#Group Relative Policy Optimization
2 related articles
·3 min
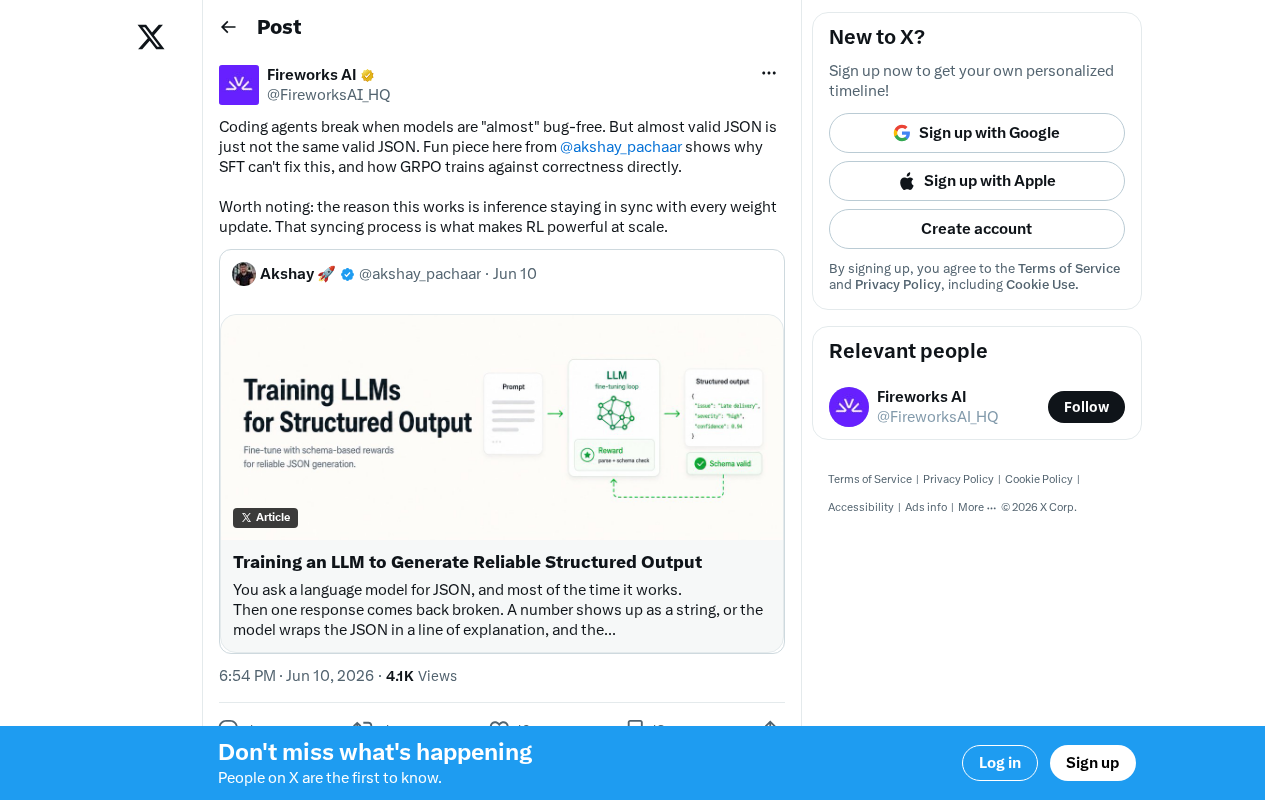
Why SFT Can't Fix the Root Cause of JSON Errors: How GRPO Correctness Training Breaks Through Coding Agent Bottlenecks
Analysis of why SFT can't fix coding agent JSON errors and how GRPO's binary reward signals and synchronized weight updates train directly for correctness.
Read more →
 Deep Dives
Deep Dives·3 min
Complete Guide to LLM Training: Pre-training, SFT Fine-tuning, and Preference Alignment Explained
Complete guide to the three core LLM training stages: pre-training, supervised fine-tuning (SFT), and preference alignment (DPO/PPO), covering LoRA, distillation, quantization, and pruning.
Read more →