Single-Agent vs Multi-Agent: A Three-Step Decision Framework for Choosing the Right Architecture

A three-step decision framework for choosing between single-agent and multi-agent AI architecture
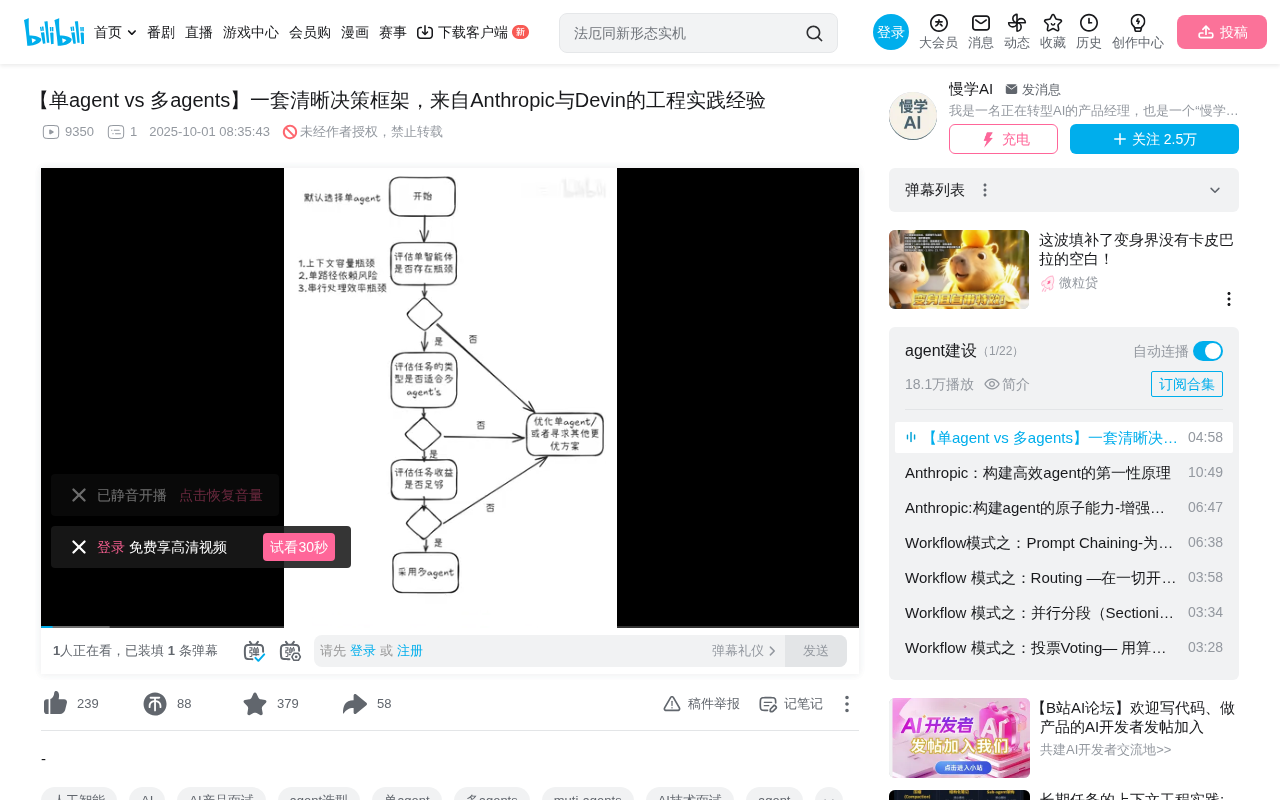
This article presents a systematic decision framework for single-agent vs multi-agent architecture: start with single-agent by default (simplicity-first principle), then apply three sequential filters—identify hard bottlenecks (context overflow, path dependency, serial efficiency); verify whether the task can be decomposed into parallelizable subtasks (highly coupled tasks are unsuitable); confirm business value can cover multi-agent's up to 15x token costs. Only when all three conditions are met should multi-agent be adopted; otherwise, optimize the single-agent approach with techniques like RAG.
In AI engineering practice, "single-agent or multi-agent" is a frequently encountered architectural decision. Many people habitually list the pros and cons of both approaches and then make a vague trade-off. But a truly insightful answer requires a systematic decision framework. Based on engineering practices from top-tier organizations like Anthropic and Devin, this article outlines a clear three-step decision process to help you make well-grounded architectural choices in real projects.
