Why SFT Can't Fix the Root Cause of JSON Errors: How GRPO Correctness Training Breaks Through Coding Agent Bottlenecks
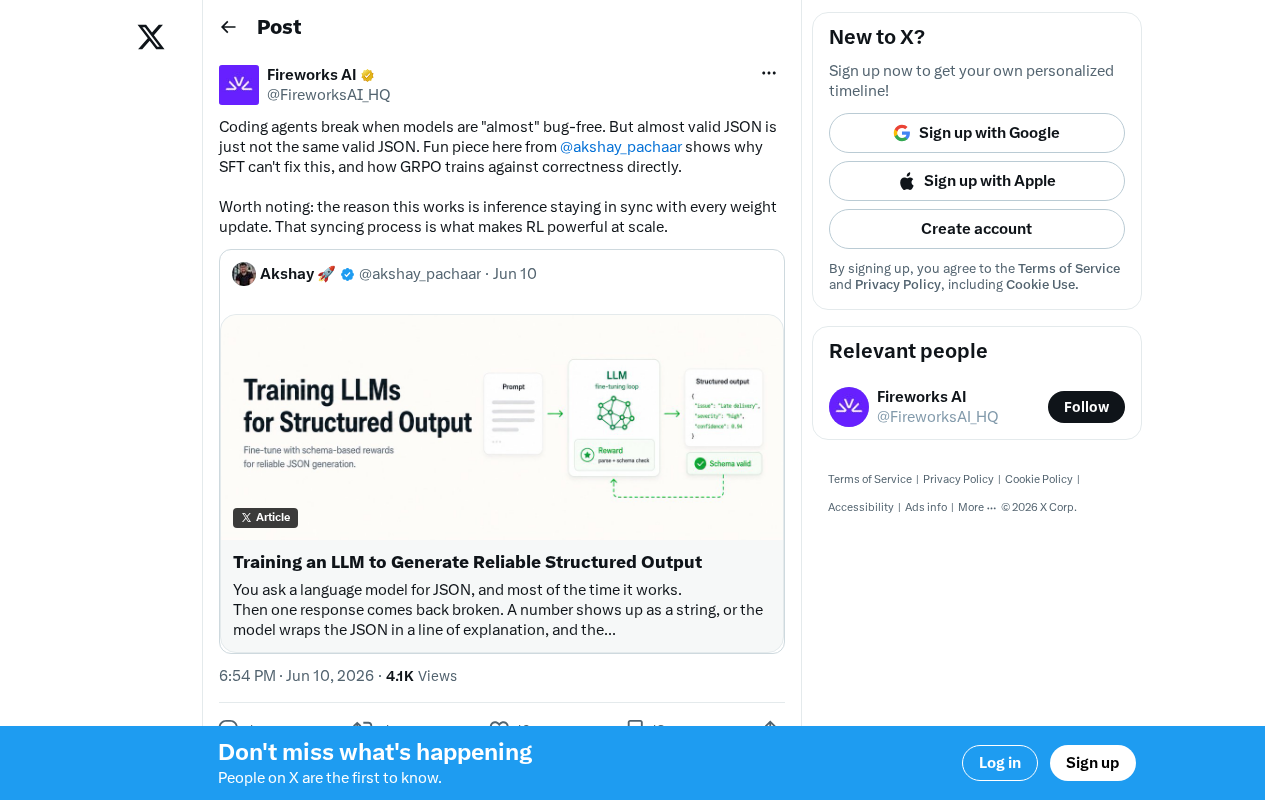
GRPO overcomes SFT's inability to fix JSON errors by training coding agents directly for output correctness.
This article explains why Supervised Fine-Tuning (SFT) fundamentally cannot solve JSON formatting errors in coding agents due to its token-level optimization, and how Group Relative Policy Optimization (GRPO) breaks through this bottleneck. By using binary reward signals, intra-group relative comparisons, and synchronized inference-weight updates, GRPO trains directly for output correctness — enabling the leap from "almost correct" to "completely correct" that production-grade coding agents require.
Introduction: The Fatal Trap of "Almost Correct"
In the world of AI coding agents, there's a seemingly paradoxical yet critically important problem: when a model is "almost" bug-free, the system actually breaks down. As one developer aptly put it — "Almost valid JSON and valid JSON are not the same thing at all."
This insight comes from a discussion of @akshay_pachaar's research, revealing a deep technical issue: why Supervised Fine-Tuning (SFT) fundamentally cannot solve JSON formatting errors in coding agents, while Group Relative Policy Optimization (GRPO) can break through the bottleneck by training directly for correctness.
