Real-World Comparison of Chinese AI Coding Models: Which One Best Generates a Complete E-Commerce System in One Shot?
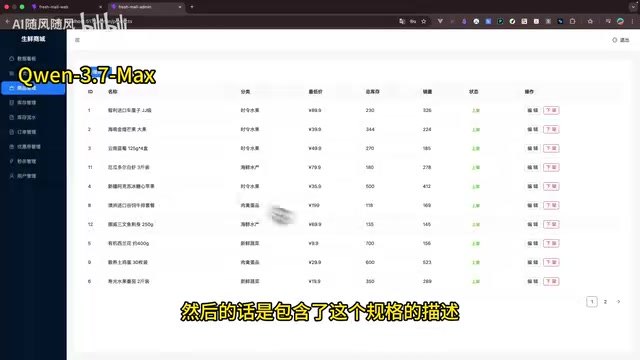
Qwen 3.7 Max tops a six-model Chinese AI coding test generating a full e-commerce system in one shot.
A Bilibili creator tested six Chinese AI coding models by having each generate a complete e-commerce system — storefront, admin panel, and Java backend — in a single session. Qwen 3.7 Max scored highest (9/10) with the best feature retention, followed by DeepSeek V4 Pro (8/10). The key differentiator wasn't code generation ability but "feature retention" during long tasks, with weaker models forgetting modules like coupons and flash sales.
Introduction: Testing Domestic Models with a Complete E-Commerce Project
The competition among Chinese AI models is fierce, with MiniMax M3, Qwen 3.7 Max, DeepSeek V4 Pro, Kimi K2.6, Zhipu 5.1, and Xiaomi MiMo 1.5 Pro all making their debut. But when it comes to actual coding ability, who is the true champion?
A Bilibili content creator designed an extremely challenging test: have each model generate a complete e-commerce system in one shot, including a storefront, a backend management system, and a Java backend service — three separate projects. This isn't a simple code snippet test; it's a comprehensive evaluation of each model's long-task execution ability, requirements comprehension, and code quality.
A complete e-commerce system involves multiple technical dimensions: front-end/back-end separation architecture, database design, API authentication, and concurrency control. The front end needs to handle complex state management (such as shopping cart state synchronization and coupon calculation logic), while the back end must implement transactional consistency (such as atomic operations for inventory deduction and order creation) and distributed locks (preventing overselling in flash sale scenarios). This type of project typically requires a 3-5 person development team several weeks to complete. Using it to test AI models' coding abilities thoroughly exposes weaknesses in system design, module coordination, and detail handling.
Test Design: Five Documents, One Generation Round, Multiple Fix Rounds
Test Tasks and Document Preparation
The test covered the core functional chain of an e-commerce system: user registration and login, product browsing, adding to cart, coupon claiming and usage, flash sales, order submission, simulated payment, and order viewing. Backend management included product management, inventory management, order management, coupon management, and flash sale activity management.
Five standardized documents were provided to each model:
- PRD Document: System functionality descriptions, page definitions, API paths
- Design Specification Document: UI design standards for the storefront
- Tech Stack Document: React for front end, Java for back end, MySQL 8 for database
- SPEC Document: Specific tasks and execution phase sequences
- Cloud MD Document: Global development standards, including front-end and back-end code constraints
PRD (Product Requirements Document) defines "what" the system should do; the SPEC (Specification) document defines the specific execution steps for "how" to do it. In AI coding scenarios, the quality of these two document types directly affects model output. The more structured the PRD and the more explicit the API paths, the easier it is for the model to generate consistent front-end and back-end code. The phase divisions in the SPEC document help the model decompose tasks, avoiding logical confusion during one-shot generation. This "document-driven development" paradigm is becoming a best practice in AI programming.
Test Process and Scoring Dimensions
The test process was straightforward: all five documents were given to the AI coding tool at once, and the model planned and completed the coding on its own. After the first round, manual testing was initiated, with 3-5 bug fix opportunities allowed, and total time was recorded.
Scoring dimensions included four aspects: front-end UI presentation and interaction experience, whether the complete ordering flow works end-to-end, backend management feature completeness, back-end Java code standards and quality, and total time to complete the task.
Testing Tools
MiniMax M3 used Cursor Code; Qwen 3.7 Max used its built-in Coding Player (Code mode); DeepSeek V4 Pro, Kimi K2.6, Zhipu 5.1, and Xiaomi MiMo 1.5 Pro all used Cursor Code. The creator noted that with sufficient document context, the experience gap between different coding tools wouldn't be significant.
