Struggling to Deploy AI Agents? Engineering Is the Key to Going from Demo to Product

Engineering discipline is what separates AI Agent demos that impress from products that deliver.
With 57% of projects deploying AI Agents but 40% facing cancellation, the gap between demo and production is the industry's biggest challenge. This article explores why working prototypes fail in production due to reliability, maintainability, and deliverability issues, and presents a complete engineering methodology — from requirements analysis and graceful degradation design to non-deterministic testing paradigms — for building enterprise-grade AI applications.
A Sobering Statistic: 40% of AI Agent Projects Will Be Killed
According to a survey by the Lunchen development team covering over 1,300 professionals worldwide, 57.3% of projects have already deployed AI Agents. That number looks impressive, but the follow-up statistic is alarming — approximately 40% of AI Agent projects are expected to be canceled.
An AI Agent refers to an AI system capable of perceiving its environment, making autonomous decisions, and executing actions. Unlike simple chatbots, it's a composite system with tool-calling, multi-step reasoning, and task orchestration capabilities. The current AI Agent boom began with the explosion of projects like AutoGPT in 2023, followed by frameworks like LangChain and CrewAI that lowered the barrier to building agents, leading many enterprises to rapidly launch Agent projects. However, with 40% of projects facing the chopping block, this closely mirrors historical technology bubble cycles — on the Gartner Hype Cycle, new technologies inevitably enter the "Trough of Disillusionment" after the "Peak of Inflated Expectations," and only projects that undergo proper engineering refinement ultimately reach the "Plateau of Productivity."

Where's the problem? It's not the wrong technical approach, nor insufficient model capabilities. Rather, it's a series of engineering shortcomings exposed when large models are applied in practice: hallucinations, inconsistent output quality, slow response times, and poor timeliness.
Among these, LLM hallucination is the most representative challenge. Its root cause lies in how large language models work — they are fundamentally probabilistic next-token predictors that generate text based on statistical patterns in training data, rather than truly "understanding" facts. Hallucinations fall into two categories: factual hallucinations (fabricating non-existent facts) and faithfulness hallucinations (outputs inconsistent with given context). In enterprise applications, a single hallucination could lead to incorrect inventory decisions or compliance risks, making it essential to implement multi-layered defenses at the system architecture level through mechanisms like RAG (Retrieval-Augmented Generation), fact-checking chains, and confidence scoring.
These problems compound to directly prevent products from being truly delivered to end users.
In other words, there's a massive chasm between a Demo and a product. This chasm is known in the industry as the "last mile problem" or the "PoC-to-Production death valley." Specifically, production environments require AI applications to have: observability (monitoring inputs/outputs, latency, and cost of every LLM call through logs, metrics, and distributed tracing), security and compliance (content moderation for inputs/outputs, PII data masking, audit logs), cost control (token usage monitoring, caching strategies, model routing optimization), and deep integration with existing enterprise IT infrastructure (SSO authentication, permission management, data governance). According to McKinsey research, the success rate of AI projects going from proof of concept to full deployment is less than 20%, with the lack of engineering capability being the primary reason.
The core capability that bridges this chasm is software engineering.
Why a "Working Demo" Doesn't Equal a "Usable Product"
Many developers, after learning Prompt Engineering and mastering Agent-building frameworks, develop an illusion: I can already build AI applications.
Prompt Engineering is the technique of carefully designing input prompts to guide large models toward desired outputs, including strategies like Few-shot Learning and Chain-of-Thought reasoning. Agent-building frameworks like LangChain, LlamaIndex, and AutoGen provide out-of-the-box capabilities such as tool calling, memory management, and multi-Agent collaboration. These technologies have indeed dramatically lowered the barrier to AI application prototyping — a developer might build an Agent Demo that can converse, query databases, and call APIs in just a few hours. But these frameworks primarily solve the "functional feasibility" problem, not the "production reliability" problem — they typically lack comprehensive error recovery, load balancing, version management, and observability support.
