnpm Monorepo full-stack AI engineering architecture that combines modern frontend engineering management with local AI model inference. The project implements streaming text conversations and multimodal image understanding, supports flexible multi-engine switching through an abstract inference layer, features configurable prompt design, and processes all data locally to ensure privacy — making it an excellent reference for full-stack developers deploying AI capabilities.
Introduction: Why This Architecture Is Worth Learning
With the rapid development of AI engineering, building an efficient and maintainable full-stack AI project architecture has become a key focus for many developers. Based on content shared by a Bilibili creator about pnpm Monorepo full-stack AI engineering practices, this article provides a detailed analysis of how to leverage modern frontend engineering toolchains to build a local AI conversation system with multimodal interaction support.
The core value of this architecture lies in combining pnpm Monorepo's engineering management capabilities with local AI model inference, delivering a complete solution that embodies both engineering best practices and practical AI application deployment.
Project Demo
Text Conversation Feature
The project's first core feature is a text conversation system based on local models. After a user sends a message, the system invokes a locally deployed AI model for inference and returns the response in a streaming fashion. The entire message sending and synchronization process is smooth and natural, delivering an experience close to commercial-grade conversation products.
Streaming Response is a standard technology in modern AI conversation systems, typically implemented using Server-Sent Events (SSE) or WebSocket protocols under the hood. Unlike traditional request-response patterns, streaming allows the server to progressively push content to the client as it's being generated, so users can see character-by-character output without waiting for the complete response. This technique is particularly important in LLM inference scenarios, where generating a full response may take several seconds or longer — streaming output can reduce the perceived first-token latency from seconds to milliseconds.
You might not have noticed, but since local model inference is used, all data processing is completed locally without relying on external API services. This provides clear advantages in data privacy and offline usage scenarios. Local model inference refers to deploying AI models on the user's own device rather than calling cloud APIs. Common local inference frameworks include Ollama, llama.cpp, vLLM, and others. Through model quantization techniques (such as 4-bit/8-bit quantization in GGUF format), they enable large models that originally required tens of gigabytes of VRAM to run on consumer-grade GPUs or even CPUs. This approach not only eliminates data leakage risks but also removes API call costs, resulting in lower long-term usage expenses.
Multimodal Image Understanding
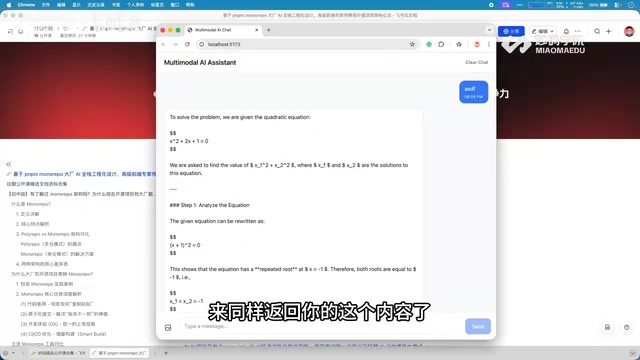
The project's second highlight is the integration of multimodal capabilities. Users can not only send text messages but also upload images, and the system can intelligently analyze and understand image content. Specific capabilities include:
- Image content recognition: Analyzing objects, scenes, and other visual information in images
- Text extraction (OCR): Recognizing and extracting text content from images
- Image-text Q&A: Answering user questions based on uploaded images
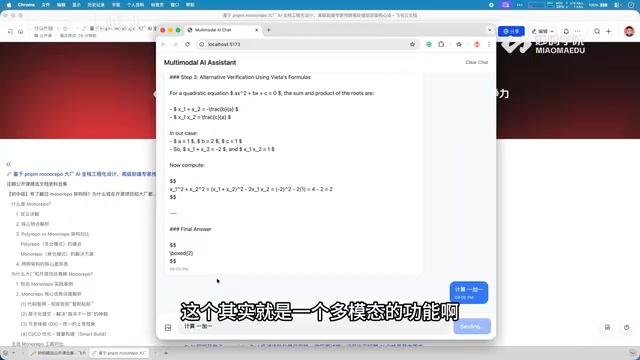
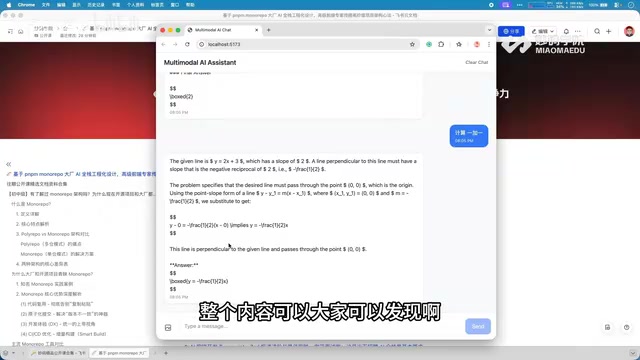
For example, a user can upload an image containing a mathematical formula and then ask "Help me calculate 1 plus 1," and the system will provide an accurate answer based on the image context. This multimodal interaction approach greatly expands the application scenarios of conversation systems.
