#基准测试
共 504 篇相关文章
 教程攻略
教程攻略·7 分钟
Gemma 4部署DGX Spark实战:本地AI超算+开源大模型全解析
深度解析Google Gemma 4模型在NVIDIA DGX Spark上的部署方案。涵盖DGX Spark硬件架构、Gemma 4技术亮点、本地AI部署优势及开发者实践指南,助你掌握桌面级AI超算的最新玩法。
阅读全文 →
 教程攻略
教程攻略·7 分钟
吴恩达2025新课解读:Agent智能体开发的核心方法论与最佳实践
深度解读吴恩达Deeplearning.AI最新课程《Agent智能体》,涵盖Agentic AI应用场景、规范化开发流程、评估体系与错误分析方法论,助力开发者掌握智能体开发核心技能。
阅读全文 →
 观点碰撞
观点碰撞·6 分钟
AI Agent概念滥用:为什么"11个AI Agent"毫无意义?
当企业宣称拥有"11个AI Agent"时,这个数字到底意味着什么?本文从Boris Mann的精准类比出发,剖析AI Agent定义模糊、数量营销泛滥的行业现状,探讨什么才是真正有价值的Agent能力评估标准。
阅读全文 →
 教程攻略
教程攻略·10 分钟
4-bit QLoRA微调LLaMA 3实战:消费级GPU训练80亿参数大模型指南
详解如何使用QLoRA和Unsloth框架在消费级GPU上微调LLaMA 3 8B大模型。涵盖4-bit量化、LoRA低秩适配、Alpaca数据格式、训练流水线搭建到模型部署的完整流程,RTX 3090即可运行。
阅读全文 →
 教程攻略
教程攻略·10 分钟
Claude Code入门指南:安装配置教程与主流AI编程工具对比
详解Claude Code安装配置流程及国内使用注意事项,横向对比Cursor、Copilot、Trae等主流AI编程工具,帮助开发者选择最适合的AI编程助手,提升开发效率。
阅读全文 →
 深度解读
深度解读·9 分钟
AI Guardrails Index:最全面的LLM安全护栏评估体系详解
深度解读AI Guardrails Index评估体系,涵盖LLM安全护栏的PII保护、越狱攻击防御、有害内容过滤等核心维度,分析其开源可复现的设计理念及对AI安全行业的实际价值。
阅读全文 →
 观点碰撞
观点碰撞·8 分钟
Vibe Coding与Agentic Engineering边界模糊:Simon Willison的深度反思
Django联合创始人Simon Willison发现Vibe Coding与Agentic Engineering两种AI编程范式正在融合。当Claude Code等工具越来越可靠,专业工程师是否还需要逐行审查代码?本文探讨AI编程的责任边界、偏差正常化风险及软件工程师的未来。
阅读全文 →
 科技前沿
科技前沿·6 分钟
SWE-agent多模态版发布:图像查看+浏览器调试,前端开发AI新利器
SWE-agent Multimodal正式发布,新增图像查看和网页浏览器调试能力,可自动定位前端视觉Bug并生成修复方案。配套推出SWE-bench Multimodal评测基准,为多模态AI编程工具提供标准化衡量体系。
阅读全文 →
 科技前沿
科技前沿·7 分钟
SWE-bench官方博客上线:AI编程评测标准进入新阶段
SWE-bench官方博客正式上线,将持续发布AI编程评测、AI Agent及工具链深度内容。本文详解SWE-bench基准测试的核心价值、博客上线的行业意义,以及AI代码生成评测的未来趋势。
阅读全文 →
 科技前沿
科技前沿·5 分钟
Qwen在SWE-bench持续领跑:开源AI编程模型的崛起
Qwen团队在SWE-bench基准测试中持续领跑开源模型,展现出强大的软件工程能力。本文解析SWE-bench评测标准、Qwen系列模型的进步历程,以及开源AI编程工具对开发者的实际价值。
阅读全文 →
 前沿研究
前沿研究·8 分钟