Cursor Code is an AI coding IDE based on VS Code that integrates large models for code generation, completion, and refactoring, supporting multiple third-party models. Qwen's Coding Player is Alibaba's self-developed coding environment, deeply optimized for the Tongyi Qwen model series. The core differences between such tools lie in context management strategies (how project files are fed to the model), prompt engineering (how user intent is translated into model instructions), and code execution feedback mechanisms. The creator's judgment that tool differences are minimal with sufficient documentation is based on the premise that the documents already cover most of the context information, reducing the impact of the tool's own context management capabilities.
Detailed Breakdown of Six Chinese AI Coding Models
Qwen 3.7 Max: Best Overall Performance, 9 Points — Champion
Qwen 3.7 Max's performance was impressive. The front-end page design was comfortable and aesthetically pleasing, with good product detail page presentation. In core flow testing, the complete flow of adding to cart, logging in, adding an address, placing an order, and paying all worked in one shot. More interestingly, it implemented the complete coupon logic in the first round — a feature that all other models required subsequent debugging to complete.
The coupon system seems simple but actually involves coordination across multiple technical components: coupon distribution and claiming (preventing duplicate claims), usage condition validation (minimum spend threshold calculation), order amount deduction (real-time final price calculation at checkout), and coupon lifecycle state management (unused → used → expired). The fact that Qwen 3.7 Max fully implemented this logic in the first round demonstrates significantly superior ability in understanding business rules from requirements documents and translating them into code compared to other models.
However, issues existed: flash sale product ordering failed, adding products in backend flash sale management required manually entering product IDs (poor UX), and some front-end/back-end fields didn't match. Total time was 75 minutes, completion rate approximately 90%, final score 9 points.
DeepSeek V4 Pro: Feature-Complete Powerhouse, 8 Points — Close Second
DeepSeek V4 Pro's front-end pages were clean and tidy, with smooth registration and login flows. The complete ordering flow worked smoothly, and coupon claiming and usage functioned correctly — a "100 off 10" coupon triggered and deducted the amount properly. Backend management was also fairly comprehensive, with product specifications, inventory logs, and order details all viewable, and coupon disable functionality working normally.
Main issues: flash sale product page showed no product data, adding flash sale products in the backend failed, and personal center address management was missing. Total time was 70 minutes, completion rate approximately 85%, score 8 points.
Notably, both DeepSeek V4 Pro and Qwen 3.7 Max stumbled on the flash sale module. Flash sales are among the most technically challenging modules in e-commerce systems, requiring solutions for inventory consistency under high concurrency: when multiple users simultaneously purchase the same product, the system must guarantee no overselling. Traditional approaches include Redis pre-deduction of inventory, distributed locks, and asynchronous order processing via message queues. For AI models, correctly implementing flash sale logic requires not only understanding the business flow but also having knowledge of concurrent programming. Multiple models failing on flash sale functionality in this test reflects that models still have insufficient capability in handling complex scenarios requiring multi-stack coordination.
MiniMax M3: Middle of the Road, 7.5 Points — Third Place
MiniMax M3's front-end presentation was acceptable, with basic product browsing and add-to-cart functionality working, though API errors appeared when adding to cart. During the ordering flow, an error message appeared when submitting orders — although orders were ultimately submitted successfully, payment functionality was missing. The backend management system threw errors on load, coupon enable/disable operations were abnormal, and flash sale activity product addition also had issues.
Common problems included front-end/back-end field mismatches and database tables missing defined fields. Front-end/back-end field mismatch is one of the most common issues when AI generates full-stack code. The root cause is that the model may be in different generation phases when producing front-end and back-end code, creating inconsistencies in field naming for the same data entity (e.g., front end uses "totalPrice" while back end returns "total_price"). This is essentially a consistency maintenance problem during long-sequence generation. In human development, teams solve this through API documentation and interface integration testing; AI models need to maintain this cross-project consistency within a single generation, placing high demands on context management capabilities. Total time was 80 minutes, completion rate approximately 85%, 156 files generated (the most), score 7.5 points.
Zhipu 5.1: Fast First Round but Time-Consuming Debugging, 7 Points
Zhipu 5.1's first-round generation was fast, completing in about 30 minutes, but subsequent debugging consumed significant time. Front-end functionality was average, with the standard ordering flow (add to cart → add address → submit order → pay) working. However, two core features were severely missing: the coupon claiming feature had no entry point at all, and the flash sale product ordering flow was abnormal. In backend management, the coupon page threw errors on open, and products lacked specification management. Score: 7 points.
