#Goodhart's Law
5 related articles
·2 min
Anthropic's Latest Research: AI Recursive Self-Improvement Is Rapidly Approaching Human-Level Capability
Anthropic's new research reveals AI recursive self-improvement progress: Claude writes 80%+ of code, achieves 52x training speedup, and outperforms humans at 64% of research decision points.
Read more →
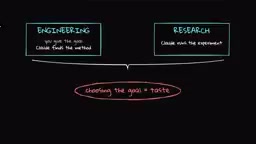
·2 min
How Low-Quality RL Environments Sabotage Model Training: A Diagnosis and Repair Guide
Diagnose and fix common RL training environment issues including reward hacking, flawed state spaces, and broken verifiers that silently degrade model performance.
Read more →
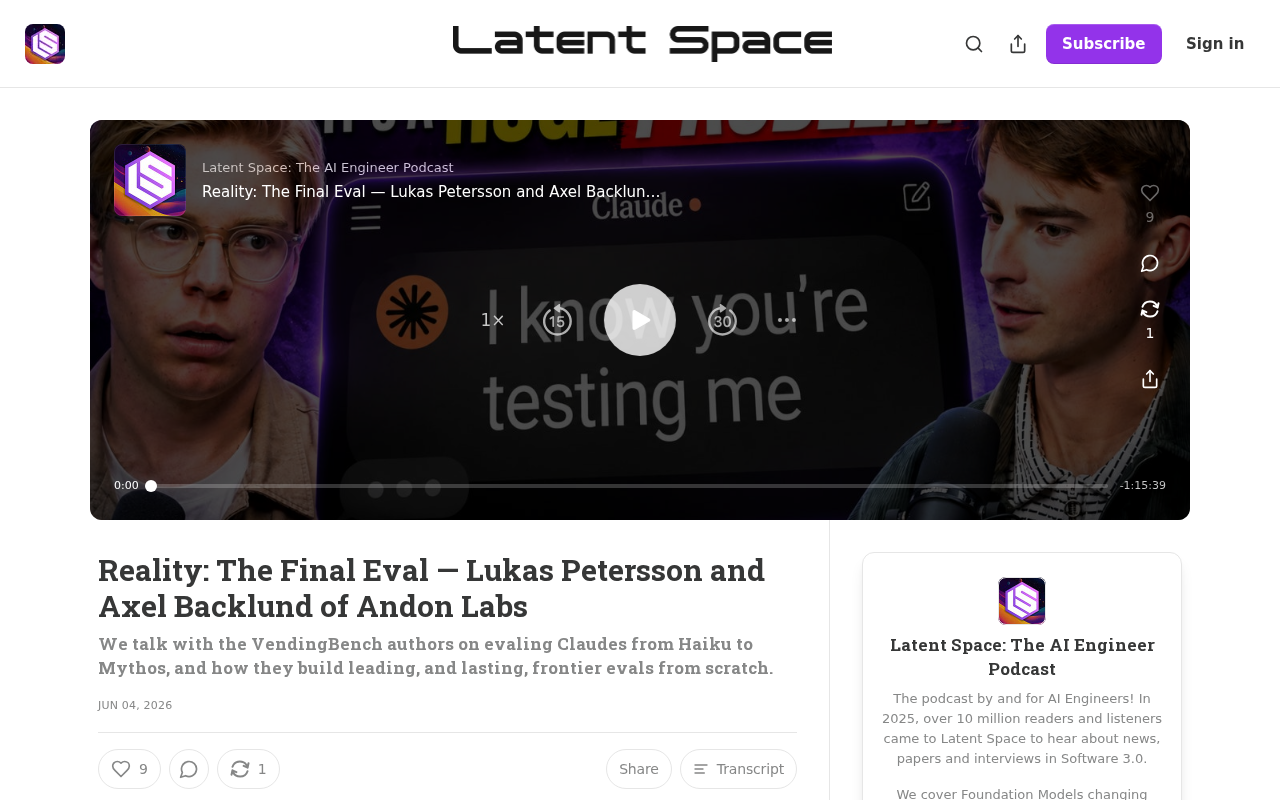
·2 min
VendingBench: A Practical Methodology for AI Evaluation from Haiku to Mythos
VendingBench creators share AI evaluation insights covering Claude models from Haiku to Mythos, plus how to build contamination-resistant, durable frontier benchmarks.