What is Agent Architecture? In AI engineering, an Agent refers to an AI system capable of autonomously perceiving its environment, formulating plans, and executing a series of actions to achieve goals. A single-agent system is powered by one large language model (LLM) with tool use capabilities to complete tasks; a multi-agent system consists of multiple collaborating AI entities that coordinate through message passing or shared state. The rise of this architectural paradigm is closely tied to the maturation of LLM tool-calling capabilities—when models can reliably call external APIs, execute code, and search the web, combining multiple such capability units to accomplish complex tasks becomes possible.
Decision Starting Point: The Single-Agent-First Principle
Before beginning any architectural discussion, establish a core thinking principle: start with single-agent architecture by default.
This philosophy stems from Anthropic's repeatedly emphasized "simplicity-first" principle—complexity should only be considered when it demonstrably improves outcomes. Single-agent architecture is the baseline, not a parallel "pick one of two" option alongside multi-agent.
This point is crucial because it fundamentally changes how you think. We're not asking "which one should I choose?" but rather "is there sufficient reason to move away from single-agent?" This mindset effectively prevents over-engineering—in real projects, many teams introduce unnecessary complexity by pursuing architectures that "look more advanced," ultimately resulting in systems that are difficult to maintain and costs that spiral out of control.
Step One: Identify Hard Bottlenecks of Single-Agent
When is there justification to consider upgrading to multi-agent? The answer: when a single agent encounters hard bottlenecks that cannot be resolved through simple optimization. These bottlenecks fall into three categories:
Bottleneck One: Context Capacity Overflow
A single agent has only one context window—its "short-term memory" is limited. For research tasks that require processing massive amounts of information—such as simultaneously analyzing content from dozens of web pages—a single agent's context window quickly gets overwhelmed, leading to information loss or severely degraded processing quality.
The Deeper Mechanism of Context Windows and Attention Decay: The context window is the maximum number of tokens an LLM can process in a single inference pass, determining the model's "working memory" ceiling. Early GPT-3 had a context window of only 4K tokens, while current mainstream models have expanded to 128K or even million-level capacities. However, window expansion doesn't mean information utilization efficiency scales proportionally. Stanford's 2023 research paper Lost in the Middle revealed a key phenomenon: when critical information is located in the middle of an ultra-long context, the model's retrieval and utilization efficiency drops significantly, while maintaining higher sensitivity to information at the beginning and end. This "attention decay" problem means that even if more information can technically be stuffed in, actual reasoning quality may suffer uneven degradation depending on information position.
Even though current large models have expanded context windows to 128K or longer, in practical engineering, excessively long contexts often come with attention decay issues ("Lost in the Middle"), where the model's utilization efficiency of information in the middle portion drops significantly.
Bottleneck Two: High Failure Risk from Single-Path Dependency
A single agent is like a detective who can only follow one lead at a time. If that path turns out to be wrong, the entire task may fail.
Here's a concrete example: researching board member information for all S&P 500 companies. A single agent might adopt a single approach to look up information, and once it encounters a website structure change or missing data, it could get stuck. A multi-agent architecture, on the other hand, can dispatch multiple "detectives," each independently investigating using different paths and strategies, greatly reducing the risk of single-point failure.
Bottleneck Three: Efficiency Bottleneck of Serial Processing
Using the same task above, if a single agent processes companies one by one, it might take hours or even longer. If business requirements demand completion within a short timeframe, this serial processing efficiency becomes an unacceptable bottleneck. At this point, multiple agents processing in parallel becomes a necessary means to improve efficiency.
Key Judgment: Only when a single agent genuinely encounters at least one of these three bottleneck categories is there sufficient reason to initiate evaluation of a multi-agent solution. But note: initiating evaluation does not equal direct adoption—two more reality filters must be passed.
Step Two: Technical Feasibility Filter
After confirming a bottleneck exists, the first question to answer is: Is this task technically suitable for a multi-agent solution?
There's only one core criterion: whether the task can be decomposed into multiple independent, parallelizable subtasks.
Task Characteristics Suitable for Multi-Agent
Take generating a market analysis report as an example. This large task can be clearly decomposed into:
- Sub-Agent A: Research major competitors' products and strategies
- Sub-Agent B: Analyze macro market trends and policy environment
- Sub-Agent C: Scrape and analyze user reviews and feedback data
Three agents work independently without interfering with each other, and finally an orchestrator consolidates and integrates the results. This is an ideal parallelizable task—low dependency between subtasks with clear interfaces.
Task Characteristics Not Suitable for Multi-Agent
Conversely, some tasks are inherently unsuitable for decomposition. A typical example is complex code writing. Code projects often require a strongly shared context with high interdependency between modules. Having multiple agents simultaneously modify a complex codebase easily produces conflicts and inconsistencies.