Multimodal AI models refer to models capable of simultaneously processing and understanding multiple data types (such as text, images, audio, and video). LLaVA (Large Language and Vision Assistant) is a representative open-source project in this field. It converts images into visual tokens through a vision encoder (typically based on CLIP's ViT architecture), which are then fed into a large language model together with text tokens for joint reasoning. Similar open-source multimodal models include MiniCPM-V, InternVL, Qwen-VL, and others. Local deployment of these models typically requires more computational resources than pure text models, as the vision encoder itself also consumes additional VRAM and compute power.
Technical Architecture Analysis
Engineering Advantages of pnpm Monorepo
The pnpm Monorepo architecture plays a crucial role in this project. Compared to traditional single-repo or multi-repo approaches, Monorepo brings the following advantages:
- Unified dependency management: Dependencies for frontend, backend, and shared utility libraries are managed uniformly, avoiding version conflicts
- Efficient code reuse: Shared type definitions and utility functions can be shared across packages
- Integrated build pipeline: A single command can complete the build and deployment of the entire full-stack project
- Smooth development experience: After modifying shared packages, dependent packages automatically hot-reload
pnpm (Performant npm) is a high-performance Node.js package manager whose core innovation is using hard links and symbolic links to share dependencies, saving significant disk space and dramatically improving installation speed compared to npm and yarn. Monorepo (Monolithic Repository) is a strategy of managing multiple related projects in the same code repository — tech giants like Google and Meta have long adopted this pattern. pnpm's workspace feature natively supports Monorepo, defining package directory structures through the pnpm-workspace.yaml configuration file. Combined with its strict dependency isolation mechanism (which avoids the phantom dependency problem common with npm), it has become the preferred tool for frontend Monorepo solutions. Similar solutions include build orchestration tools like Turborepo and Nx, which can work alongside pnpm workspace to provide advanced capabilities such as task caching and incremental builds.
Local Model Integration Approach
The project achieves inference capabilities by calling locally deployed AI models. Based on the demo, the model supports English responses (switchable to Chinese by adjusting prompts) and possesses multimodal understanding capabilities, suggesting the underlying integration likely uses something similar to LLaVA or other open-source models supporting visual understanding.
At the implementation level, local model integration typically follows this technical path: first, quantized model files are loaded locally through tools like Ollama; then a local HTTP service compatible with the OpenAI API format is launched; finally, the application backend communicates with the model service through standard HTTP requests. This design means frontend code doesn't need to concern itself with the specific model deployment method — it only needs to interface with a unified API. Model selection is also highly flexible, ranging from lightweight options like Phi-3 and Gemma to heavyweight ones like Llama 3 and Qwen2.5, all freely switchable based on hardware conditions.
Practical Insights and Takeaways
Flexibility of Prompt Engineering
As seen in the demo, the model defaults to responding in English. The author mentions that the response language and style can be adjusted by modifying prompts, highlighting the importance of prompt engineering in practical applications. A well-designed system should make prompts configurable, allowing quick adjustments for different scenarios.
Prompt Engineering has evolved into a core skill in AI application development. In engineering practice, prompts should typically not be hardcoded into business logic but managed as independent configuration resources. Common approaches include: using template engines to support variable interpolation, establishing prompt version management mechanisms, and setting up A/B testing frameworks to compare the effectiveness of different prompts. System Prompts define the model's role and behavioral boundaries, while User Prompts carry specific task instructions — the proper layered design of both is key to building high-quality AI applications.
Multi-Engine Architecture Design
The author mentions that the project contains multiple engine examples, hinting at an important architectural principle: abstracting the AI inference layer. By defining a unified interface specification, different AI engines (such as local models, cloud APIs, etc.) can be flexibly swapped while upper-level business logic remains unchanged.
The core idea of this abstract inference layer design pattern is to establish a unified interface layer between business logic and specific AI engines, similar to the adapter pattern or strategy pattern in design patterns. In practice, this typically manifests as defining a standard set of interface protocols (such as chat, completion, embedding methods), then implementing adapters separately for different AI backends (Ollama, OpenAI API, Azure, Anthropic, local ONNX models, etc.). This design allows the system to switch underlying AI engines through configuration without modifying upper-level code, greatly improving system maintainability and extensibility. Well-known frameworks in the industry such as LangChain, Vercel AI SDK, and LiteLLM all adopt similar abstraction design philosophies, and developers can reference these frameworks' interface designs to build their own inference abstraction layers.
Conclusion
This full-stack architecture combining pnpm Monorepo with local AI models organically integrates modern frontend engineering best practices with AI application development. For full-stack developers looking to implement AI capabilities in real projects, this is a highly valuable technical reference. Mastering this type of architectural capability not only deepens personal technical expertise but also provides stronger competitiveness in the job market.
From a broader perspective, this architecture represents an important trend in AI application development: moving AI capabilities from the cloud down to edge and local devices. As model quantization techniques advance and consumer hardware computing power increases, the feasibility and practicality of local AI inference are rapidly improving. Combined with Monorepo's engineering management capabilities, developers can efficiently build, iterate, and maintain complex AI application systems — this is precisely where the core competitiveness of future full-stack AI engineers lies.
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.