The reality is that an Agent prototype running well locally is still a long way from an enterprise-grade usable product.
The gap manifests across three dimensions:
- Reliability: LLM outputs are inherently stochastic — the same question may yield answers of varying quality, and production environments cannot tolerate this uncertainty
- Maintainability: Without standardized architectural design, future iterations and troubleshooting become nightmares
- Deliverability: Without complete testing, monitoring, and deployment processes, products simply cannot pass enterprise acceptance criteria
This is precisely why the industry is seeing so many cases of "AI Agent projects that are easy to start but hard to land." The technology choices are fine, the model capabilities are sufficient, but what's missing is the engineering methodology to truly integrate agents into existing business systems.
AI Application Engineering: A Complete Loop from Requirements Analysis to Testing and Deployment

The core proposition of software engineering for AI applications is: How to integrate AI Agents into existing enterprise projects to solve real business problems.
This isn't purely a technical problem — it's a systems engineering challenge. Taking an intelligent warehousing system as an example, a complete AI application development process should include the following stages:
Requirements Analysis and High-Level Design
Clearly define the Agent's role in the business process — what problems it solves, which manual steps it replaces, and how it interfaces with existing systems. This step determines the success or failure of the entire project, yet it's often the most overlooked.
Detailed Design and Software Development
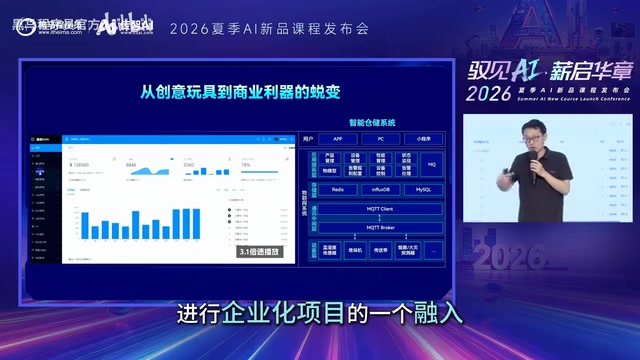
Break down the Agent's capabilities into specific functional modules, and design input/output specifications, exception handling mechanisms, and degradation strategies.
Graceful Degradation plays a crucial role in AI systems. It refers to the mechanism by which a system automatically switches to fallback options when AI components malfunction, ensuring service availability. In AI applications, degradation scenarios include: switching to backup models or cached responses when model APIs time out or become unavailable, falling back to rule engines when model outputs fail validation, and reducing output complexity when token consumption exceeds budget. A mature AI application architecture typically adopts a "human-AI collaboration" degradation pattern — when AI confidence falls below a threshold, tasks are automatically routed to human handlers rather than forcing potentially incorrect results. This design philosophy borrows from the Circuit Breaker Pattern in microservices architecture and is a quintessential example of engineering thinking applied to the AI domain.
For the LLM hallucination problem, validation and fallback logic must be introduced at the architectural level, rather than hoping the model itself will never make mistakes.
Testing and Deployment
Testing AI applications is more complex than traditional software because outputs are non-deterministic. Traditional software testing is based on deterministic assumptions: given the same input, the system should produce the same output. But LLM outputs are inherently stochastic (controlled by sampling parameters like temperature), and even with temperature set to 0, different inference engines and batching strategies may cause output variations. This requires AI applications to establish entirely new testing paradigms: assertions based on semantic equivalence rather than exact string matching, quality assessment based on statistical distributions (e.g., accuracy must reach 95%+ across 1,000 calls), automated evaluation pipelines using LLM-as-Judge, and Red Teaming for edge cases and adversarial inputs. The emerging industry consensus is that AI applications need "continuous evaluation" rather than one-time testing.
A dedicated evaluation system must be established, covering multi-dimensional metrics including accuracy, consistency, and response latency, to ensure product quality meets deliverable standards.
The Fundamental Difference Between Junior and Senior Developers

After completing the engineering phase and being able to independently develop a complete AI application, one can be considered a junior development engineer. But there remains a fundamental gap between this level and senior developers.