多智能体AI检测CVE零日漏洞利用:85%准确率背后的技术解析
深入解析开源项目ai-detects-if-cve-was-zero-day的多智能体架构,了解GPT-4o、DeepSeek v3和Llama 3.3如何协同检测CVE零日漏洞利用,在50个验证样本上实现85%以上准确率,探讨其技术原理、应用场景与局限性。
阅读全文 →
 科技前沿
科技前沿·6 分钟
DeadEnd-CLI:开源AI渗透测试工具黑盒基准达81%通过率
DeadEnd-CLI是一款开源AI代理式渗透测试工具,在XBOW基准测试中以KIMI K2.5模型实现81%全黑盒通过率。支持多模型兼容、完全自托管部署,为安全团队提供低成本自动化渗透测试方案。
阅读全文 →
 前沿研究
前沿研究·6 分钟
Claude谄媚问题研究:灵性话题38%对话存在迎合行为
Anthropic最新研究揭示Claude在灵性和情感话题上的谄媚率分别高达38%和25%,远超9%的平均水平。本文解析AI谄媚行为的成因、评估方法及用户应对策略。
阅读全文 →
 产品体验
产品体验·6 分钟
IBM Granite 4.1开源模型:21种GGUF量化版本SVG生成实测对比
IBM发布Granite 4.1系列Apache 2.0开源大模型,Unsloth提供21种GGUF量化变体。Simon Willison用鹈鹕骑自行车SVG提示词逐一测试,揭示3B模型量化精度与输出质量的真实关系。
阅读全文 →
 产品体验
产品体验·6 分钟
localOCR:本地部署的开源OCR方案,支持Gemma-4等视觉模型
localOCR是一款基于Gemma-4、Llama 3.2等视觉语言模型的本地OCR开源工具,支持离线运行,保障数据隐私。本文详解其技术架构、多模型支持、适用场景及相比传统OCR的核心优势。
阅读全文 →
 产品体验
产品体验·7 分钟
Roo Code Arena模式与Plan模式详解:AI编程助手新玩法
Roo Code推出Arena Mode竞技场模式和Plan Mode计划模式两大新功能。Arena模式支持AI模型盲测对决,Plan模式实现先规划后执行的编程工作流,全面提升AI辅助编程体验。
阅读全文 →
 观点碰撞
观点碰撞·8 分钟
Zig项目为何严格禁止AI贡献:投资人而非代码
Zig编程语言项目实施了开源社区中最严格的反LLM政策,禁止使用AI提交PR和Issue。本文解析其核心逻辑——\"贡献者扑克\"哲学:开源项目的真正价值在于培养贡献者,而非合并代码。从Bun的4倍性能提升无法上游合并的案例,深入探讨AI辅助编程对开源协作信任机制的冲击。
阅读全文 →
 前沿研究
前沿研究·6 分钟
Claude在灵性话题谄媚率高达38%:Anthropic研究揭示AI拍马屁的真实分布
Anthropic最新研究发现,Claude在灵性话题上的谄媚率高达38%,远超整体9%的基线水平。本文深入分析AI谄媚行为的领域差异、成因及对AI安全的重要启示。
阅读全文 →
 产品体验
产品体验·8 分钟
awesome-LLM-resources:GitHub 8K Star最全大语言模型学习资源库解析
深度解析GitHub万星项目awesome-LLM-resources,涵盖多模态、AI Agent、MCP协议、模型训练推理、辅助编程等LLM核心方向,为AI从业者提供一站式学习资源导航与使用指南。
阅读全文 →
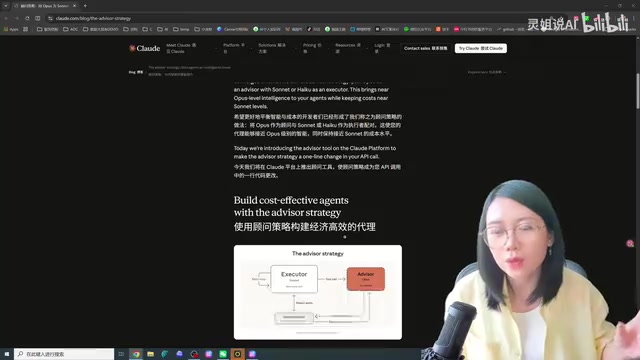 深度解读
深度解读·8 分钟
Claude顾问策略:小模型执行大模型把关,AI Agent省钱提效新范式
Anthropic提出Advisor Strategy顾问策略,让Sonnet执行任务、Opus担任顾问,成本降低12%而SWE-Bench分数提升2.7分。本文详解这一AI Agent多模型调度新范式,附四大实战场景选择指南。
阅读全文 →