Vibe Coding Methodology for Non-Programmers: Building an AI Development Loop with Automated Testing + Knowledge Accumulation
Non-programmers can build reliable AI apps using automated testing and knowledge accumulation.
This article presents a practical Vibe Coding methodology for non-programmers, centered on two pillars: end-to-end automated testing and knowledge accumulation. By having AI generate test cases, self-verify, and self-repair, non-technical developers can dramatically reduce manual debugging. Combined with systematic knowledge documentation that enriches the AI's project context, this approach creates a sustainable development loop where quality is maintained without understanding every line of code.
Introduction: The Feature Works, But Does It Actually Run?
Non-programmers who use AI for Vibe Coding almost all run into the same problem: the feature gets built, but does it actually work properly? The traditional approach is to manually debug each feature one by one — time-consuming, exhausting, and easy to miss things.
Vibe Coding was a concept coined by OpenAI co-founder Andrej Karpathy in February 2025. The core idea is that developers no longer write and review code line by line. Instead, they describe requirements in natural language, let AI generate the code, and focus only on whether the final result meets expectations. This approach dramatically lowers the barrier to software development, enabling product managers, designers, entrepreneurs, and other non-technical people to independently build fully functional applications. But it also introduces a core challenge — when you don't understand the code details, how do you ensure system reliability?
Bilibili creator Paul shared in a video how, after completing five core features in a single day, he leveraged end-to-end automated testing and knowledge accumulation to let AI verify and fix issues on its own, dramatically reducing manual debugging effort. This methodology is a systematic response to the challenge above and offers tremendous reference value for all non-technical people writing code with AI.
Five Features in One Day: The Testing Challenge of High-Intensity Development
Paul completed five core features in a single day:
- BGM background music functionality
- Manual dialogue editing functionality
- Visual character art interaction functionality
- Multi-character live recording functionality
- TTS engine switch (from Doubao back to Alibaba Cloud)
The TTS (Text-to-Speech) engine switch reflects the competitive landscape of China's domestic TTS service market. Doubao is an AI product under ByteDance, with TTS capabilities based on ByteDance's speech synthesis technology. Alibaba Cloud offers speech synthesis services based on Tongyi Lab's technology (such as CosyVoice). Different TTS engines have their own strengths and weaknesses across dimensions like voice naturalness, multilingual support, emotional expression, latency, and pricing. Developers frequently need to switch between engines based on quality and cost — which is why Paul developed and tested this as a standalone feature module.
With so many features going live simultaneously, manually testing each one the traditional way would be an enormous and error-prone effort. Paul admitted this was his previous approach — "it was exhausting." But with the DeepSeek V4 and Claude combination, automated testing has become "relatively mature and ready to use."
DeepSeek V4 is a large language model from DeepSeek, renowned for its exceptional cost-effectiveness — its API pricing is far lower than comparable models from OpenAI and Anthropic, which is why Paul describes it as "high volume at low cost." Claude is a large language model developed by Anthropic that excels at code generation and long-context understanding. The Claude 3.5/4 series in particular is widely regarded as one of the strongest coding assistant models available. Using both together is a common strategy in the Vibe Coding community: DeepSeek handles large volumes of routine tasks to control costs, while Claude handles complex architectural design and testing logic to ensure quality — achieving a balance between cost and effectiveness.
End-to-End Automated Testing: Let AI Do Its Own Acceptance Testing
What Is End-to-End Testing (E2E Testing)?
End-to-end testing means AI simulates real user actions on a webpage — clicking buttons, entering content, switching pages — then automatically checks whether the frontend and backend responses meet expectations. It's like having a tireless tester who repeatedly verifies that every feature works correctly.
From a technical perspective, end-to-end testing sits at the very top of the software testing pyramid. The pyramid, from bottom to top, consists of: unit tests (verifying the correctness of individual functions or modules), integration tests (verifying that multiple modules work together correctly), and end-to-end tests (verifying complete user operation flows). E2E tests sit at the top because they most closely mirror real user scenarios, but they're also the most time-consuming and complex. Common E2E testing frameworks include Playwright, Cypress, and Selenium, which can launch real browsers and simulate mouse clicks, keyboard input, page navigation, and more. In AI-assisted programming scenarios, large language models can automatically generate these test scripts based on feature descriptions — something that previously required professional QA engineers spending days to complete.
The Specific Workflow
Paul's approach is very straightforward: after completing knowledge accumulation, he gives AI a clear directive — "Go write end-to-end test cases for me, and they must cover all the changes in this batch."