This gap isn't about how many projects you've completed, but rather: When an enterprise encounters truly complex problems, can you deliver effective solutions?
This requires extensive accumulation of industry-specific experience. Different industries have different business logic and face different AI deployment challenges. For example, the financial industry demands extremely high compliance and explainability in outputs, the healthcare industry requires strict safety guardrails and human review mechanisms, and manufacturing is more concerned with real-time integration with industrial control systems. Only by seeing enough cases and stepping on enough landmines can you quickly produce reliable solutions when facing new problems.
Final Thoughts
The biggest contradiction in the AI Agent space today isn't "can we build it" but "can we actually use it." The key to bridging this gap is engineering thinking. Rather than chasing the latest models and frameworks, it's better to build a solid foundation in software engineering. After all, getting a Demo to work only takes a few days, but keeping an AI application running stably in production — that's where the real hard work lies.
Related articles
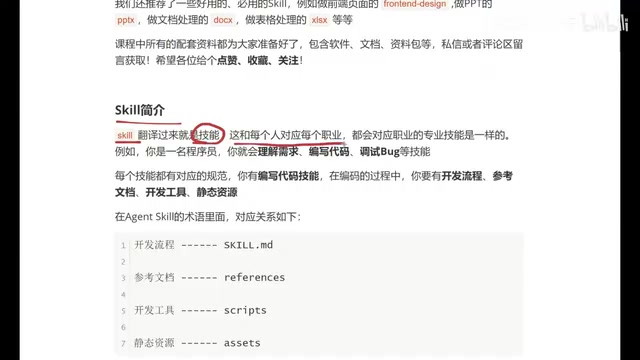
Beginner's Guide to Agent Skills: Structure Breakdown & Custom AI Skill Development
A deep dive into Agent Skill's core concepts and internal structure, covering skill.md, references, scripts, and assets with a restaurant poster Skill example.
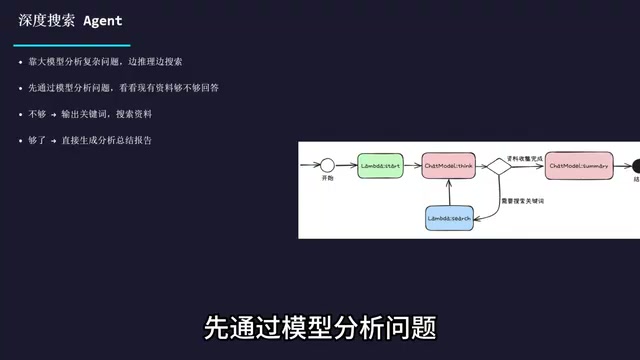
Complete Guide to Commercial AI Agent Development: From Requirements Analysis to Production Deployment
Complete guide to commercial AI agent development from scratch, covering requirements analysis, architecture design (ReAct framework, deep search, intent recognition), hands-on Coze platform implementation, workflow creation, and production deployment.
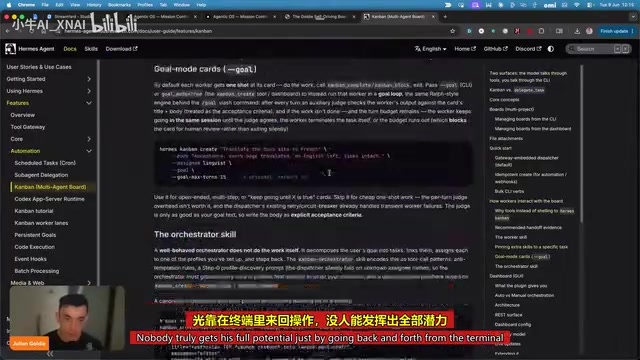
Hermes AI Kanban: A Five-Layer Autonomous Architecture for Fully Automated Delivery from Idea to Finished Product
Deep dive into Hermes Kanban 2.0's five-layer autonomous architecture covering intelligent planning, human approval gates, multi-agent execution, and Obsidian integration for fully automated delivery.