Vue3 + SpringBoot in Practice: A Full-Stack AI Travel Recommendation Assistant Explained
A beginner-friendly full-stack AI travel assistant built with Vue3, SpringBoot, and LLM integration.
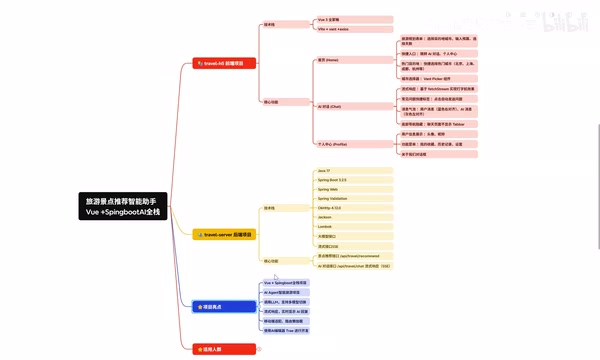
This tutorial walks through building an AI-powered travel recommendation assistant using Vue3 and Java SpringBoot. The H5 app features intelligent itinerary planning and AI conversational interaction powered by LLM APIs. Covering Prompt Engineering, AI Agent patterns, streaming responses, and full-stack architecture, it's designed for beginners looking to gain practical full-stack + AI development experience for their resumes.
Project Overview: A Beginner-Friendly Full-Stack AI Project
As AI technology rapidly permeates the industry, demand for professionals with combined "full-stack + AI" skills continues to grow. Bilibili creator Alan shared a full-stack project designed for beginners — an AI-Powered Travel Recommendation Assistant built with Vue3 + Java SpringBoot, integrated with LLM capabilities to deliver an H5 application featuring intelligent itinerary planning and AI-powered conversations.
The project has a clear purpose: helping frontend developers learn Java to go full-stack, or backend developers learn frontend to go full-stack, while gaining hands-on AI project experience. For anyone looking to bolster their resume with a solid project, this is a practical case study worth exploring.
Core Features: Smart Recommendations & AI Chat
Intelligent Travel Itinerary Planning
The homepage features a travel assistant interface where users input parameters like destination city, number of travel days, and budget. The system passes this information to the backend LLM for processing, automatically generating a detailed travel itinerary.
For example, if a user selects "Beijing" as the destination, the AI will plan daily sightseeing routes, dining suggestions, and time schedules based on the given duration and budget constraints. Behind this feature lies frontend form interaction, backend API design, and LLM Prompt Engineering — making it an excellent end-to-end learning case.
It's worth diving deeper into the core principles of Prompt Engineering. Prompt Engineering refers to the practice of carefully designing input prompts for large language models to guide them toward generating high-quality, expected outputs. In the travel itinerary planning scenario, a good Prompt needs to include a clear role definition (e.g., "You are a professional travel planner"), structured input parameters (destination, duration, budget), output format requirements (e.g., JSON format or day-by-day lists), and constraints (e.g., budget limits, attraction opening hours). Common Prompt techniques include Few-shot Learning (providing examples for the model to learn output patterns), Chain of Thought (guiding the model through step-by-step reasoning), and layered design of System Prompts and User Prompts. Prompt quality directly determines the user experience of AI features — minor wording adjustments can lead to dramatically different outputs, making Prompt tuning an essential part of AI application development.
AI Conversational Interaction
The second core feature is an AI chat page where users can ask travel-related questions just like using ChatGPT. For instance, typing "What are the must-visit attractions in Beijing?" will prompt the LLM to return structured recommendations.
This feature involves real-time frontend-backend communication, LLM API integration, and conversation context management. For those interested in learning about AI Agent development patterns, this is a very intuitive entry point.
AI Agent is one of the core paradigms in modern LLM application development, going beyond simple "input-output" Q&A. An Agent typically uses a large language model as its "brain," combined with a perception module (receiving user input), a planning module (breaking down task steps), a memory module (maintaining conversation history and context), and a tool-calling module (e.g., search engines, database queries, API calls). In this project, the travel recommendation assistant can be viewed as a lightweight Agent: it receives the user's travel requirements, calls the LLM for itinerary planning (planning capability), and maintains contextual coherence during conversations (memory capability). More complex Agent architectures like the ReAct (Reasoning + Acting) pattern allow models to proactively call external tools during reasoning to fetch real-time information — such as live weather data or attraction ticket prices — generating more accurate and practical recommendations.
Personal Center Module
The project also includes a "My Profile" page for user information management. While relatively simple in functionality, it completes the application's user system, making the project closer to a real enterprise-level product.
Tech Stack & Architecture Deep Dive
Frontend: The Vue3 Ecosystem
The frontend is built with Vue3, currently the mainstream choice for frontend development in China. Compared to Vue2, Vue3 offers significant improvements in performance, TypeScript support, and the Composition API — all frequently required skills in job postings. The entire project focuses on H5 mobile pages, making it ideal for getting started with mobile development.
Looking deeper, Vue3's Composition API represents a major paradigm shift from Vue2's Options API. The Options API organizes code by options like data, methods, and computed — when component logic gets complex, code for the same feature ends up scattered across different options, making maintenance difficult. The Composition API allows developers to organize code by logical concerns, using the setup() function or the <script setup> syntax sugar to group related reactive state, computed properties, and methods together, greatly improving code readability and reusability. Additionally, Vue3's underlying reactivity system uses Proxy instead of Vue2's Object.defineProperty, resolving long-standing pain points like the inability to detect property additions/deletions on objects or array index changes, with notable performance improvements. Combined with Vite's instant hot module replacement, the development experience has taken a quantum leap.