The AI then executes the following steps:
- Load relevant skill documents, guardrail rules, solution strength configurations, etc.
- Collect code and documentation information
- Read the skill files generated during knowledge accumulation
- Automatically generate test cases (this time producing 8 test scenarios and 30 test points)
Paul emphasizes that he only cares about one thing — test coverage. "As long as you cover everything, I don't care how you implement the rest. Even if you explain it to me, I won't understand it anyway, so I'll just look at the results." Test coverage is the core metric for measuring test quality — it represents what percentage of code paths and functional scenarios the test cases cover. For non-programmers, this is both an intuitive and effective quality control dimension — you don't need to understand how the tests are written, you just need to confirm that "all features have been tested."
The Iterative Testing Loop
The entire testing workflow forms an efficient closed loop:
- AI supplements test scenarios → 2. Run tests → 3. AI automatically fixes failed items → 4. Manual spot-check verification
If manual testing still reveals issues, Paul's strategy isn't to fix things himself but to PV (Performance Review) the AI: "Your test cases are poorly written. Why didn't you test this part? Why did this problematic area still pass? What's the actual reason?"
The long-term value of this approach is that the next time any change is made anywhere, running the full end-to-end test suite will automatically cover all previously problematic areas. "Generally, the bugs we fix tend to reappear," and end-to-end testing is the best safety net. In software engineering, this phenomenon is called a "regression bug" — modifying one piece of code can unexpectedly break another previously working feature. The core value of end-to-end testing is precisely as an automated safeguard for regression testing, ensuring that each code change doesn't introduce new problems.
Knowledge Accumulation: Reducing AI Errors at the Source
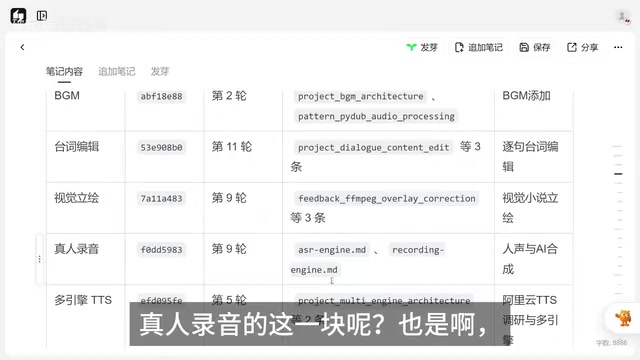
Accumulate Knowledge After Every Feature
After completing each feature, Paul has the AI perform knowledge accumulation — organizing key information from the development process into documents and storing them in the system module's skill directory.
The technical essence of this practice is closely related to the RAG (Retrieval-Augmented Generation) mechanism widely used in the AI field today. The core idea of RAG is: before a large language model generates a response, it first retrieves relevant document fragments from an external knowledge base and injects them as context into the prompt, allowing the model to reason based on accurate project information rather than "hallucinating" from generic training data. What Paul does with knowledge accumulation is essentially continuously enriching this project-specific knowledge base, making the AI's understanding of the system increasingly deep and accurate.
Here's the accumulation status for the five features:
| Feature Module | Accumulation Method |
|---|---|
| BGM | First round completed the feature, second round did knowledge accumulation |
| Dialogue Editing | Accumulated after multiple Q&A rounds |
| Visual Character Art | Accumulated after interaction completion |
| Live Recording | Accumulated after development |
| Multi-Character Engine | Accumulated after development |
Why Is Knowledge Accumulation Important?
After knowledge accumulation is complete, the memory index needs to be refreshed — meaning the document embeddings in the vector database are updated to ensure the AI can retrieve the latest system architecture and feature implementation details in subsequent conversations. This way, the AI's understanding of the entire system becomes clearer in future development, and information retrieval becomes more accurate. More critically, this accumulated knowledge directly serves the writing of end-to-end test cases — the AI can design more comprehensive test coverage plans based on a complete understanding of the system.
Without knowledge accumulation, AI tends to suffer from "context loss" when facing complex projects: it might forget previous architectural decisions or not understand dependencies between modules, generating solutions that conflict with existing code. Knowledge accumulation systematically solves this problem.
