The Fatal Flaw of AI Voice Synthesis: Why the Absence of Ambient Sound Makes Synthetic Speech Sound Instantly Fake
AI voices sound fake not because of the voice itself, but because they lack real-world ambient sound and reverb.
Despite rapid advances in AI voice synthesis timbre and emotional expression, the absence of background environmental sounds and spatial reverb remains the technology's most revealing flaw. Human hearing subconsciously evaluates acoustic environments, and perfectly clean audio triggers an 'unnatural' alarm. Solving this requires native acoustic fusion during generation rather than simple post-processing noise overlay.
An Overlooked Element of Realism
In an era of rapid advancement in AI voice synthesis technology, from ElevenLabs to various voice AI platforms, synthetic speech continues to improve in timbre, intonation, and emotional expression. ElevenLabs was founded in 2022 by former Google and Palantir engineers and quickly became a benchmark company in the AI voice synthesis space. Its core technology is based on deep learning neural network speech synthesis models that can clone a speaker's vocal characteristics from just a small number of voice samples. Unlike traditional concatenative synthesis (splicing pre-recorded phoneme segments) and parametric synthesis (generating waveforms through acoustic parameters), modern neural network TTS systems like VALL-E and Tortoise-TTS use end-to-end generation approaches, mapping directly from text to high-fidelity audio waveforms. These systems have achieved near-human levels in prosody naturalness, emotional expression, and multilingual support, but their training paradigms are almost entirely built on the assumption of "clean speech."
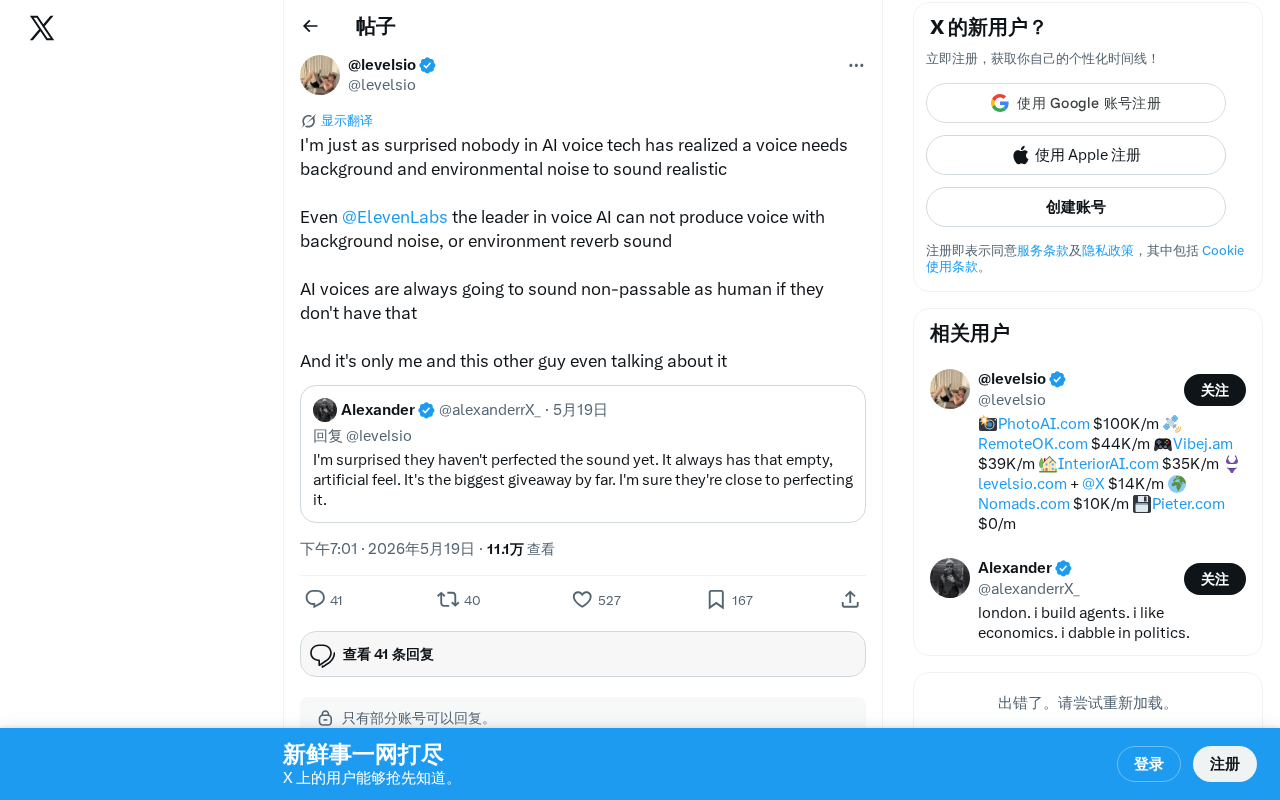
However, a tech observer raised a thought-provoking point on Twitter: The reason AI voice still can't fully pass as real isn't about the voice itself — it's the lack of background ambient sound.