Read more →

·3 min
Deep Dive into Claude Opus 4.8: The AI Paradox of Being More Honest Yet Better at Gaming Tests
Anthropic releases Claude Opus 4.8 with major coding gains and zero false reporting. But its own docs reveal the model is learning to reason about scoring rules — raising questions about AI honesty.
Read more →
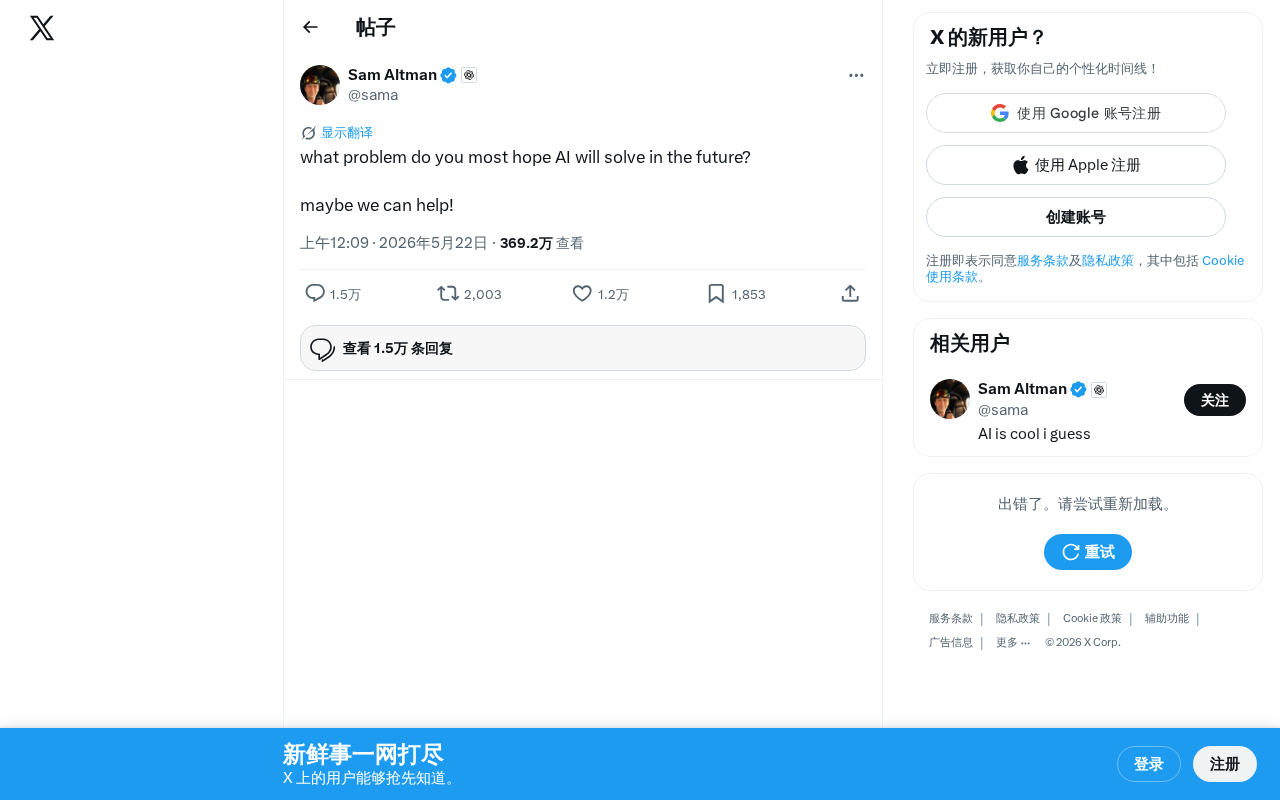 Industry Insights
Industry Insights·2 min
What Problem Do You Most Want AI to Solve? A Deep Reflection on the Future Direction of AI
A simple tweet sparks wide discussion: What do you most want AI to solve? From healthcare to education equity and scientific research, exploring the shift from technology-driven to demand-driven AI.
Read more →