The Three Power Moves of Non-Programmer Vibe Coding
Paul summarized the core strategies for non-technical people doing AI development:
Power Move #1: Ask Thoroughly (Preventive Strategy)
Avoid errors at the source. For methods and implementation logic written by AI, ask questions about anything you don't understand — once you understand it clearly, problems are unlikely to occur. The essence of this strategy is leveraging the large language model's "explanation capability" to compensate for your own technical knowledge gaps — you don't need the ability to judge code quality yourself, but you can expose potential issues in a solution through persistent questioning.
Power Move #2: Refactor (Curative Strategy)
If you've asked thoroughly but still encounter frequent strange issues, refactor decisively. Don't keep patching bad code — let AI reorganize the code structure. In software engineering, "technical debt" is a classic concept — low-quality code written for quick feature delivery continuously generates additional maintenance costs in subsequent development. Refactoring is proactively paying down technical debt. While it may seem like wasted time in the short term, it significantly reduces system complexity and error probability in the long run.
Power Move #3: End-to-End Testing (Safeguard Strategy)
As the ultimate safety net, ensure all features work properly after every change. The three power moves form a complete quality assurance system: Prevention (ask thoroughly) → Cure (refactor) → Safety net (test), progressively layered to minimize the quality risks non-programmers face in AI programming.
Token Consumption: The Cost Reality for Non-Programmers
Paul candidly points out that this method's Token consumption is roughly 5 to 10 times higher or even more than a programmer's, because non-technical people are essentially "brute-forcing miracles through massive Token usage."
Tokens are the basic unit of measurement for how large language models process text, roughly equivalent to one Chinese character or about 3/4 of an English word. Every AI conversation consumes Tokens for both the input prompt and the output response, and API providers charge by Token count. Non-programmers consume more Tokens for multiple reasons: first, more conversation rounds are needed to clarify requirements and understand solutions; second, knowledge accumulation and test generation themselves require substantial context input; third, AI may need to try multiple approaches when fixing bugs.
But Paul considers this entirely acceptable — DeepSeek offers "high volume at low cost" with extremely low pricing. Taking DeepSeek V3 as an example, its input price is approximately 1 RMB per million Tokens. Even with 10x consumption, the API cost for completing a moderately complex project might only be tens to hundreds of RMB — far less than hiring a professional developer. With AI API prices continuing to decline, trading Tokens for time and expertise is the most rational strategy for non-programmers.
Conclusion: Building a Self-Verifying AI Development Loop
This "knowledge accumulation + end-to-end testing" workflow is essentially building a development loop where AI can self-verify and self-repair. For non-programmers, this means:
- No need to understand the implementation details of every line of code
- No need to manually debug each feature one by one
- Only need to focus on test coverage and final results
- Continuously improve AI's testing quality through the PV mechanism
The deeper significance of this methodology is that it redefines the role of "developer" — from code writer to AI manager and acceptance tester. Your core competency is no longer writing correct code, but asking the right questions, establishing effective verification mechanisms, and continuously accumulating project knowledge.
As AI programming tools continue to mature, "knowing how to ask, how to verify, and how to accumulate knowledge" is becoming more important than "knowing how to write code."
Related articles
Python Excel Automation in Practice: Data Filtering and Categorization with Pandas
Learn how to use Python Pandas to automate Excel data filtering and categorization. Core code is just 6-8 lines — handle massive datasets effortlessly.
What Happens to Developer Jobs When AI Writes 80% of the Code? A Deep Dive into Anthropic's Landmark Report
Anthropic's latest report reveals over 80% of its codebase is AI-written and engineer output has grown 8x. A deep analysis of AI's impact on software development, the taste moat, AI bubble stages, and loop engineering.
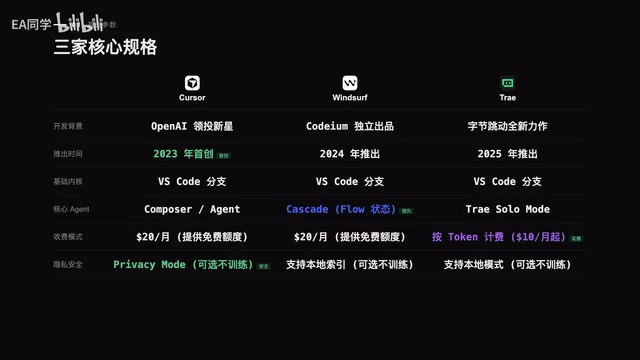
Cursor vs Windsurf vs Trae: An In-Depth Comparison of Three Major AI IDEs
A comprehensive comparison of Cursor, Windsurf, and Trae across five dimensions including coding, Agent autonomy, and pricing, with detailed scores and recommendations.