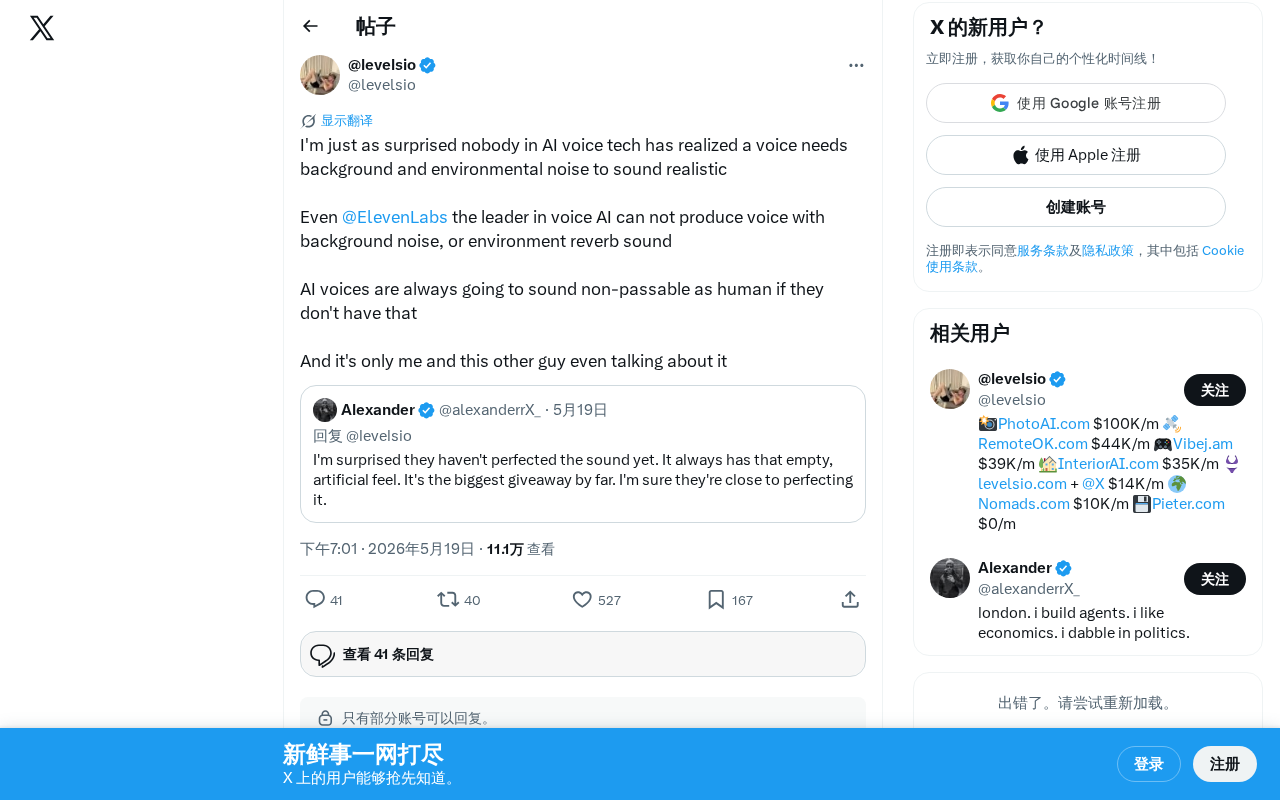
This user bluntly pointed out that even ElevenLabs, the leader in voice AI, cannot generate speech with background noise or environmental reverb. Yet this is precisely an indispensable characteristic of human speech in real-world scenarios.