Kimi K2.6: Severe Feature Gaps, 6.5 Points
Kimi K2.6's performance was disappointing. Front-end pages barely passed, but core features failed extensively: the ordering flow threw errors and couldn't complete, coupons couldn't be displayed or used after claiming, and flash sale ordering also failed. In backend management, coupon creation failed, and flash sale management had issues. Total time was 80 minutes, completion rate only 60%, score 6.5 points.
Xiaomi MiMo 1.5 Pro: Worst Front-End Performance, 5.5 Points — Last Place
Xiaomi MiMo 1.5 Pro had the worst front-end among all models. Even after a dedicated design specification re-run optimization, page quality remained unsatisfactory. Functionality had even more issues: couldn't add addresses during cart checkout, flash sale purchases went through directly but lacked shipping information, and the coupon center was completely missing. In backend management, products lacked specification information, and orders showed no detailed information. Although the first round completed in 30 minutes, feature loss was severe. Score: 5.5 points.
Conclusions and In-Depth Analysis
Final Rankings
| Rank | Model | Time | Completion | Score |
|---|---|---|---|---|
| 1 | Qwen 3.7 Max | 75min | 90% | 9.0 |
| 2 | DeepSeek V4 Pro | 70min | 85% | 8.0 |
| 3 | MiniMax M3 | 80min | 85% | 7.5 |
| 4 | Zhipu 5.1 | ~60min | 75% | 7.0 |
| 5 | Kimi K2.6 | 80min | 60% | 6.5 |
| 6 | Xiaomi MiMo 1.5 Pro | ~60min | 55% | 5.5 |
Where Are the Core Differences?
From the test results, the core gap between models isn't whether they can generate code, but their "feature retention ability" during long-task execution. All models can run continuously for over an hour to complete large-scale coding tasks, but during this process, some models "forget" certain module features — such as coupon logic or flash sale flows.
This "forgetting" phenomenon is closely related to the attention dilution problem that large language models face when processing long contexts. The Transformer architecture's attention mechanism can theoretically attend to information at any position in the input sequence, but in practice, as generation length increases, the weight of earlier input information gradually decreases. When a model needs to continuously "remember" all functional requirements defined across five documents while generating tens of thousands of lines of code, some information inevitably gets "overlooked." The model's context window size, attention mechanism efficiency optimizations, and whether hierarchical memory or retrieval-augmented techniques are employed all affect feature retention performance.
The reason Qwen 3.7 Max leads is that it understands requirements documents more deeply, implementing complex business logic like coupons in the first round rather than waiting for subsequent fixes. This shows that differences in long-context comprehension and task decomposition capabilities directly determine the quality of final output.
Practical Recommendations
Regardless of which model you use, completing basic programming tasks is no longer an issue. But for large projects, the recommendation is: rather than throwing one massive task at the model all at once, break modules down finer and develop them one by one. This effectively reduces the risk of feature loss and makes it easier to locate and fix problems.
The technical logic behind this recommendation is: after splitting a large task into smaller ones, the context length for each subtask is shorter, allowing the model's attention to focus more on the current module's requirements, thereby reducing the probability of information omission. Meanwhile, modular development also facilitates human verification and error correction at each stage, preventing errors from accumulating and amplifying in subsequent modules. This aligns with the classic "divide and conquer" principle in software engineering.
Interestingly, Kimi K2.6 and Zhipu 5.1 are relatively older versions, with new versions expected to be released soon that may show significant improvements. The current rankings only represent this round of testing — different tasks and time points may produce different conclusions.
Key Takeaways
Related articles
AI Aggregator Platforms Tested: A Complete Guide to Using GPT 5.5 and Other Top Models for Free
A hands-on guide to using GPT 5.5, Gemini 3.1 Pro, and Grok 4.2 for free via AI aggregator platforms, covering cross-model context memory, account pool mechanisms, and key security risks.
Vibe Coding in Practice: A Junior Student Uses Cursor to Build a Multi-Agent System with 51 AI Officials Based on the Three Departments and Six Ministries Framework
A junior student uses Cursor and Vibe Coding to build a multi-agent system with 51 AI officials modeled on China's Three Departments and Six Ministries, featuring task distribution, approval workflows, and Token cost visualization.
How to Connect Codex to DeepSeek Models: Free Switching via CC Switch
Learn how to connect OpenAI Codex to DeepSeek models via CC Switch, enabling free switching between DeepSeek and GPT with complete setup and routing guide.