Backend: Java SpringBoot
Java SpringBoot serves as the backend framework, handling API development, business logic, and LLM integration. SpringBoot's auto-configuration and rapid startup features lower the barrier to backend development, making it ideal for the backend portion of full-stack projects.
SpringBoot's core design philosophy is "Convention over Configuration." Through the @EnableAutoConfiguration annotation and the spring.factories mechanism, it automatically scans dependencies on the classpath at startup and intelligently determines which Beans need to be created and injected based on conditional annotations (such as @ConditionalOnClass and @ConditionalOnMissingBean). For example, when an H2 database driver is detected on the classpath, SpringBoot automatically configures an in-memory database connection without any manual XML configuration. This mechanism reduces the massive boilerplate configuration code in traditional Spring projects to nearly zero — developers only need minimal customization in application.yml to launch a fully functional web service. For full-stack projects, this means backend developers can focus more on business logic and AI integration rather than infrastructure setup.
AI LLM Integration
The project's biggest highlight is its AI Agent integration. By connecting the backend to LLM APIs, it delivers two major AI features: smart recommendations and conversational interaction. This combination of "traditional full-stack + AI capabilities" is exactly the skill set currently in high demand.
When integrating LLM APIs, Streaming Response is a key technique for enhancing user experience. Traditional HTTP request-response patterns require waiting for the LLM to fully generate all content before returning — users might wait several seconds or even longer to see results. Streaming responses, based on Server-Sent Events (SSE) or WebSocket protocols, allow the server to push content to the frontend in real-time as the LLM generates it token by token, so users see text appearing progressively like a typewriter — exactly the interaction experience of ChatGPT. On the implementation side, the frontend needs to use the EventSource API or fetch's ReadableStream to handle streaming data, while the backend needs to forward the LLM SDK's streaming callbacks as SSE event streams. Token management is also an important consideration — each API call consumes Tokens (the LLM's billing unit), requiring backend implementation of Token usage tracking, rate limiting, and cost control mechanisms.
Target Audience & Learning Value

Three Types of Target Learners
- Complete Beginners: Those who've just finished learning a programming language and want to solidify their knowledge through a complete project while getting exposure to AI development
- Frontend Developers Going Full-Stack: Those with Vue or other frontend experience who want to learn Java backend development to round out their full-stack capabilities
- Backend Developers Going Full-Stack: Those with Java backend experience who want to learn Vue3 frontend development to achieve full-stack coverage
Why This Project Boosts Your Resume
From a project experience perspective, this project covers at least three interview-worthy highlights:
- Full-Stack Development Skills: Vue3 + SpringBoot frontend and backend tech stack
- AI Project Experience: LLM integration and Agent development practice
- Complete Product Thinking: End-to-end workflow from requirements analysis to feature implementation
In today's job market, AI-related project experience is increasingly becoming a bonus — or even a requirement — for more and more positions.
Project Resources
The project comes with comprehensive development documentation covering project description, environment setup, frontend and backend tech stack explanations, and detailed walkthroughs of key code sections. The entire tutorial takes a hands-on approach, effectively flattening the learning curve.
Summary: A High-ROI Project for Getting Started with Full-Stack + AI Development
Although this AI Travel Recommendation Assistant is modest in scope, it's small but complete. It covers the core full-stack development pipeline:
Frontend Page Interaction → Backend API Processing → LLM API Call → Result Rendering
For anyone looking to quickly get started with full-stack + AI development, this is a project with an excellent effort-to-reward ratio.
However, it's worth noting that enterprise-level AI projects typically involve more complex architectural considerations, such as streaming responses, Token management, multi-turn conversation memory, and vector database retrieval.
Among these, vector database retrieval is a core component of the RAG (Retrieval-Augmented Generation) architecture and is worth exploring further. LLMs' knowledge is limited to their training data cutoff, and they cannot directly access private enterprise data. RAG works by retrieving relevant document fragments from an external knowledge base before model inference, injecting them as context into the Prompt, enabling the model to generate answers based on the most current and relevant information. Vector databases (such as Milvus, Pinecone, and ChromaDB) store high-dimensional vector representations of text transformed by Embedding models and support efficient similarity search. In a travel scenario, attraction descriptions, user reviews, and real-time travel guides can be vectorized and stored in the database. When a user asks a question, the system first retrieves the most relevant information fragments, then passes them to the LLM to generate personalized recommendations, significantly improving answer accuracy and timeliness.
After completing this project, it's recommended to dive deeper into these areas to enhance the technical depth of your projects and the competitiveness of your resume.
Related articles
OpenCode In-Depth Review: Hands-On with a Free Open-Source AI Coding Assistant
In-depth review of OpenCode, an open-source AI coding assistant. Covers its three-layer architecture, setup, building a to-do app, and model comparisons with DeepSeek Flash and more.

How Wayfair Uses GPT Models to Process a Catalog of 40 Million Products
Deep dive into how Wayfair uses OpenAI GPT models for catalog enrichment across 40M SKUs, covering technical implementation, AI solutions for non-standardized product classification, and implications for e-commerce.
Codex AI Coding Agent Explained: What's the Real Difference from ChatGPT?
Deep dive into OpenAI's Codex coding agent, comparing Codex vs ChatGPT in programming scenarios and how AI agents are reshaping software development.