Why Is Ambient Sound Key to Voice Realism?
The Subconscious Judgment Mechanism of Human Hearing
When we hear a piece of speech, our brain isn't just processing linguistic content. Our auditory system simultaneously analyzes:
- Spatial information: Is the sound indoors or outdoors? How large is the room?
- Environmental cues: Is there air conditioning humming, keyboard clicking, distant traffic?
- Reverb characteristics: Do the reflection and decay patterns of the sound conform to physical space rules?
These pieces of information collectively form the basis of our judgment about "real human voice." This phenomenon has deep theoretical foundations in the field of Psychoacoustics. The human auditory system, through millions of years of evolution, has developed extremely sophisticated spatial hearing capabilities. The brain's auditory cortex not only processes the semantic content of speech but also constructs three-dimensional acoustic scenes through Interaural Time Differences (ITD), Interaural Level Differences (ILD), and spectral cues. This ability is known as "Auditory Scene Analysis," systematically described by psychologist Albert Bregman in 1990. Research shows that humans can detect environmental changes as low as -6dB signal-to-noise ratio in an unconscious state, meaning that even when we're not actively paying attention to background sounds, the brain is continuously evaluating the plausibility of the acoustic environment.
A completely "clean" piece of speech — with no background noise, no room reverb, no environmental atmosphere — actually triggers the brain's "unnatural" alarm.
The Recording Studio Paradox: Too Perfect Actually Reveals Artificial Origins
Ironically, the "perfect clarity" that AI voice synthesis strives for is precisely what exposes its artificial nature. Even human voices recorded in professional studios retain extremely faint noise floors and room characteristics. And human voices in everyday conversation are filled with environmental information — the clinking of cups in a café, the low-frequency hum of an office, the wind on a street.
This is like the "uncanny valley effect" in CGI — the closer something gets to reality while missing certain subtle details, the more unsettling it becomes. The Uncanny Valley effect was originally proposed by Japanese roboticist Masahiro Mori in 1970 to describe the discomfort people feel toward entities that are close to but not quite human. This concept was initially applied to the visual domain — robot appearances and CGI characters — but in recent years researchers have found it equally applicable to auditory perception. A 2019 study published in Computers in Human Behavior confirmed that when synthetic speech is highly realistic in certain dimensions (such as timbre) but has subtle deviations in other dimensions (such as micro-prosodic variations and breathing patterns), listeners' discomfort is actually stronger than with obviously mechanical speech. The absence of ambient sound is a classic manifestation of this "almost perfect but not quite" phenomenon.
Technical Challenges and Breakthrough Directions
Current TTS System Limitations with Ambient Sound
Current mainstream TTS (Text-to-Speech) systems are typically trained using intentionally denoised clean speech data. The original intent is to improve speech clarity and controllability, but the side effect is that generated speech lacks the "texture" of the real world.
The training data processing pipeline of modern TTS systems typically includes multiple denoising stages. First, Voice Activity Detection (VAD) is used to remove silent segments, then spectral subtraction or deep learning-based denoising models (such as Meta's Denoiser, NVIDIA's CleanUNet) remove background noise, and finally loudness normalization and frequency equalization are applied. This pipeline originates from best practices in the Automatic Speech Recognition (ASR) field — clean training data significantly improves model convergence speed and output stability. However, this also means the model has never "seen" the acoustic patterns of speech coexisting with ambient sound in the real world, and naturally cannot generate such patterns. Mainstream TTS training datasets like LibriTTS and VCTK have all undergone strict studio environment control or post-production denoising.