The "Last Mile" Problem of Coding Agents: Why SFT Can't Fix JSON Errors
"Almost Correct" Is More Dangerous Than "Obviously Wrong"
In software engineering, JSON parsing is a classic binary judgment scenario — it's either completely valid or completely invalid. JSON (JavaScript Object Notation), the most widely used data interchange format on the internet today, follows the strict ECMA-404 standard. Unlike natural language, JSON parsers have zero "fault tolerance" — a missing closing bracket, an extra comma, an unescaped quote — no matter how perfect the other 99% of the content is, the parser will throw an error.
This characteristic is especially critical in the context of coding agents. Modern agent architectures (such as ReAct and Tool-Use patterns) universally rely on JSON format to pass tool invocation instructions, parse API responses, and maintain intermediate state. When an agent's JSON output has formatting errors, not only does the current step fail, but the entire task chain breaks down, and the error is often impossible to recover from automatically.
For coding agents, improving model output accuracy from 95% to 99% doesn't mean system reliability improves by 4 percentage points. In multi-step agent workflows, tiny errors at each step cascade and amplify. If an agent needs to execute 10 steps, 99% accuracy per step means an overall success rate of only about 90% (0.99^10 ≈ 0.904) — unacceptable in production environments. More extremely, if a complex task requires 50 steps, even 99.5% accuracy per step yields an overall success rate of only about 78%.
The Fundamental Flaw of SFT
Supervised Fine-Tuning (SFT) is a key stage in the LLM training pipeline, typically performed after large-scale pretraining. Its core mechanism uses high-quality, human-annotated (instruction, response) data pairs to have the model learn to imitate patterns in the training data. It optimizes the model by minimizing the cross-entropy loss between predicted outputs and labeled answers. While this approach has been proven to significantly improve instruction-following capabilities in milestone projects like InstructGPT and Alpaca, it has fundamental flaws when dealing with JSON format correctness:
- SFT optimizes token-level probability distributions, not the overall structural correctness of the output. The essence of cross-entropy loss is measuring the difference between the predicted token probability distribution and the target token at each position. Its constraint on global sequence structure is "implicit" — the model must inductively learn structural rules like bracket matching and nesting levels from large numbers of examples, rather than being explicitly told about these constraints
- The model may learn to generate text that "looks like" valid JSON, but cannot guarantee structural integrity such as bracket matching and comma placement. This means that even after fine-tuning on massive amounts of correct JSON samples, the model can still generate structurally incomplete outputs in low-probability cases
- For hard requirements like format constraints, the gradient signal for "almost correct" is virtually indistinguishable from "completely correct." From the perspective of cross-entropy loss, the loss difference between an output missing only the final closing curly brace and a completely correct output is negligible, because the predictions for all preceding tokens are identical
Put simply, SFT tells the model "what good output looks like," but doesn't tell it "what consequences incomplete output leads to." This is the fundamental reason why SFT cannot fix JSON errors at their root.
How GRPO Trains Directly for Correctness
Core Principles of GRPO
GRPO (Group Relative Policy Optimization) is a reinforcement learning method proposed and popularized by the DeepSeek team in their DeepSeek-Math and DeepSeek-R1 series of work. It represents an important simplification of the traditional RLHF (Reinforcement Learning from Human Feedback) pipeline. In the classic PPO (Proximal Policy Optimization) approach, a separate value function (Critic model) must be trained to estimate state values, which not only increases computational overhead but also introduces value estimation bias. GRPO's innovation lies in completely removing the Critic model, instead generating a group of candidate outputs for the same prompt, then using relative ranking and normalization of reward scores within the group to replace the value baseline.
GRPO's core idea is: instead of relying on imitation learning, directly use output correctness as a reward signal to optimize the model's policy. Compared to traditional RL methods and SFT, GRPO has three key advantages in solving JSON formatting errors:
- Binary reward signal: JSON is either valid or invalid — this clear reward function is naturally suited for reinforcement learning training. No complex reward model design is needed; a simple JSON parser can provide a perfect reward signal — 1 point for successful parsing, 0 for failure
- Intra-group relative comparison: By comparing the quality of different outputs within the same group, the model can precisely learn to distinguish "almost correct" from "completely correct." For example, when some JSON outputs in a group are valid and others are invalid, the model can learn the specific patterns that cause failure from the comparison
- End-to-end optimization: Directly optimizes the final objective (output correctness) rather than an intermediate proxy objective (token probabilities). This design significantly reduces training memory and computational requirements while maintaining the effectiveness of policy optimization
Synchronization of Inference and Weight Updates: The Key Mechanism for Scale
The reason GRPO can deliver power at scale lies in keeping the inference process synchronized with each weight update.