Devin's Engineering Practice Confirms This Judgment: Devin is an AI software engineer released by Cognition AI in 2024, considered a landmark product for autonomous agents in software development. Devin can independently complete the entire software development workflow from requirement understanding, code writing, debugging to deployment. Its architecture adopts a single-agent-primary, tool-calling-supplementary design approach—empowering the agent with access to terminals, browsers, code editors, and other tools rather than splitting into multiple collaborating agents. This design choice precisely confirms the core thesis: for highly coupled tasks like code writing that require strong shared context, a single agent with a rich toolset often outperforms multi-agent collaboration.
In such scenarios, forcibly introducing multi-agent actually increases coordination costs and reduces overall efficiency.
You can use an engineering analogy to understand this filter: it's like checking the engineering blueprints at hand to see whether the project can be subcontracted to different construction crews working independently, or must be completed by a single unified team.
Step Three: Business Value Filter
After technical feasibility is confirmed, you still need to do the math: Can the value created by this task support the high cost of multi-agent architecture?
According to Anthropic's official experience data, multi-agent architecture may consume 15 times the tokens of a typical single-agent conversation. This is a very significant cost multiplier.
Why Does Multi-Agent Token Consumption Surge? Tokens are the basic unit of measurement for LLM text processing, roughly corresponding to 3/4 of an English word or 1-2 Chinese characters. Mainstream commercial APIs (such as OpenAI, Anthropic Claude) all charge by token count. The reason multi-agent architecture token consumption can reach 15 times that of single-agent is multi-layered: first, each sub-agent call needs to carry the complete system prompt and task context; second, inter-agent communication itself generates large amounts of intermediate message tokens; finally, the orchestrator agent needs to process all sub-agent outputs and perform integration reasoning—a step whose token consumption is often underestimated. Taking Claude Sonnet as an example, if a single conversation consumes about 10K tokens, a multi-agent task can easily exceed 150K tokens, with the direct cost difference having a decisive impact on commercial viability at the order-of-magnitude level.
Beyond direct API call costs, multi-agent systems also bring additional engineering complexity:
- Development cost: Requires designing inter-agent communication protocols, task allocation strategies, and result aggregation logic
- Operations cost: System instability increases, and debugging and monitoring become more difficult
- Latency risk: Inter-agent coordination may introduce additional wait times
If a task's business value is insufficient to cover these costs, then even if technically fully feasible, you must return to the starting point and seek simpler, lower-cost workarounds. For example, through prompt optimization, introducing RAG (Retrieval-Augmented Generation), or adopting batch serial processing to get as close to the target as possible within the single-agent framework.
RAG: An Important Enhancement for Single-Agent: RAG (Retrieval-Augmented Generation) is a technical architecture that extends LLM knowledge boundaries without increasing model parameters. Its core approach is: pre-vectorize and store external knowledge bases (documents, databases, web pages, etc.), dynamically retrieve the most relevant fragments based on user queries during inference, then inject them into the context for the model to reference when generating answers. RAG effectively alleviates single-agent context capacity pressure—through precise retrieval, only the most relevant information fragments are sent into the context rather than stuffing all data in at once. When multi-agent cost-benefit analysis doesn't work out, a single agent combined with RAG can often approach multi-agent information processing capabilities at lower cost, making it a high-value degradation option in engineering practice.
Complete Decision Framework Summary
Connecting the above three steps, we get a complete decision process:
- Baseline Setting: Default to single-agent architecture (simplicity-first principle)
- Bottleneck Assessment: Check whether hard bottlenecks exist in context capacity, path dependency, or efficiency
- Technical Filter: Verify whether the task has parallel decomposition feasibility
- Value Filter: Confirm whether business value can support multi-agent's high costs
Only when all three conditions are met should multi-agent architecture be recommended.
The value of this framework lies in the fact that it's not a simple comparison checklist, but a layered decision process. It reflects thinking across three dimensions: understanding of cutting-edge technical philosophy (simplicity-first principle), pragmatic judgment on engineering implementation (technical feasibility), and clear-eyed awareness of business value (cost-benefit analysis). In actual project decisions or technical interviews, this systematic thinking approach is far more persuasive than simply listing pros and cons.
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesDemystifying Transformer: A Word-Continuation Function, Deconstructed
Understand Transformer through the lens of word continuation. Breaking down language generation into Embedding, Transformer Block, and Probability output modules for intuitive understanding.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.