From a technical architecture perspective, solving this problem is not impossible, but breakthroughs are needed in the following areas:
- Ambient sound modeling: Incorporating background noise as a controllable parameter in the generative model
- Spatial acoustic simulation: Calculating reverb, early reflections, and other acoustic characteristics based on a defined virtual space
- Dynamic noise layers: Generating an ambient sound bed that naturally varies over time, rather than simply overlaying static noise
Regarding technical pathways for ambient sound modeling, there are already multiple cross-disciplinary technologies to draw from. In spatial acoustic simulation, there are mature Room Impulse Response (RIR) simulation technologies, such as ray-tracing-based acoustic simulation software ODEON and CATT-Acoustic, as well as Google Research's neural network-based RIR generator. In environmental noise generation, Diffusion Models have demonstrated the ability to generate realistic ambient sounds, such as AudioLDM and Make-An-Audio audio generation models. The key challenge lies in how to organically integrate these technologies with TTS systems, so that ambient sound is not applied as a post-processing layer but interacts with the speech signal in a physically plausible way during the generation stage.
Simple Noise Overlay vs. Native Acoustic Fusion
Some might say, why not just add background noise to AI speech in post-production? But this simple audio overlay is fundamentally different from the natural fusion of sounds in a real environment. In real environments, there are complex acoustic interactions between human voice and ambient sound — the voice is altered by the environment, and ambient sounds are briefly masked by the act of speaking. This dynamic interactive relationship is very difficult to perfectly simulate through post-processing.
From a physical acoustics perspective, this interaction follows multiple principles. First is the "Masking Effect": when a person speaks, the stronger speech signal partially masks weaker ambient sounds in both time and frequency, and this masking has forward and backward temporal characteristics. Second is the "Lombard Effect": speakers unconsciously adjust their volume, speaking rate, and articulation clarity based on ambient noise levels — in a noisy bar, people involuntarily raise their voices and slow their speech. Additionally, human voice undergoes a convolution relationship with the environment during propagation — sound reaches the microphone after being reflected by walls, absorbed by furniture, and attenuated by air, and during this process the spectral characteristics of the speech are "colored" by the environment. Simple audio overlay cannot reproduce these physical interactions because it assumes speech and ambient sound are independent signal sources, when in reality they are deeply coupled.
Implications for the AI Voice Industry
Though seemingly simple, this observation reveals an important blind spot in AI voice technology development. While the entire industry pursues clearer, purer synthetic speech, perhaps it's time to think in reverse: The key to realism isn't perfection, but just the right amount of "imperfection."
As this observer noted, almost no one is discussing this issue right now. This is both a neglected research direction and potentially the key entry point for the next generation of AI voice technology to achieve a breakthrough. For teams dedicated to making AI voice "pass the Turing test," perhaps it's time to shift attention from the voice itself to the "world" in which the voice exists.
Key Takeaways
Related articles
AI Aggregator Platforms Tested: A Complete Guide to Using GPT 5.5 and Other Top Models for Free
A hands-on guide to using GPT 5.5, Gemini 3.1 Pro, and Grok 4.2 for free via AI aggregator platforms, covering cross-model context memory, account pool mechanisms, and key security risks.
Vibe Coding in Practice: A Junior Student Uses Cursor to Build a Multi-Agent System with 51 AI Officials Based on the Three Departments and Six Ministries Framework
A junior student uses Cursor and Vibe Coding to build a multi-agent system with 51 AI officials modeled on China's Three Departments and Six Ministries, featuring task distribution, approval workflows, and Token cost visualization.
How to Connect Codex to DeepSeek Models: Free Switching via CC Switch
Learn how to connect OpenAI Codex to DeepSeek models via CC Switch, enabling free switching between DeepSeek and GPT with complete setup and routing guide.