Specifically, during training, the model receives reward feedback after each output generation (inference), then immediately updates its weights. The next time it generates output, the model is already reasoning based on the latest weights. This tight feedback loop ensures:
- The model doesn't generate training samples based on an outdated policy
- Every improvement is immediately reflected in subsequent output quality
- Avoids the distribution shift problem common in offline RL
Distribution shift is a classic challenge in reinforcement learning, referring to the discrepancy between the data distribution used for training and the data distribution during actual model execution. In offline reinforcement learning, training data is generated by older versions of the policy, but model weights are continuously updated during training, causing a deviation between the current policy and the policy that generated the training data. This deviation causes the model to perform well on training data but degrade in performance during actual inference. GRPO's online (on-policy) training paradigm — regenerating samples with the latest model immediately after each weight update — fundamentally avoids this problem, ensuring that training signals always reflect the model's current true capability level.
This mechanism enables GRPO to continuously approach 100% JSON format correctness, rather than plateauing at the "high probability of correctness" level that SFT can achieve.
Practical Implications of GRPO for AI Programming Tool Development
The Technical Path from "Functional" to "Reliable"
The core challenge facing mainstream AI coding assistants today isn't "can it generate code" but "can the generated code run directly." AI coding tools are undergoing a paradigm shift from "copilot" to "autopilot." Early GitHub Copilot primarily provided line-level or function-level code completion suggestions, with developers remaining the decision-makers. The new generation of coding agents — such as Devin, OpenAI Codex Agent, Claude Code, and others — attempt to autonomously complete the entire development workflow from requirement understanding, code writing, and test execution to bug fixing. This increase in autonomy demands exponentially higher output reliability: when humans no longer review every output line by line, any formatting error, tool call failure, or state management anomaly can cause the agent to fall into infinite loops or produce incorrect results.
GRPO's methodology provides a clear technical path for this problem:
- Structured output scenarios: For scenarios with strict format requirements such as JSON, API call formats, and configuration files, RL training based on GRPO can significantly improve reliability. The common characteristic of these scenarios is the existence of clear, automatically verifiable correctness criteria, making them naturally suited for constructing binary reward functions
- Tool call correctness: Agents need to generate precise function call parameters — this is also an "all or nothing" correctness problem, suitable for optimization with binary reward signals. In Function Calling scenarios, parameter type errors, missing required fields, and out-of-range enum values all cause call failures
- Multi-step reasoning chains: In complex coding tasks, the reliability of each step directly determines the overall task success rate, and GRPO's end-to-end optimization has a natural advantage here. Combined with the probability analysis above, improving single-step reliability from 99% to 99.9% means that for a 50-step task, the overall success rate jumps from 78% to 95%
Industry Direction
This research direction confirms an important trend in the AI industry: shifting from pursuing general model capabilities to optimizing absolute reliability in specific scenarios. For coding agents, a model that is 100% reliable on structured output is far more practically valuable than one that is "almost always correct." This also explains why more and more teams are introducing an RL stage after SFT — not to make the model "smarter," but to make it "absolutely reliable" on critical constraints. In verifiable tasks such as mathematical reasoning and code generation, GRPO has been proven to continuously improve model performance on strict correctness metrics, and this methodology is moving from research into engineering practice.
Conclusion
An "almost bug-free" coding agent can actually be more dangerous in practice than an "obviously buggy" one, because it creates a false sense of security. SFT, constrained by its token-level optimization mechanism, fundamentally cannot solve binary judgment problems like JSON format correctness — it optimizes the probability distribution at each position, not the global structural validity of the output. GRPO, by making correctness the direct optimization target and coupling it with real-time synchronization of inference and weight updates (avoiding distribution shift), provides an effective technical solution for the "last mile" problem of coding agents.
As AI coding tools evolve from assistive suggestions to autonomous execution — from Copilot-style code completion to Devin-style autonomous development — this reinforcement learning-based correctness training approach will become the core technical path for building reliable coding agents. Correctness is no longer a "best effort" soft target, but a hard threshold for whether a system can be deployed to production.
Related articles
Mistral Le Chat Image Generation Review: Can It Replace Fable?
Mistral AI launches image generation in Le Chat, dubbed Le Chaton Fat. We analyze its capabilities, compare it with Fable, and explore the trend of AI chat platforms integrating image generation.
Testing DeepSeek's Safety Mechanisms: Multiple Jailbreak Attempts Successfully Blocked
An overseas security blogger systematically tested DeepSeek's jailbreak resistance using direct requests, rephrased prompts, and varied strategies. Results show robust intent recognition, consistent blocking, and context-aware safety mechanisms.
A Middle Schooler with Zero Coding Skills Built a Story-Driven Game with AI: Creativity Unshackled from Technical Barriers
A middle schooler with no coding experience used AI to build an interactive story game with branching choices and surreal alien adventures. We explore what this means for creative democratization.